Wow, that escalated quickly…
![]() Guilty here. But:
Guilty here. But:
One of the most prominent appearances of colour appearances in literature close to our industry can be attributed to R.W.E Hunt. He got a whole chapter about that subject in his book ‘The Reproduction of Colour’ (PART SIX EVALUATING COLOUR APPEARANCE).
Also, he names chromatic adaptation as a form of colour appearance. He puts it as the basis of creative colour reproduction (also in film). He is referring to CAMs in his definition of preferred colour reproduction in his taxonomy of colour reproduction:
- Colorimetric colour reproduction
- Exact colour reproduction
- Equivalent colour reproduction
- Colorimetric colour reproduction as a practical criterion
- Corresponding colour reproduction
- Preferred colour reproduction
There is a considerable body of evidence that for Caucasian skin colour the above concepts must be supplemented to allow for the fact that a sun-tanned appearance is generally preferred to average real skin colour (MacAdam, 1951; Bartleson and Bray, 1962). There may also be other colours where similar considerations apply: for instance, blue sky and blue water are usually preferred in real life to grey sky and grey water; colour films can have some sensitivity to ultra-violet radiation and hence tend to increase the blueness of sky and water relative to the saturation of the other reproduced colours, but such a tendency, if not overdone, may well be preferred to a more consistent reproduction. It may also be desirable to introduce other distortions of colour rendering to create mood or atmosphere in a picture. These factors may be very important in practice, but it is felt that the concepts of spectral, colorimetric, exact, equivalent, and corresponding colour reproduction, provide a framework that is a necessary preliminary to any discussion of deliberate distortions of colour reproduction. In this context, preferred colour reproduction is defined as reproduction in which the colours depart from equality of appearance to those in the original, either absolutely or relative to white, in order to give a more pleasing result to the viewer.
(R.W.E Hunt)
Emphasis on depart from equality of appearance.
