I’m interested by citations that state that the datasets obtained by flicker photometry are broken. You link Stockman but the cone fundamentals are tightly coupled to the CMFs by a mere linear relationship, if the datasets were so fundamentally broken as you imply it, you would not be able to do that at all.
The goal of flicker photometry is to frequently derive “equivalence” in brightness / relative lightness of chromatic stimulus.
Under that basic definition, if the testing does not actually model what it is attempting to measure, I would say that’s pretty broken. See how almost every CAM fails miserably at this basic task.
Luminance as a metric of observer stimulus response connected to observer sensation, is only more accurate as it approaches achromatic. Seems to be a bit of a tautological problem.
1 Like
I still don’t see any citation, just an opinion (which is fine in itself) ![]()
The purpose of heterochromatic flicker photometry is to measure the spectral sensitivity of the HVS. The datasets produces by this method are verified by other approaches, for example electro-retinograms as shown by Aiba, Alpern and Maaseidvaag (1967):
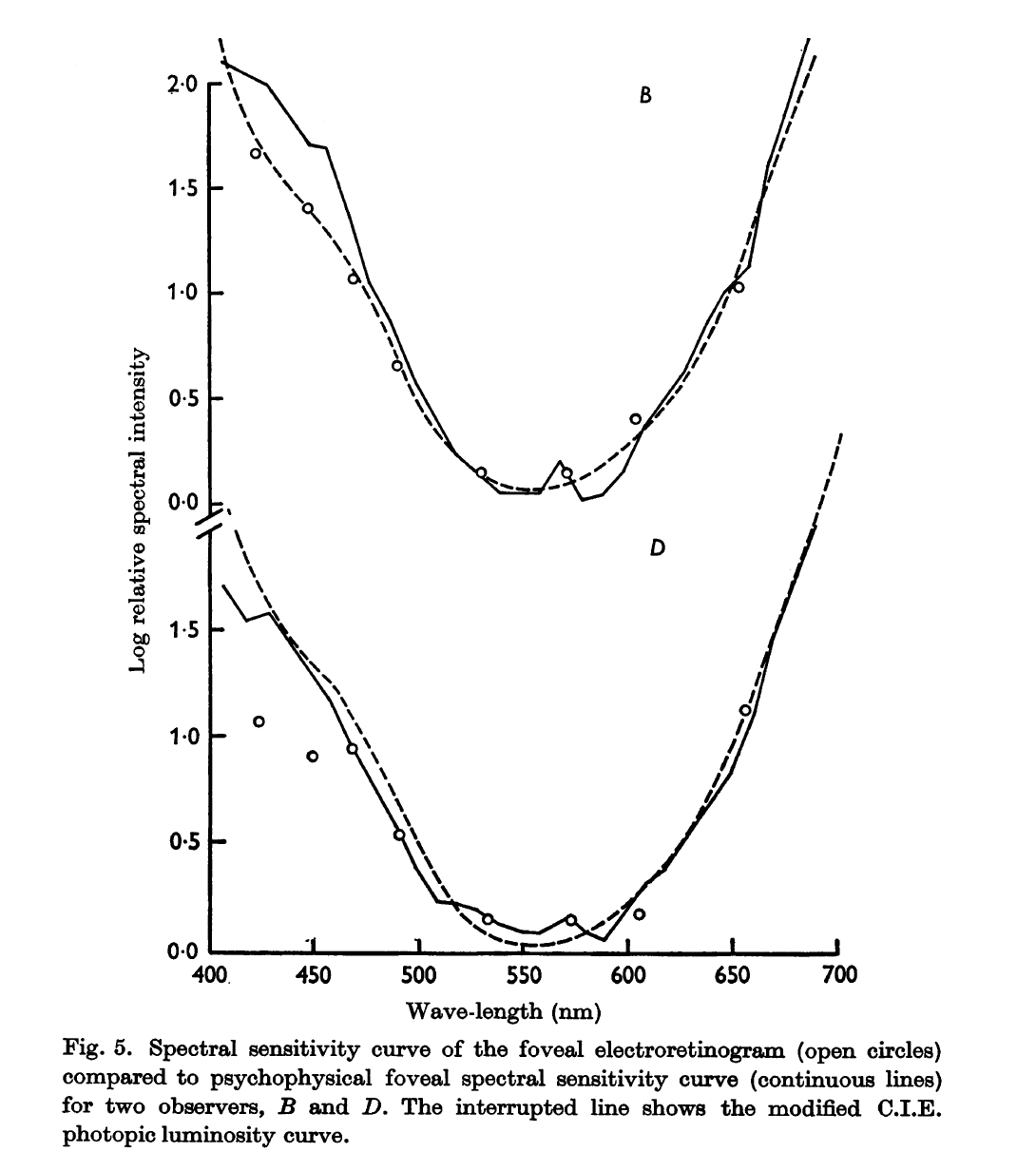
If one take two radiometrically matching colours stimulus, and scale them so that they photometrically match, they will certainly appear much closer in apparent brightness, but not necessarily perceived to match, which, indeed, hints at some more complex mechanisms happening in the eye and cortex.
