The recording and notes from meeting #184 are now available.
If this was the last meeting, congrats to everyone involved !
Just a suggestion, it might take some time before all DCCs upgrade to OCIO 2.4.2, so maybe having a temp OCIO config (based on LUTs) or the blink node updated to the latest and greatest CTL would be useful.
But again, what a journey it has been !
4 Likes
I am also looking for a temp OCIO v1.x or v2.0 LUT-based config based on the latest ACES 2.0! Has anyone thrown something together? (Looking mostly for the DRT I don’t need the other features in the full config).
Thanks!
The v60 OCIO config here is not quite the final release version, but it’s very close. Quite possibly the imprecision from LUT interpolation may be more significant than the changes between v60 and the release.
Just to avoid any possible confusion, I’d like to elaborate on Nick’s post. The official ACES 2.0 config release from the OCIO ACES config working group is actually available here:
However, those configs are designed for the latest version of the OCIO library (2.4.2), which implements the Output Transforms as shaders rather than LUTs for increased accuracy.
The config link Nick provided is, I believe, the most recent LUT-based config. That is what Conlen was asking for, but please keep in mind that it is not the “official” version.
Doug Walker
Autodesk / OCIO TSC
2 Likes
I was testing this and came across some surprising behavior. I expected the “formula based” shaders would have significantly better precision but this does not seem to be the case. I’ll outline a test case below.
The goal is to test the precision of the “formula-based” shader transforms in OCIO v2.x. First we need a “ground truth” to test against. I’ll use the following setup in Nuke.
- Start from a linear gradient ramp from 0-1
- Using a formula based expression node implementation of some log curve (We’ll use ACEScct here), convert from log2lin and then lin2log.
- This is our “reference” to compare against, a 32 bit float precision implementation.
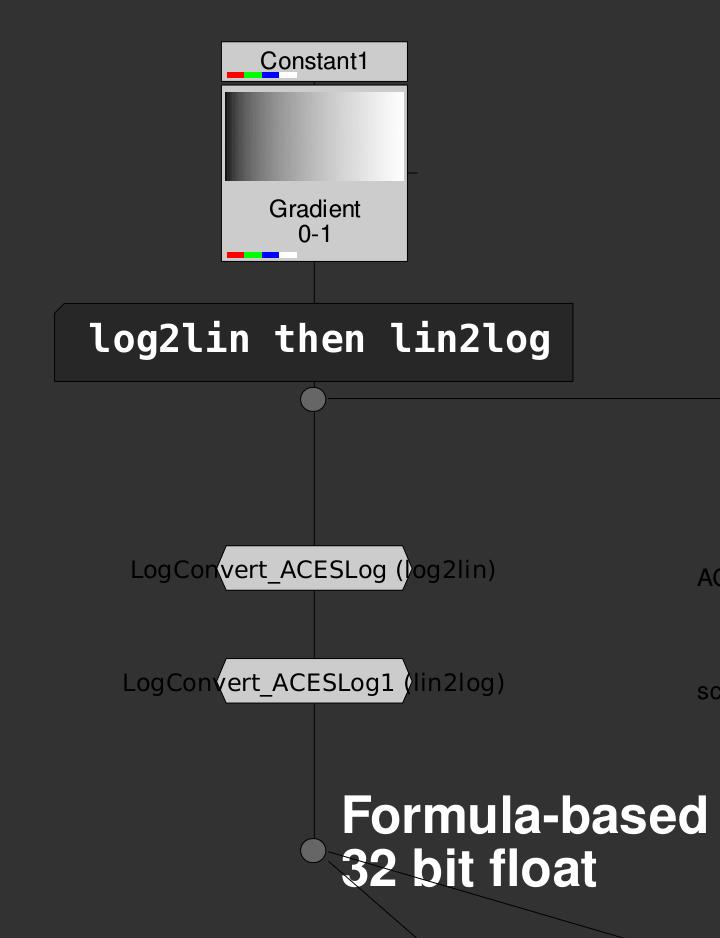
Next we need something to compare against. Let’s first use the trusty old spi1d approach. I’ll use a spi1d LUT that I generated with 8192 sample points, ranging from -0.15 to +1.2. Here is the spi1d lut with the file extension renamed to “.txt” so I can upload it: oetf_acescct_to_linear.spi1d.txt (101.2 KB)
We do the same conversion and do a difference with the “reference”, and multiply up by 1,000,000 so we can visually see the error.

