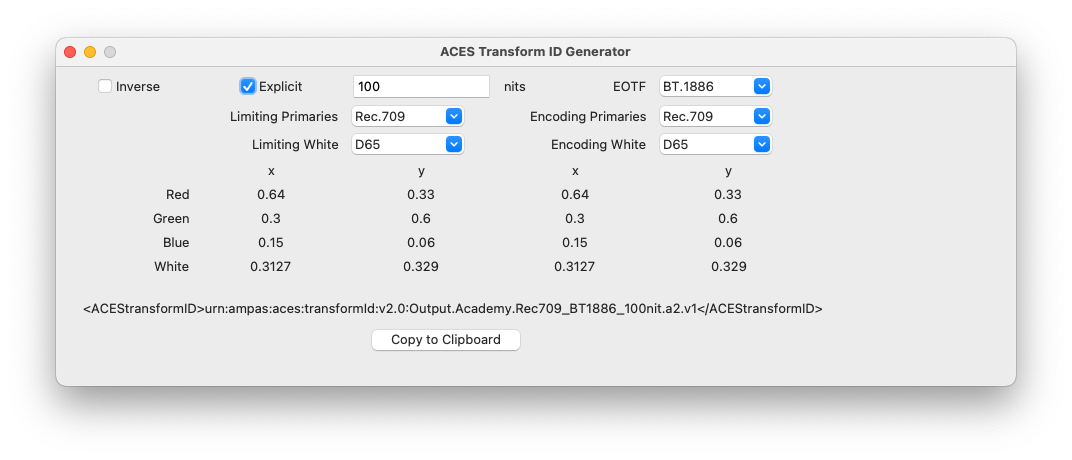
Following on from discussion in meeting #157, this thread is for discussion of how much information should be included in the ACES Transform ID for output transforms.
Currently the ID includes:
encoding_primaries (and white point, if primaries may be paired with different whites)
EOTF (omitted if implied by encoding primaries)
limiting_primaries (omitted if identical to encoding primaries)
Peak luminance (omitted if the encoding always has the same peak luminance)
Creative white point (D**sim) if different to encoding white point
In one special case the peak luminance is described at 100nitsim since this creates a “simulation” of the 100 nit Rec.709 transform on a PQ display.
So an ID could be as short as Rec709 because “everybody knows” all the other values that go along with that. Or it could be as long as P3D65_ST2084_Rec709limited_300nit_D60sim (contrived example to use all attributes).
The alternative would be to include every aspect of the transform in all IDs, even if some may already be implicit. This would simplify automated parsing of IDs, for tasks such as automated generation of OCIO configs, without the necessity to create mapping lists or hard code “assumed” values.
File names and user names coulkd still use shortened forms.
I think it is preferable for everything to be explicit, rather than implicit. For example, while the P3D65 transform is implicitly 2.6 gamma for theatrical, that can only really be confirmed by looking through the rest of list at the existence of the DisplayP3 and HDR P3 transforms, and deciding that this one must be 2.6 gamma theatrical because it is not any of the others. Indeed I was asked by people testing the candidate transforms for confirmation that the P3D65 one was 2.6 gamma, because they couldn’t be certain.
The sRGB transform is another example. Many people “know what sRGB is” but not all of them believe the same thing!
I would also suggest that saying “100nitsim” is unnecessary. All the HDR transforms, such as the 500 nit one, could be said to be simulations of a less capable display on a more capable one. If it is described as Rec2020_ST2084_Rec709limited_100nit, that says exactly what it is. I feel that a description of its intended use (which is what the addition of “sim” adds in this case) is more appropriate in the <ACESuserName> field, leaving the ID to be a purely technical description.
Just some questions for further discussion and as I just try to imagine this:
What happens for instances where creative white is the limiting white is the encoding white?
Do we say P3D65_P3D65limited_gamma-2pt6_D65sim_100nit?
Becasue that to me is way more confusing than P3D65…
What is the preferred ordering?
Let’s use an example of a Rec.709 limiting gamut, a P3D65 encoding, ST.2084, 500nit.
