Hello, thanks Nick for the reply and I also wanted to share some updates about “my little experiment” on the Miro board.
I think we were able yesterday to move forward with a more representative diagram from Daniele’s idea. Here is my thought process (based on the two last meetings’ notes) :
- The fork should not be at the LMT.
- There can only be one rendering intent.
- Display transforms should be as pure as they can be (matrix + inverted eotf).
Based on all these assumptions, the only solution I could come up with was a three-stage process.
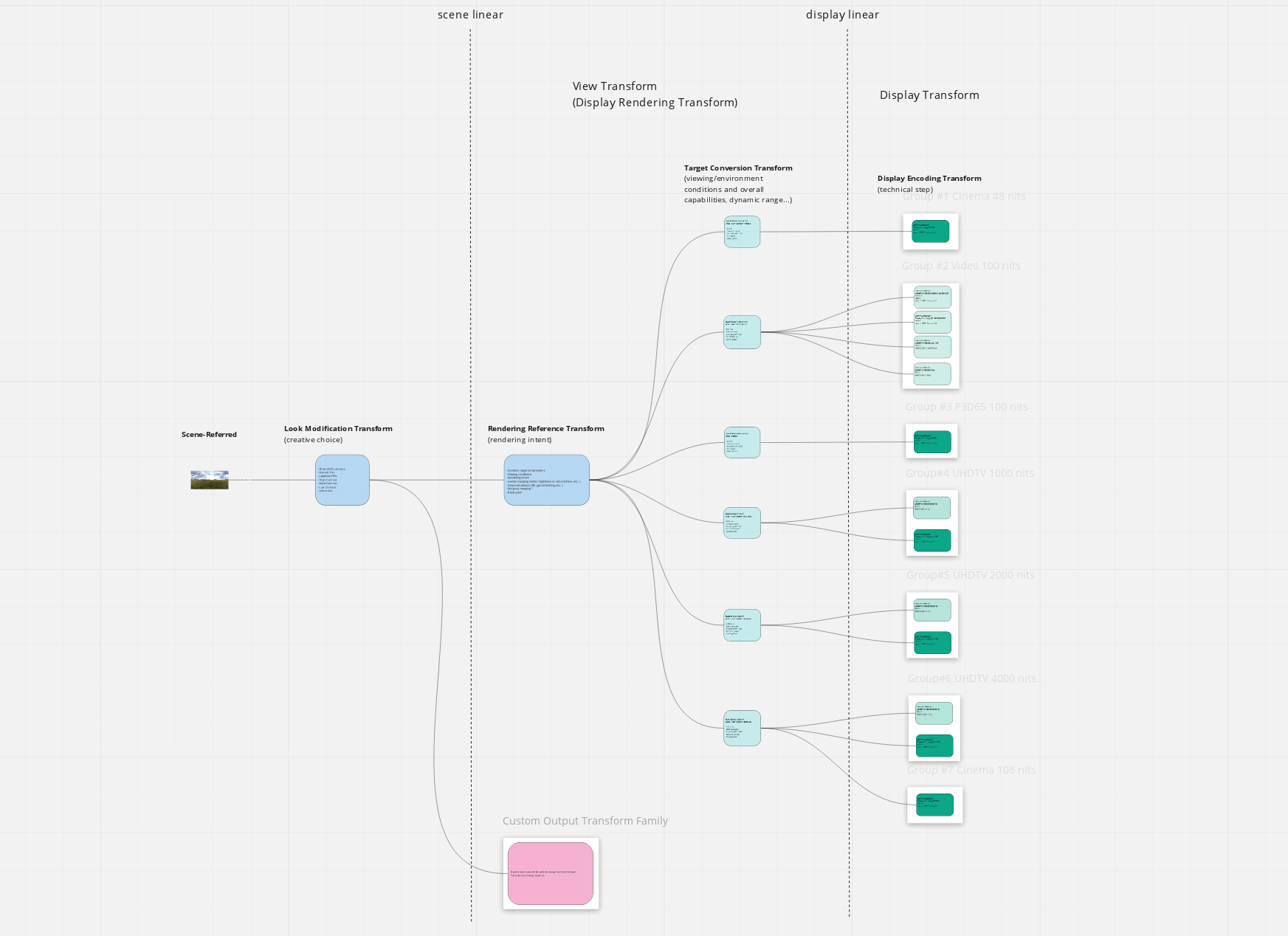
I am clearly not the most adequate person to do that but I have time on my hands and I find the exercise particularly stimulating. ![]() Interestingly enough, there was a conversation on Slack with some very interesting points that I think are worth sharing with the VWG.