Okay, not perfect, but to be expected with a 1d LUT approach! Let’s see how much better the formula-based shader approach is in OCIO v2! Should be a big improvement right?

That’s weird. It seems that below ~0.14 it’s an improvement, but everything above is much worse (about 18x worse in this particular case, measuring by the average pixel value over the whole image). What’s going on here?
I’ve verified the same behavior with the LogCameraTransform so it’s not just the BuiltinTransform, and also in other software that uses the OCIO Library like Gaffer.
Here is the Nuke script that generated these test images.
aces_ocio_test.nk (31.3 KB)
I’m not seeing what you’re showing there @jedsmith. But it’s possible I have corrupted your script while linking to my local copy of the OCIO config.
I am confused about why you have an OCIODisplay node downstream of the Difference node. What is the purpose of that?
Nuke do not use the shader implementation for node in the graph I believe, what you are probably seeing is the result of CPU optimization applied by OCIO that trade accuracy for speed. In particular there a fast SSE approximation for log/exp/pow, you can disable it by setting this environment variable before launching Nuke: export OCIO_OPTIMIZATION_FLAGS=“196886467”
Maybe you should compare against the original gradient as well if you are just applying a roundtrip with various methods? But I didn’t look close enough at the whole script.
Thanks @remia for the help! Unfortunately, setting OCIO_OPTIMIZATION_FLAGS="196886467" does not seem to change the behavior at all. (Quite the obscure flag value there… I guess I shouldn’t feel bad about not guessing that on my own).
That’s fair, I was intending to compare against the error at 32 bit float, but you make a good point: why not compare against the original. It doesn’t change much, but let’s do it:

Here’s the spi1d error against the new “reference”. The average value of the frame goes from 0.02483428 to 0.02146268.

Here’s the “Formula based” error against the new reference. The average value of the frame goes from 0.45770344 to 0.45843539.