We could state the intended appearance first as Rec709_500nit_as_P3D65_ST2084 or state the encoding info first P3D65_ST2084_Rec709_limited_500nit.
Which bit should go first? Should the value of the luminance roll-off go at the end or be kept with the “display set-up” info or the “limiting gamut” info?
“…without the necessity to create mapping lists or hard code “assumed” values”
Wouldn’t an implementation still need to build the logic to parse the options in a transform ID if they were trying to automate parsing? Wouldn’t they still need to make a mapping of text strings tied to the associated function? How exactly would this make it “easier”? (It very well might, I just want to understand better how we could make it useful)
How explicit does our naming get? You’ve already posited this question by wondering how we’d encapsulate custom primaries that aren’t defined. But same goes for other EOTFs or ones with modified values from the default settings? For instance, i s calling the EOTFs, BT.1886 or sRGB sufficient? (Can we at least assume that people will know these mean BT.1886 with g=2.4, L_w=1.0, L_b=0.0 or IEC 61966-2-1:1999 with gamma=2.4 and offset=0.055?)
How should we actually write the gamma value?
Periods are not recommended to be used in the transform string because they are the separator between the TransformType, Namespace, Filename, and Extension.
Which seems least problematic?
gamma_2pt6
g26
g=2pt6
gamma-26
gamma_26
other…
Perhaps we should add a few columns to the spreadsheet and prototype some options, as having examples should help the conversation.
My code dropped the “limited” and “sim” parts if they matched. So I would say P3D65_gamma2pt6 for that one, because those are the two things that need specifying.
But I do realise that having a variable number of entries makes parsing more complex. I’m no RegEx expert, but if all the entries have to come from pre-defined lists, you could possibly use “zero or more from this list” type syntax, couldn’t you?
And for BT.1886, I am fine with just that implying exponent=2.4, L_W=100 (or normalised 1.0), L_B=0, since for encoding you should never use it any other way.
omit X00nits if SDR (becasue of the complexity in concisely explaining 48-nit or 100-nit are essentially interchangeable)
omit D6Xlimited if limiting matches encoding primaries
omit D6Xsim if limiting white matches encoding white
Does is also make more sense to put the peak luminance with the display encoding rather than the limiting primaries?
I’ve added a few columns to the spreadsheet to see how this would look, with the revised transformIDs in purple text
This would also allow us to get rid of displayP3/ and displayP3-hdr/ subdirectories (because those now fit in regular the p3/ and p3-hdr/, since we’re explicitly stating the EOTF differences. But the folder organization hasn’t been changed yet in the spreadsheet.
Please be as stringent as possible.
Add mandatory strings at the beginning in the same order, so we have a maximum of sub strings we can reliably read. Add additional stuff at the end, ideally only have mandatory substrings.
Nested parsing is much easier than 1:1 mappings.
For example all P3 and Rec2020 flavours of PQ can be parsed efficiently if the only differences are the primaries.
In the end we are trying to recreate structured output from the IDs.
Currently it permits every permutation. I will update it at some point so that it prevents meaningless combinations.
Update: the current version restricts the permutations somewhat. Exactly which permutations should be allowed is up for discussion.
In theory the script could then spit out the CTL for the selected transform. But since nobody would actually use it in CTL form, that would not be much use.
Note: The “copy to clipboard” button uses a hack that I think will only work on a Mac.
That’s what we’re trying to do. A concern was raised that the transform IDs for the v2 code wasn’t structured enough nor easily extensible to additions. We are thus trying to figure out what could be done to get it right for the official final release because we don’t want to need to change them again.
What should be mandatory strings?
What are the mandatory strings for additional stuff at the end?
Does the spreadsheet match your concerns or can you point out examples where we are not doing something in a manner compatible with nested parsing?
They ideally need to be programmatically generated with the least special cases/branching as possible so that they can be parsed easily.