Interestingly enough, there was a conversation on Slack with some very interesting points that I think are worth sharing with the VWG.
First point was about similarities between Daniele’s idea and OCIO2 :
there’s a lot of conceptual overlap between some of the stuff Daniele demonstrated and some of the OCIO-2 architecture / design. (basically, from left to right, ColorSpaces —> Looks —> ViewTransforms —> DisplayColorSpaces)
And the conversation even got to a more interesting point :
There’s a super obscure ACES technical bulletin […] — TB-2014-013 — that provides an alternate “block diagram” conceptualization. It divides the ODT into two blocks: the Target Conversion Transform (TCT) and the Display Encoding Transform (DET). The DET is the “on-the-wire” stuff (ocio DisplayColorSpaces); and the RRT + TCT make up what OCIO calls a ViewTransform (for the ACES family, in this case)
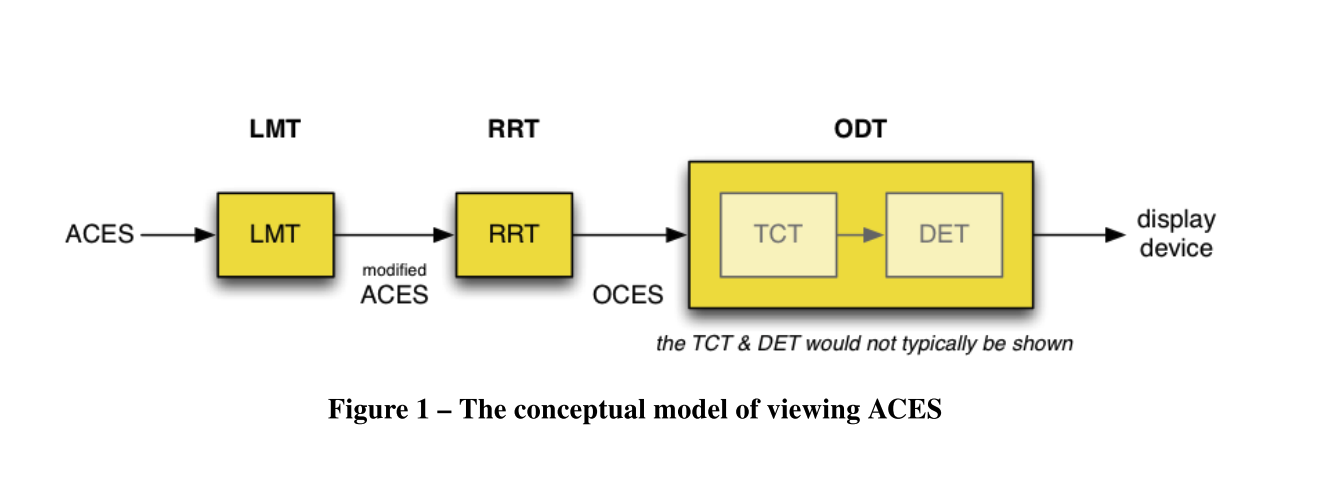

I think it is a good thing that OCIO2, ACES2 and even BaseLight go to the same direction. It makes sense to me. So I have tried to adopt this terminology on the Miro board, because it is really helping the conversation I think :
- View Transform is made of Rendering Reference Transform (RRT) and Target Conversion Transform (TCT).
- Display Encoding Transform (DET) is the last step of the chain.
Finally, some wise words from Daniele :
I think this abstract discussion about system overall design is important before we jump into the details of one particular implementation. Keeping it abstract at this point is key. The less you specify explicitly and the longer you stay on the mechanic side the more general your system might be. For example my proposal would also still be true if we decide at a later stage to roll in spatial or temporal processing per viewing condition.
Thanks Zach, Sean, Nick, Carol and Daniele !
Regards,
Chris