I guess that takes the overall error measurement from 18.43x worse to 21.36x worse for the formula based approach.
I also just had the thought maybe it’s a platform specific thing (I’m on Rocky Linux 9.5), but I just tested on a windows machine and it has the same behavior.
@remia About the SSE approximation, does this mean processing on the CPU is less precise than the GPU?
Here’s the revised nuke script (do keep in mind you would need to replace the path to the OCIO config and restart nuke).
aces_ocio_test_v2_linux.nk (10.3 KB)
And here’s a Gaffer scene showing the same behavior (it ships with the ACES studio config, so no OCIO config path needed… showing the same behavior)
aces_ocio_test.gfr.txt (23.7 KB)
(rename .gfr.txt to .gfr)
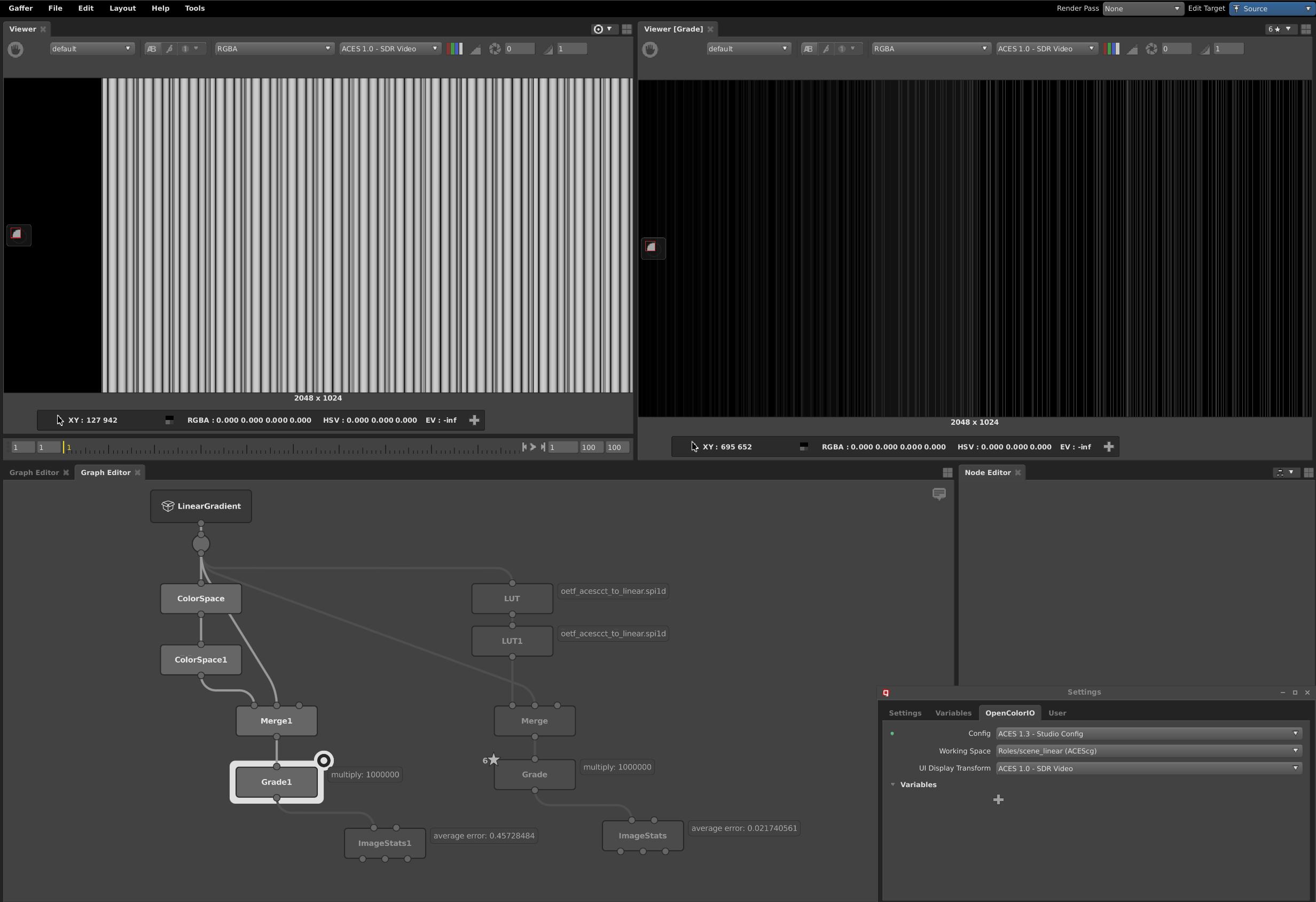
Any other ideas? If I were a compositing supervisor considering upgrading to an OCIO Config using OCIO v2 I would be very concerned about this.
Here is the differences on macOS Nuke 16.



I didn’t check the average values but at least it is obvious the flag has an effect, not sure what happen on your side though. I’m just using the export OCIO_OPTIMIZATION_FLAGS="196886467" command in the terminal before opening Nuke in the same terminal.
With the optimisation ON I think I’m seeing an average roughly of 5e-7 on the roundtrip error, obviously I’m disabling the OCIODisplay node when checking this.
Apologies, it looks like I didn’t spot the double quote characters in your original post, and this was causing the env var not to work. I can confirm now that the flag does have the same effect as in your screenshot.
Can I ask why is this not set by default? It seems like we would want the best quality possible when processing on the CPU? Is this documented anywhere?
Can I ask why is this not set by default? It seems like we would want the best quality possible when processing on the CPU? Is this documented anywhere?
Would defer to @doug_walker for more context on that flag being the default. I’m not sure how the average error compare to something like OpenEXR 16bits quantization for example, but assuming it should be similar?