Something inconsistent is that the Input Transforms are of the form TransferFunction_Primaries which is what OCIO now uses for the same spaces. We are are about to suggest using this form for Nanocolor and in the ColorInterop forum but here for the Output Transform, we are using Primaries_TransferFunction.
Thanks for the specific example and use case. That is helpful in trying to determine what we should consider changing to.
Are you requesting that Output transforms also adopt TransferFunction_Primaries?
As an experiment I tried changing it around in the spreadsheet (in new green text column) and it seems quite awkward to me.
On Input, the most first thing is the linearization, then the color encoding, whereas its the inverse when selecting an output, isn’t it usually the primaries and then the transfer function is always the last variable just to send it down the wire the right way?
I’m not necessarily requesting for a change but pointing out to a naming inconsistency. If there is a rational behind it, this is by all means good but we need to document it properly somewhere. There was a doco describing how the ACEStransformID are built, are we planning to dust bust it and update it?
I agree with Thomas,
the IDs should be generated programmatically.
The new changes to the document go in the right direction.
That would allow us to create a map of our tags programmatically.
ps.:
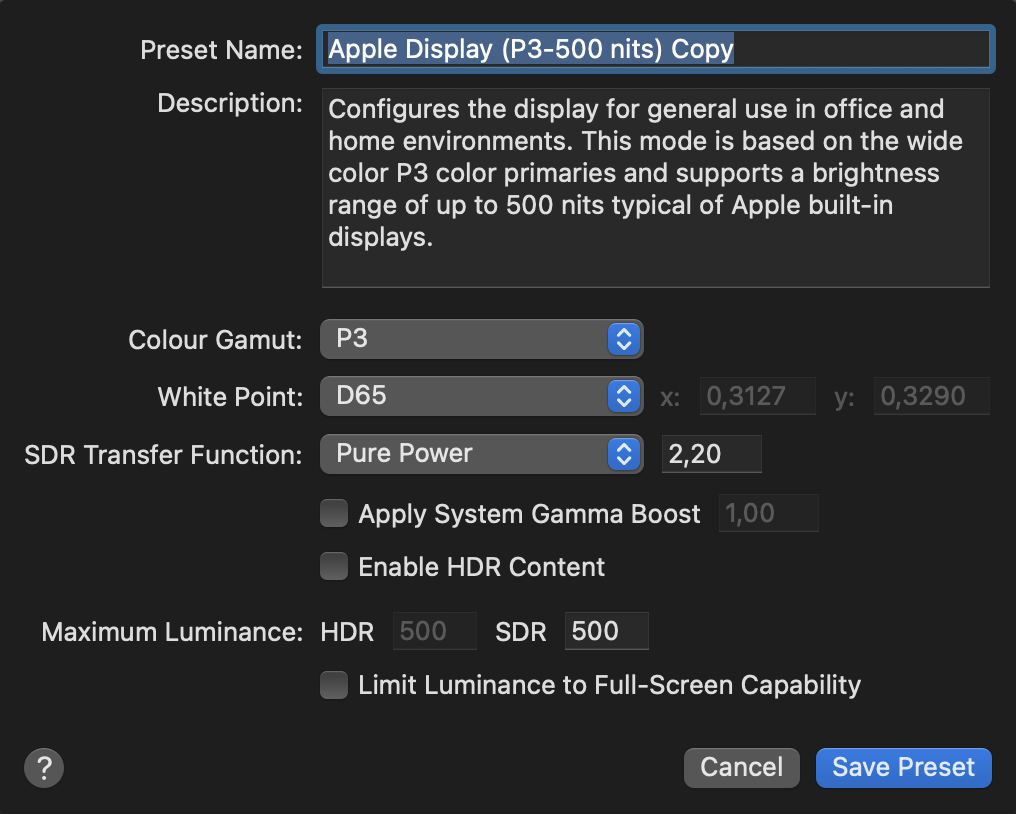
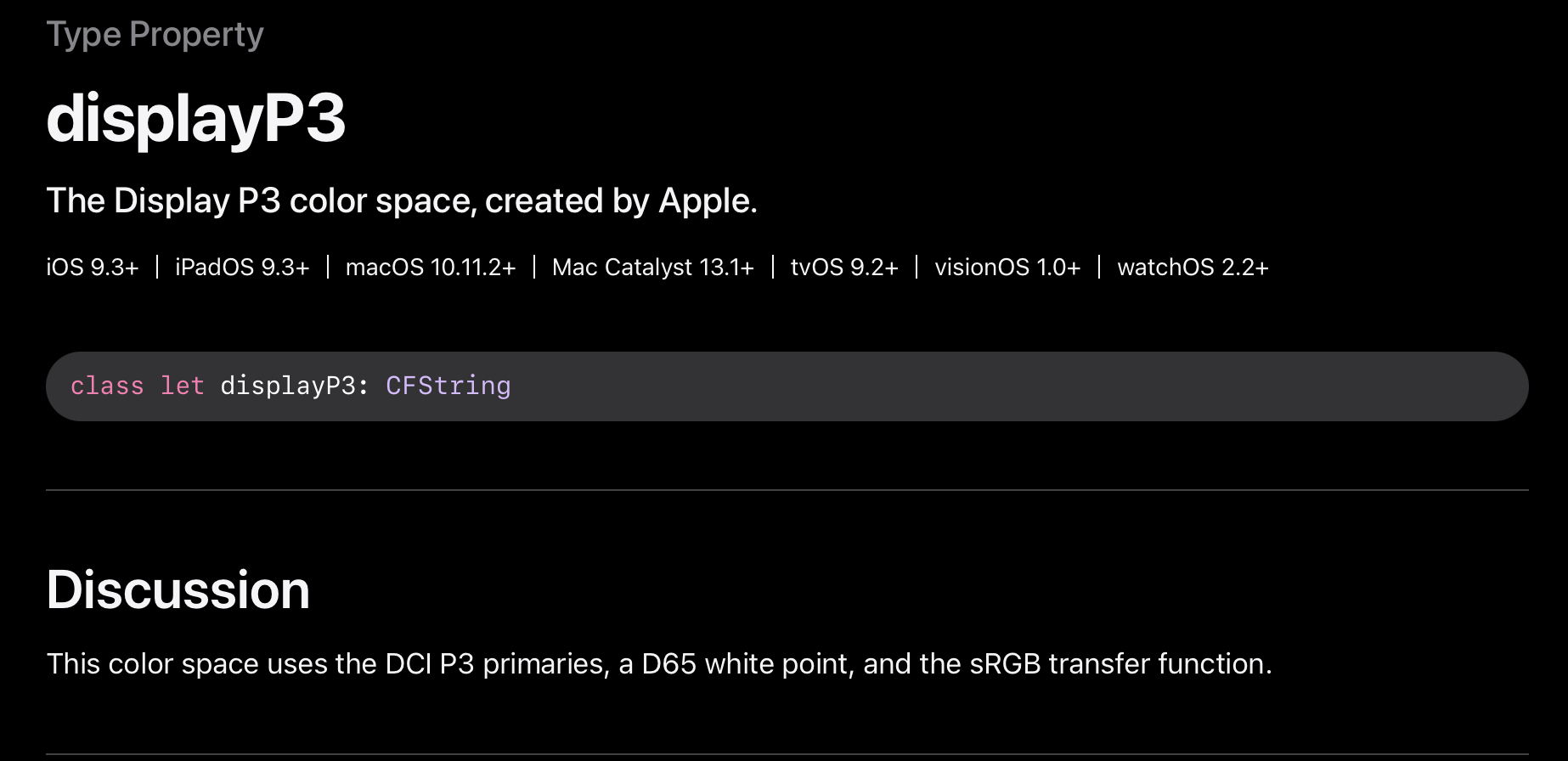
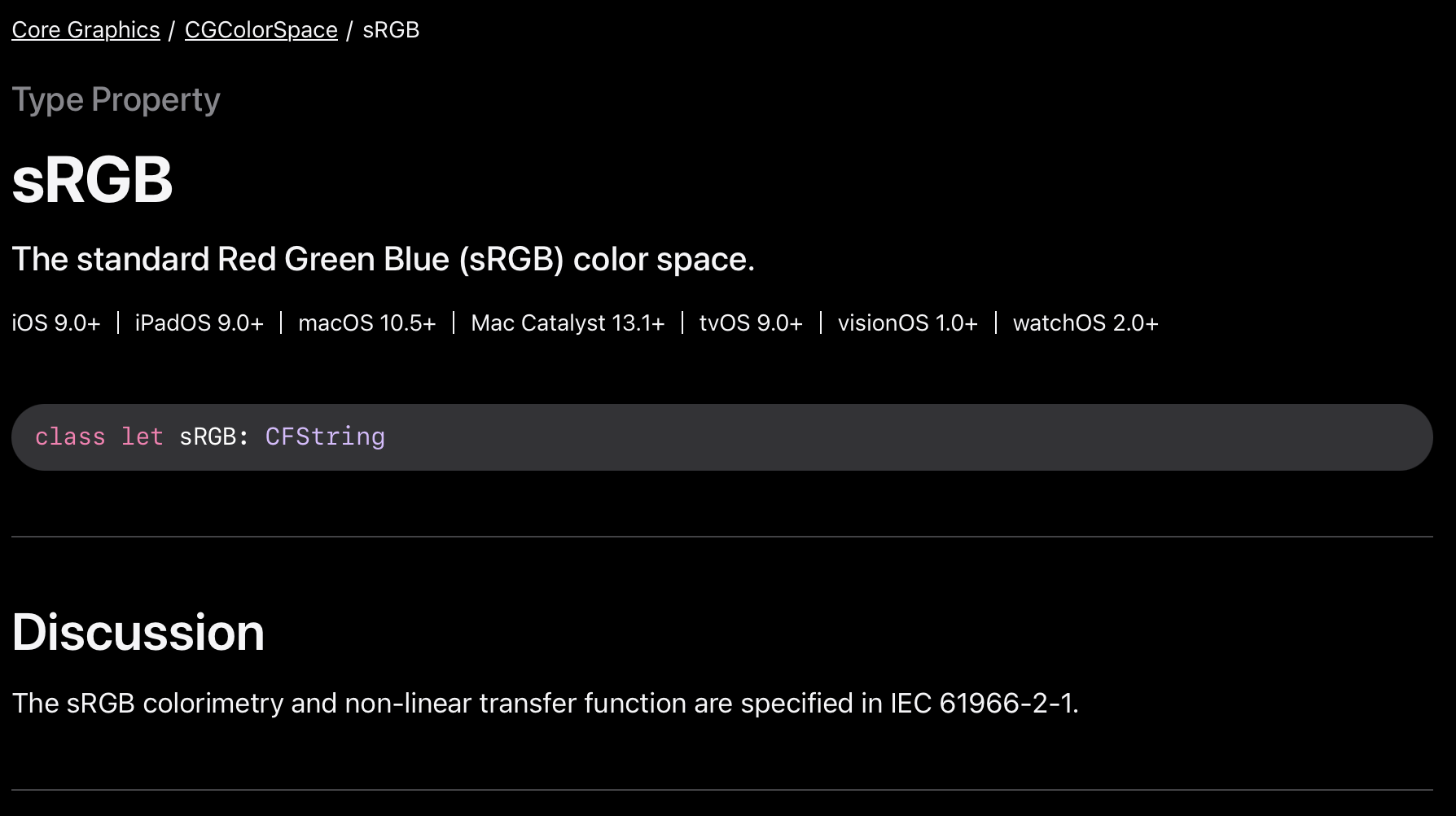
Apple P3 is not compound function but plain 2.2 Gamma:
The one that we are using at work and made a PR for (and was requested by other companies) is the one from Apple documentation with a piece-wise transfer function.
Edit: To make things even more complicated, we also use a pure 2.2 power variant but this predates the Apple one by at least half a decade.