That is really interesting. It is similar to the “hexagonal” variant on the gamut compressor that we discussed but abandoned during the development of the RGC.
Because it compresses along straight lines to the white point in CIExy, it does create the same kind of cusps near the primaries as the hexagonal gamut compressor:
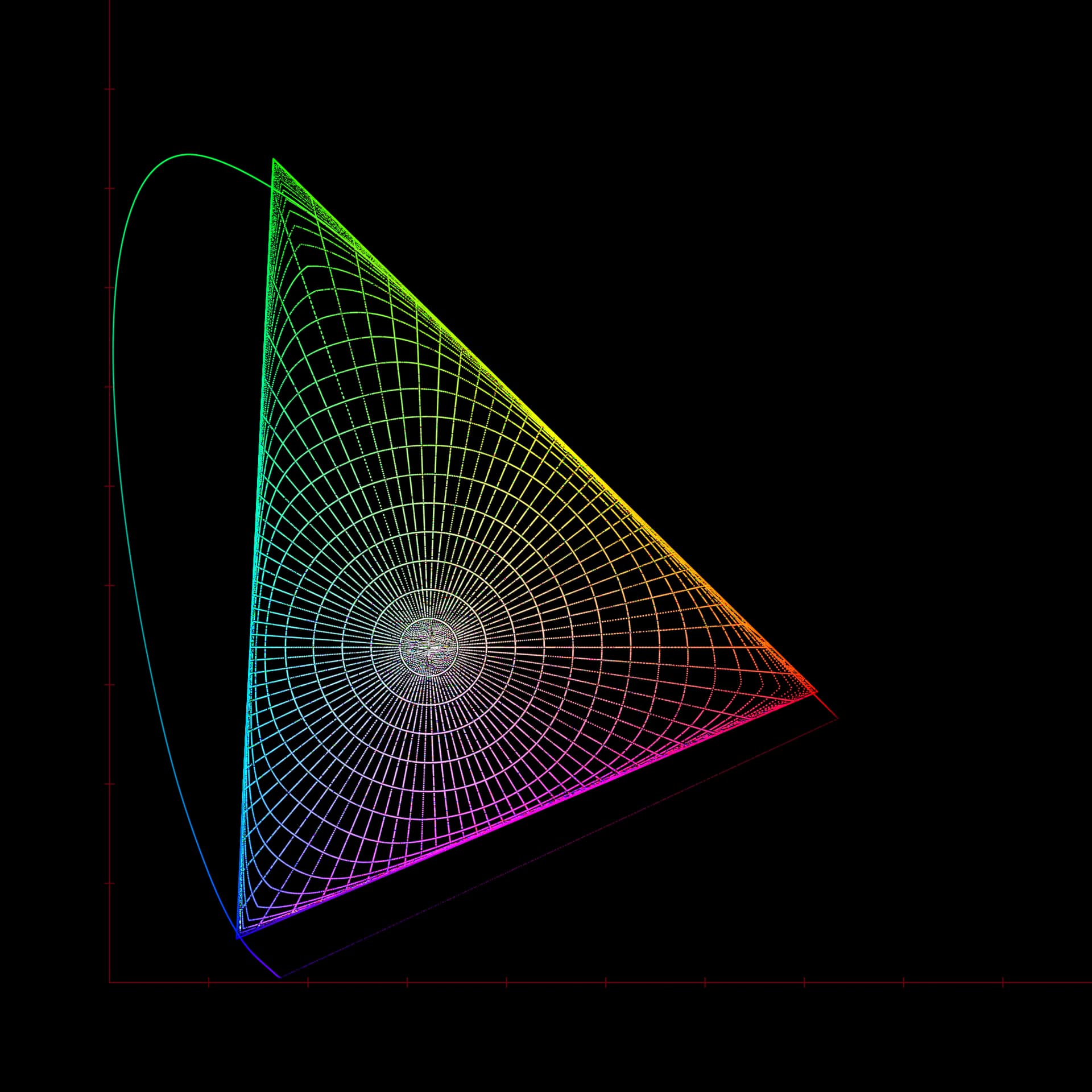
It is also non-invertible because it compresses infinite distance to the gamut boundary. But this could be changed by using a different compression curve. And if it was only used in an LMT to “pre-condition” problem images, rather than being part of the DRT, inversion might not be necessary anyway.