Does it means that the datasets broken? Certainly not! It means that we are far from having all the answers. Heterochromatic brightness matching experiments show that it is complex business, e.g. CIE 1988. To quote Conway et al. (2017):
We can now predict, with reasonable precision, how the three classes of cones react to any given physical stimulus. Yet many mysteries about how that code leads to the perception of color remain.
I was under the impression that Frederic Ives invented the method to deal with the subject of this discussion; brightness matching, and derive luminous efficacy from.
“Spectral sensitivity” could be considered to have been derived a number of ways, not limited to even the Wright and Guild split field experiments. Fair?
At any rate, specifically on the subject of equivalent chromatic brightness, flicker photometry bombs out. I’m not sure why someone would have an issue with that statement, but here we are.
Again, flicker photometry fails here, or in the most generous interpretation, only relates to a partial component at work.
The point I was trying to make was that, at least as far as L*’s relationship to (bogus flicker frequency derived) luminance, is that it is at least feasible to be able to move fluidly back and forth between an observer sensation appearance model and display colourimetry.
As pointed out (and you just confirmed in the above quote), the heterochromatic flicker photometry derived datasets, are verified by many types of experimentation and they produce, for practical purposes, the spectral sensitivity of the HVS, i.e. sensitivity to electro-magnetic as a function of wavelength. It is one of the basis on which the entire field of basic colorimetry is built on and allows for example, among many things, display calibration.
The failure of “knowledge of the spectral sensitivity of the HVS only” to explain our vision is a given. No one is contesting that, quite the opposite and this was recognised many decades ago, nothing really new here. Advanced colorimetry would not exist if everything was explained by strict sensitivity to radiant energy and we would not have that conversation in the first place.
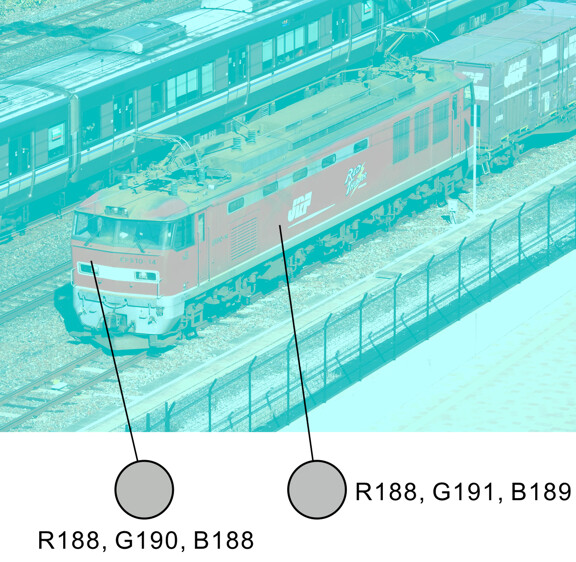
Almost all of our current models are not even accounting for spatial induction, one simply has to look at this image to appreciate how gargantuan the task is:

“Illusory Red Thunder”
The electric locomotive appears to be reddish, though the pixel are not.