All of this is moot when compared to half float quantization. If you do the first conversion in my nuke script, write to half float exr, read back in, and do the 2nd conversion, the error is orders of magnitude higher, and identical between formula-based approach and spi1d lut based approach. This is to be expected and should be obvious I guess?
I was flagging this because I was surprised that the reality doesn’t match the marketing (given that the “formula-based” approaches are touted as higher accuracy, and are now the default transform type in the new OCIO configs).
Did you check the accuracy or just the round trip here? I would assume that even with the SSE optimisation OCIO formula based transforms will be still be more accurate that a LUT implementation.
Edit: might be wrong here, I did some quick experiments and get similar results as you found. Sorry about the misleading comment.
This thread has unfortunately taken a turn that is unrelated to ACES2 implementation. The log transform that Jed tested is not used for the ACES2 implementation in OCIO.
The differences between shader and LUT-based implementations of either the ACES 1 or ACES 2 Output Transforms (using OCIO, or not) can be quite significant for certain colors. (No need to boost the difference by one million times, as was done for the log transform test above!)
Regarding OCIO, there are several dozen optimization flags that may be set that control the trade-offs between speed and quality. The one that is relevant to the log transform tested above is OPTIMIZATION_FAST_LOG_EXP_POW.
If that is enabled, when implementing several transform types (not including ACES2) on the CPU, OCIO uses much faster versions of several basic math functions that are accurate, in the mean, but have a precision somewhere between half-float and full-float.
As Remi wrote, one may use the OCIO_OPTIMIZATION_FLAGS environment variable to turn various optimization settings on or off in apps such as Nuke or Maya. Each flag is one bit, so the “196886467” value arises by turning that binary string into a decimal integer.
The consensus was to have the default for this flag be “on”, but the OCIO project is always open to feedback on this. (As of now, no issues have been logged asking to change the default.)
1 Like
I have done just that for us here as no tool supports OCIO 2.4 yet except for Flame.
Using the LUTs from v60 as well, looking forward to upgrading to the shader based implementation once our tools have been upgraded to 2.4.
It will probably be a while but we need to be at least mostly compatible with Resolve 20 and studios wanting to use aces 2.0 and delivering Shotgrades based on 2.0
Nuke, Blender, Houdini , Unreal , Substance… and a bunch of aux tools all need to be upgraded before we can even think about using the shader based approach, so thats pretty much where we are at.
If there is a better method to build better LUTs or whatever that get people going i think many would in fact appreciate this.
2 Likes
Hello,
Doubling up on @Finn_Jager’s comment here. We have a lot of interest from VFX sups who would like to use the new DRT for their CG work. But, we are a long way out from having all our DCCs on par.
An alternate config (albeit maybe not as precise) would be greatly appreciated.
For now, we can use the blink in order to “pass it around” for testing and I did produce a LUT from it. But, I’m very sure that said LUT is probably not ideal/good.
Thanks!
Just a reminder that one can always generate LUTs from the CTL. This would guarantee that your LUTs are based off the reference transforms and not the development code.
If anyone has old scripts that built LUT-based configs from the v1.x transforms, then that could probably also be updated fairly easily to utilize the new CTL.
If getting CTL up and running is the barrier, then I can help process tables to generate LUTs for different outputs, but it should be able to be scripted pretty easily. The reason I haven’t tried to provide this is that crafting good LUTs requires knowledge of the in/out spaces and the context, and I’m not clear on the details of the in/out shapers and usage within a config. (I could figure it out but don’t have time to dig into that right now). If somebody wanted to provide some specs or a config with placeholders and direction of what they needed from the CTL, I could help process.
But it’s pretty easy to install CTL and run the ACES transforms yourself to generate any LUTs you might require for your specific use cases.
Thanks @sdyer. I will try to get my hands dirty with CTL. Seems simple enough with ctlRender. Any pointers or caveats?
Cheers!
The most common thing is that people forget to configure their CTL_MODULE_PATH environment variable. This lets the CTL interpreter know where to look for the transforms that you feed to ctlrender with the -ctl flag. This is noted in various places in READMEs, and refer you to the “CtlManual.pdf” (bottom of p.10) for details.