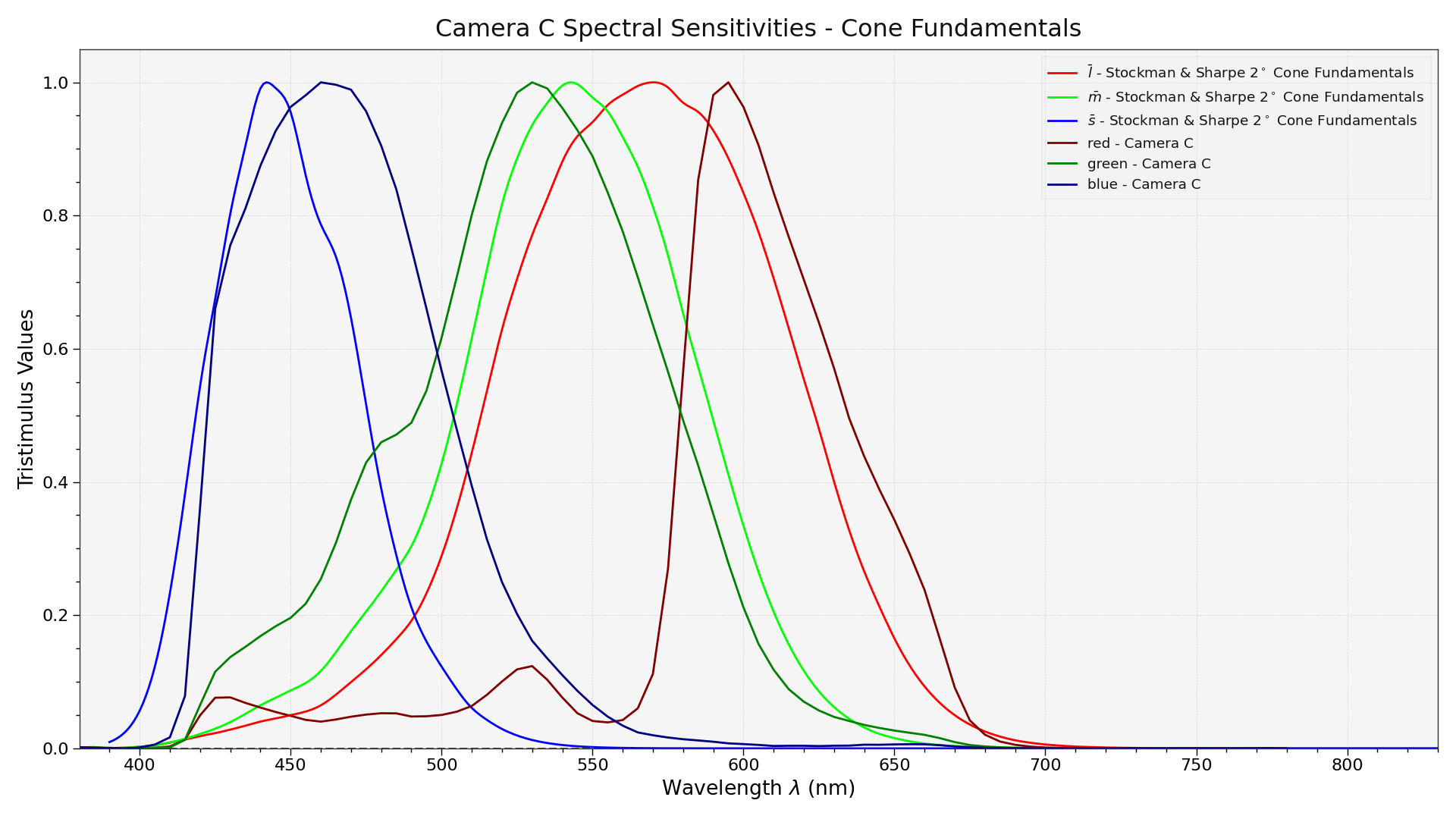
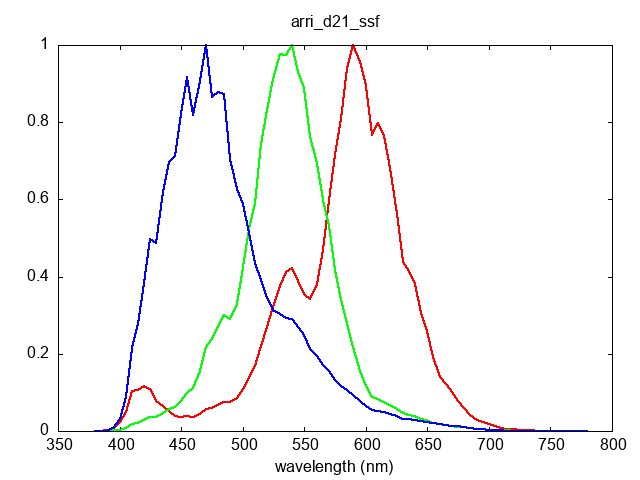
Yes but if you do that you are facing incredible amount of noise in the red channel, see where our green and red (more yellow actually) cones are peaking compared to that of a CFA:
It yields less frequency “separation” capability because of the way they overlap, fortunately our brains are amazing at solving that problem, cameras less so! 
You could push the reasoning and say we could use multi-spectral imaging camera systems and they do exist! They are unfortunately extremely expensive and the realm of research. Such a device theoretically allows you to simulate the spectral response of anything it covers the spectral domain of because you have all the frequency data captured. The problem is that the datasets are huge, we are talking about 5, 6 10, 20 channels per-image, it raises the manufacturing complexity, storage cost, processing cost, everything increases dramatically.
As of right now, there are no real constraint on what ACES2065-1 white balanced scene-referred exposure values should be. P-2013-001 - Recommended Procedures for the Creation and Use of Digital Camera System Input Device Transforms says that:
The image data produced by the IDT shall:
- In the case of D60 illumination, approximate the ACES RGB relative exposure values that would be
produced by the RICD
- Approximate radiometrically linear representations of light reaching the focal plane,
- Contain a nonzero amount of flare as specified in the ACES document,
- Use equal RGB relative exposure values to represent colors that are neutral under the illumination source
for which the IDT is designed, and
- Approximate a colorimetric response to the scene for the illumination source for which the IDT is de-
signed, though the native camera system response itself may not be colorimetric.
There is no metric on how good the colorimetric response should be and against which specific target which leaves a lot of room to bias the response toward certain colours. We actually discussed about it quite recently with @Alexander_Forsythe!
We are wandering in a philosophical territory here, and I’m torn on this one: It would indeed be great if all the camera were producing the same response for us, but then all the cameras would be the same and have the same look which is not a good selling point. One could argue that the look should come from Picture Rendering only but it is effectively the combination of all the steps. If you think about film stock, there are many different stocks with different looks, it might sound easier to have a camera system producing colorimetric values and then bias the look during Picture Rendering. However, I certainly don’t see why a vendor should be forbidden to have the two first steps biased toward a particular colour reproduction goal.
It all comes down to the way the optimization has been designed and with which datasets.