Copyright Akiyoshi Kitaoka 2020 (January 13)
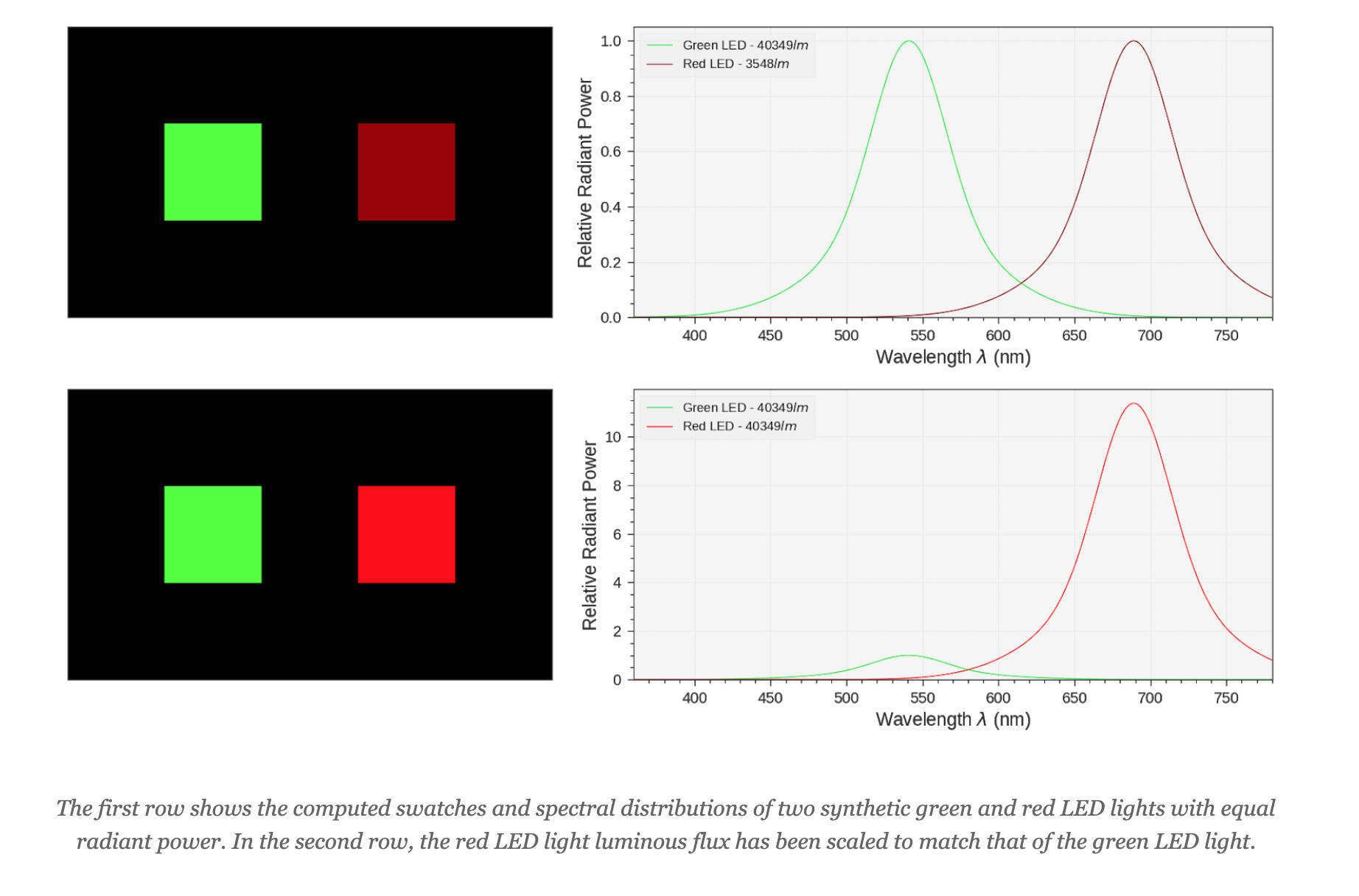
What I’m contesting however are your claims here (or Twitter) that the datasets themselves are fundamentally broken while colour matching experiments, heterochromatic flicker photometry and ERG produce agreeing data.