I tend to agree with the overall conceptual framework.
But I must agree with Troy that we should not treat CAMs as a godsend because, as Troy pointed out, there is no per-pixel solution. I also don’t think that we actually have a problem. We do not need to ‘pre-perceive’ the image for the viewer.
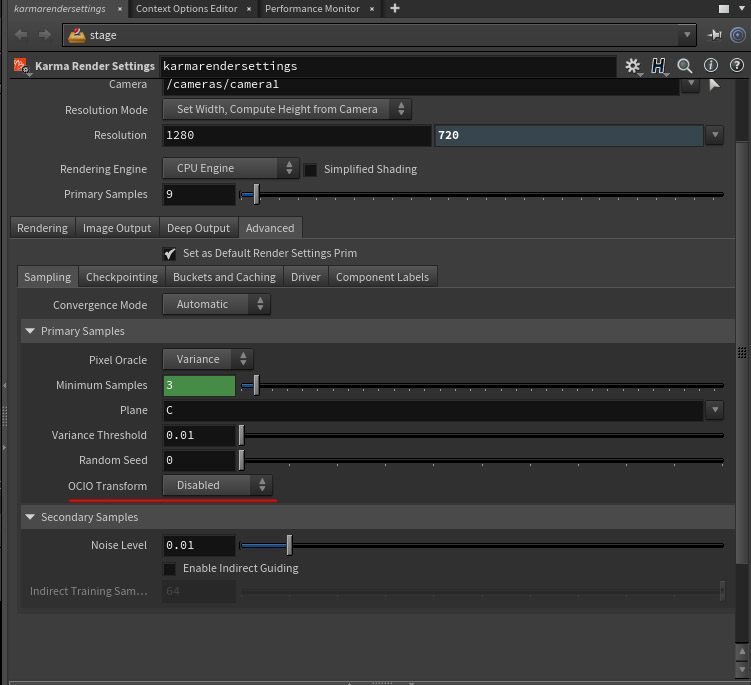
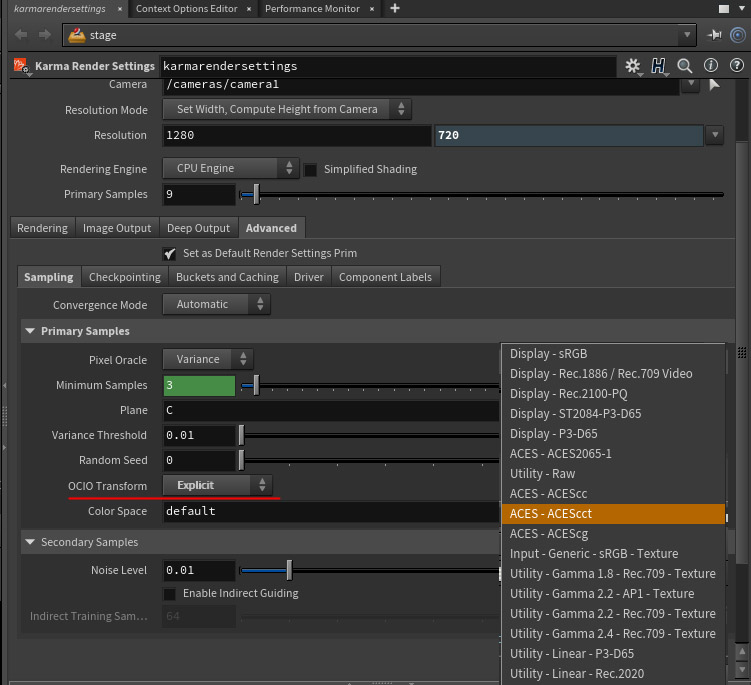
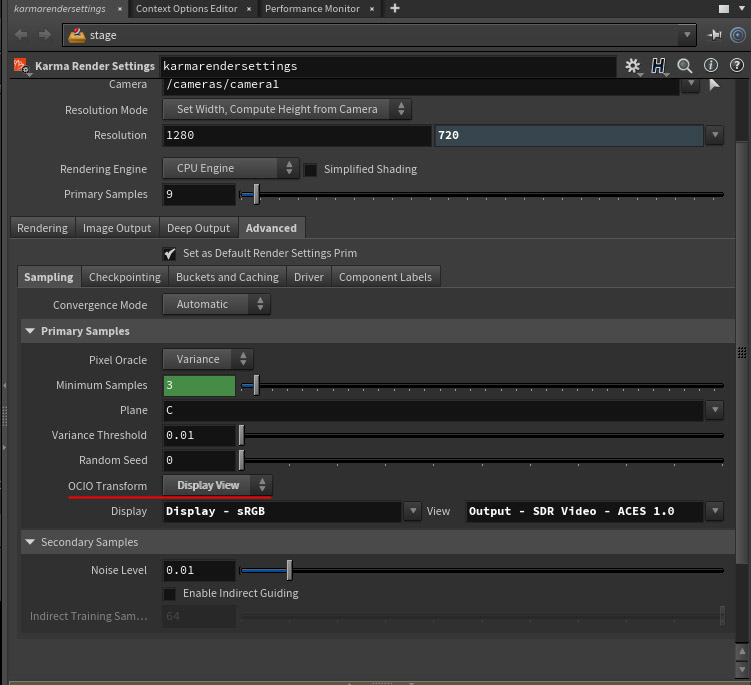
We just need a transform which allows us to do our work with ‘a bit of abstraction’ to the final explicit display technology (try to choose my words carefully here), so we can modify it easily to be reproduced on displays with slightly different capabilities.
Especially the CAMs derived with no requirements for image rendering should be taken with an extra portion of grain of salt. They were never intended to be used in the context we are using them for.
Lightness
It is naive to think we can calculate lightness or anything remotely close to that without a big ‘scene understanding’ model in the background. And we are years away from tackling that (but things are progressing quickly lately). The best summary I know is from Paradiso ‘Illuminating the dark corners’. It is just three pages.
https://www.cell.com/action/showPdf?pii=S0960-9822(99)00249-3
Brightness and Luminance is useless or even misleading in my eyes.
At best, we can calculate a proxy of achromatic. But then it needs to be simple and robust and not suggest some arbitrary weights up to the sixth decimal place resulting from fitting exercises. That is nonsense in my eyes. Also, complex models that make our lives harder are not helping us in the end.
That all applies to all other colour-appearance scales.
Inversion
I agree 100% with Troy. The desire for invertibility comes from those who want to avoid using the process in the first place. It is a naive wish, chasing rainbows, an daydream of an unrealistic utopia. It is seductive and leads to the wrong working paradigm and bad habits.
We can use some considerations from CAMs to guide us, but if we see that we are adding duct tape on top of duct tape to fix something somewhere, we went too far.
Flexiblity
I cannot resist restating that a good DRT is one you can swap for another. ![]()