I’m certainly willing to change my opinion on that but it needs to come with sourced research.
From Cinematic Color 2, quoting quotes ![]()
Fairchild (2013) references a citation from Wyszecki (1973) describing basic colorimetry first:
Colorimetry, in its strict sense, is a tool used to making a prediction on whether two lights (visual stimuli) of different spectral power distributions will match in color for certain given conditions of observation. The prediction is made by determining the tristimulus values of the two visual stimuli. If the tristimulus values of a stimulus are identical to those of the other stimulus, a color match will be observed by an average observer with normal color vision.
And then advanced colorimetry:
Colorimetry in its broader sense includes methods of assessing the appearance of color stimuli presented to the observer in complicated surroundings as they may occur in everyday life. This is considered the ultimate goal of colorimetry, but because of its enormous complexity, this goal is far from being reached. On the other hand, certain more restricted aspects of the overall problem of predicting color appearance of stimuli seem somewhat less elusive. The outstanding examples are the measurement of color differences, whiteness, and chromatic adaptation. Though these problems are still essentially unresolved, the developments in these areas are of considerable interest and practical importance.
Couldn’t disagree more. Very, very few folks discuss g0, Macadam moments, Evans etc. in the discussion of image formation. But if that’s your view, so be it.
Why obfuscate something with additional complexities when more basic and profound issues are missing in our discussions of image formation?
Escaping values becoming device dependent and the complete bed poop of tonality theory and application in our current options on image formation strike me as far larger low hanging fruit. Hence why focusing on higher priority items as @paulgdpr has hinted seems far more rewarding that worrying about layers of nuance on top.
The basics idea of measuring brightness of chroma mixtures does not, in any way, work with flicker photometry. End. Nothing more to discuss.
If the measurement and resulting metric does not work, it isn’t worth talking about as “valid”.
Someone might want to say they are measuring human intellect using a cloth tape measure and that their measurement of human heads are consistent. The veracity of the claim is what is at issue.
I’ve spent a heck of a lot of time drilling into this subject and the only conclusion I can arrive at is that flicker photometry and resulting luminance is a misshapen bowl of, if we are generous, half baked nonsense with respect to building atop of with specific attention to the subject of relative brightness / lightness at hand in this thread. Such efforts must go further to potentially crack the specific nut Paul appears to be citing. As is potentially verifiable with some experimental testing on imagery.
Is there some potential nuance in the discussion for binding the need against known luminance? Absolutely! But then let’s make that part of the discussion.
If you would like to keep banging that drum, please explain what is gained. I’ve outlined the problems with flicker photometry based models and metrics as best as I am able, and I believe the issues are extremely pertinent to this specific discussion.
I can’t see how belaboring a rather rehashed point is in the service of resolving some critical issues in image formation. Again, specifically addressing the subject matter here.
The rest of us will try to move forward.
You are, again, c.f. Daniele above, putting words in someone else mouth. I said that the problems you are referring to are well known and have been documented for decades. As you reference Evans, he did spend a lot of time on those aspects, not last year or last decade but from the end of the 50s, i.e. ~60 years ago!
Because it is as soon as stimuli are not seen in isolation anymore that basic colorimetry starts to tank. Appropriately staying with Evans for a little more, I unfortunately don’t have The Perception of Color but there is a review from Heckaman and Fairchild (2004) that has a relevant quote:
Evans sums up the central thesis of his book. The fact that all colors can be matched by mixtures of three others and the establishment of three psychophysical attributes for such a match, the assumption since the time of Hemholtz has been that there must only be three perceptual attributes of color. In Evans’ own words, “ … the three-dimensional requirement for perception is logical only if it is also assumed that the appearance of the stimulus is controlled entirely by the stimulus itself. And this is true only when the stimulus is itself the only thing affecting the eye, that is, the isolated stimulus case.”
As we are somehow doing circles here, and given your experience on the subject, you should be able to produce a clear and sourced write-up demonstrating how the datasets are fundamentally broken, proposal on how to fix them and publish it on a peer-reviewed journal (or pre-pub like arXiv). Until this is done and your publication can been reviewed, it will be very hard to engage with you on this topic because there is very little substance to talk about.
1 Like
In colour science. Please show me this furious discussion around generalized brightness in image formation? I also have been following the threads for a while and I promise you that very few folks were even chasing MacAdam moments, Sinden, Evans, and HKE around here?
Why on earth would anyone care to do this when the results are glaringly obvious?
How on earth does wasting one’s time on writing papers on a subject that can be visibly demonstrated in a DCC in five minutes help chase image formation ideas? Or is the point to spin wheels looping over rubbish that doesn’t matter that is clearly self evident since Sinden in 1920?
wow, this escalated quickly 
This should be its own discussion really. (Maybe someone can split of the last comments and generate a new discussion)
simplicity
I can see the argument that during brainstorming you should not constrain yourself too much, you can later optimise. But some approaches permit themselves if you know that the delivery needs to be computed on the GPU with minimal footprint.
experiments and models
I was not directly referring to flicker photometry, but to a more general “issue” in vision science.
(about flicker photometry I have more questions than opinions)
Experiments:
In general, we put too much “weight” into certain models and use them for applications that were never targeted in the initial experiments. Let’s take an example: CIE XYZ:
CIE XYZ’s only purpose is to predict metameric pairs, nothing more; and this only in a very narrow setup which is: two stimuli in a 2 degree (or alter 10 degree) field of view - without the presents of any other stimulus. CIE XYZ does not tell us anything about equidistance, hues, saturation or any other perceptional scales.
Nor does it say that if you lower/raise one dimension (for example luminance) other attributes stay constant.
Another example is PQ:
It is designed to predict JNDs, which makes sense for encoding - if you encode always below the JND threshold you never get banding. (and even here, this is only true for b/w images, I believe).
But sometimes we expect too much from those models or we use them in different contexts and assume some magic to happen.
Models:
Sometimes the choice of model is also questionable.
For example, most colour difference models take the form of Matrix - 1D LUT - Matrix.
You can find some great explanations about why this model is based on physiological reasoning.
But I am wondering if the choice of form is not just due to hardware constraints. Most YCbCr hardware out there run as Matrix - 1D LUT - Matrix implementation. If you stick to the same general model you have the chance to update existing hardware with your “new” models.
Complex stimuli
And then we have the issue that you cannot build a coherent vision science model for complex stimuli.
So we are fundamentally doomed here for some time.
One thing is clear though, with “per pixel” operation there is only so much we can do.
5 Likes
Thank you! This is exactly the problem, akin to try using a hammer instead of a screw driver when assembling furniture ![]() It does not invalidate usage of a hammer when you need one. What would have been useful, instead of blaming issues on fundamental datasets brokenness is discussing whether building colour appearance and perception on top of the spectral sensitivity of the HVS is appropriate or not.
It does not invalidate usage of a hammer when you need one. What would have been useful, instead of blaming issues on fundamental datasets brokenness is discussing whether building colour appearance and perception on top of the spectral sensitivity of the HVS is appropriate or not.
My take on it is as follows: The HVS spectral sensitivity being known and verified (yes, the datasets are generally correct and cross-verified for practical purposes), it makes sense to build on top of that because it is the first step into higher level functions processing. Given the absence of alternative well researched approaches and that CAMs, amidst of their incompleteness, are able to produce reasonable predictions for certain applications, I would certainly look at them for what we are trying to do here.
Agreed, that I linked Akiyoshi Kitaoka image above was not a mere coincidence.