Hello Chris,
fair enough if we don’t want to over complicate the framing metadata node.
I just don’t quite understand what the expectations are from the extraction node, as to me it seems to be quite a hybrid concept now (especially after adding the V+H scaling): are we expecting from it to allow a software to pre-process a source frame so it can be transformed to fall into specific pipeline requirements or simply to provide an instruction of some sort that users will have to visualise a specific region of the source frame?
The latter only requires the extraction node then (one could argue that not even the scaling is needed) as its function will basically match that of the camera framelines on set. If so, then I understand what was your point initially and I do agree, we’ll be fine with extraction+offset.
If, on the other hand, we hope that this set of metadata will automate some steps in post, a bit like the metadata contained into the .mxf Alexa Mini files that allows to crop files recorded with a 4:3 2.8K flag to the right extraction (2880x2160), instead of leaving them Open Gate (which is what the camera really records), or like it happens with all cameras when shooting with an “anamorphic” flag (Arri, Red, Sony, all do the same) which instructs the software to automatically desqueeze the input frame accordingly to the right ratio. If that’s the aim then I have to reiterate my points and say that I believe we need the four (five, maybe) nodes as I was trying to explain on my post above, to make sure that things are instructed properly for each stage of production and post.
To go back to your points, the way I see it, the Target Area is not going to be affected by the specific use cases as it communicates exclusively the area framed on set by the Camera operators. In fact, the way how I see it, nothing really a part from the output scaling (the output resize, which we are currently not even considering here) drastically changes from use case to use case, except when there are specific needs in place, especially at the far end of the post production (like the ones quoted by Walter and Jim, ie center crop, pan and scan, QC, etc.).
In a tree composed by INPUT FRAME, EXTRACTION (CROP), SCALING (V+H), TARGET AREA (V+H), ACTIVE AREA (V+H), I can see:
- INPUT FRAME and EXTRACTION as mandatory fields that will be related to how the source frame is meant to be extracted (cropped).
- SCALING as optional third element of the extraction pipeline which is relative to the extraction output and tells how the cropped frame needs to be up/down scaled.
- TARGET and ACTIVE are optional instructions aimed to the software that needs to work on the extracted and scaled images, to workout the canvas size (ACTIVE AREA) and the on-set intended framed area (TARGET AREA). The results of those two instructions won’t directly affect/transform the image, but only how the software will show it to the user, or on what it will allow the user to work on.
I will try to make some examples of how the framing metadata section would look like for me using some real-life examples of extraction guidelines designed on different shows over the years.
To put things in context, however, I would also like to pick a show and share all the framelines we had to design for Aladdin (Disney - 2019), which was a multi camera, multi lenses, multi format show that had complex needs. You can download them from here (Dropbox Link): Dropbox - PRODUCTION_SOURCE_FRAME_LINEs - Simplify your life
Let me consider two, quite standard, use cases:
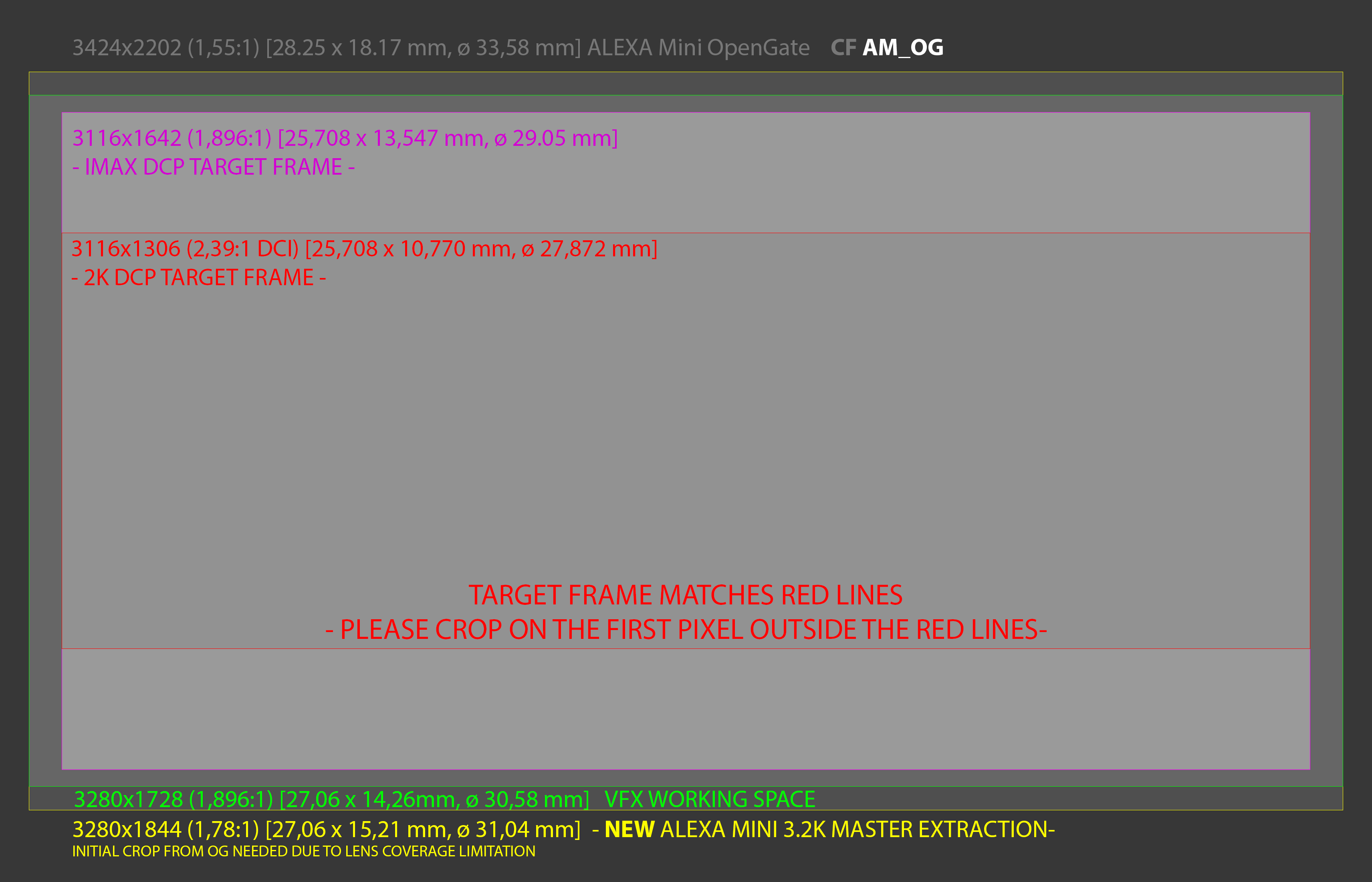
- Multiple target frames, with extraction crop due to lens coverage and extra room for VFX area (from LIFE- Sony).
Put into context: Shooting Open Gate, lenses chosen by the DP won’t cover it (no surprises there, right?), hence all target frames needed to be calculated from an area that lenses would cover. We would normally just scale the input source to the desired VFX resolution, without cropping, but there was a problem: Sony required a 4K master, VFX costs demanded to keep their bits in 2K, DI (Tech) and DP wanted to keep the higher possible resolution. We managed to all agree on a 3.2K pipeline as it matched a full 35mm film gate, so lenses would cover, and it was the max allowed without incurring into extra budget for the VFX renders. This way both drama and VFX could be done at the same resolution and DI would be able to scale to 4K or 2K with better results.
Also, because the project required a 3D post conversion and an IMAX release, there was need of some extra room to allow all that fun too.
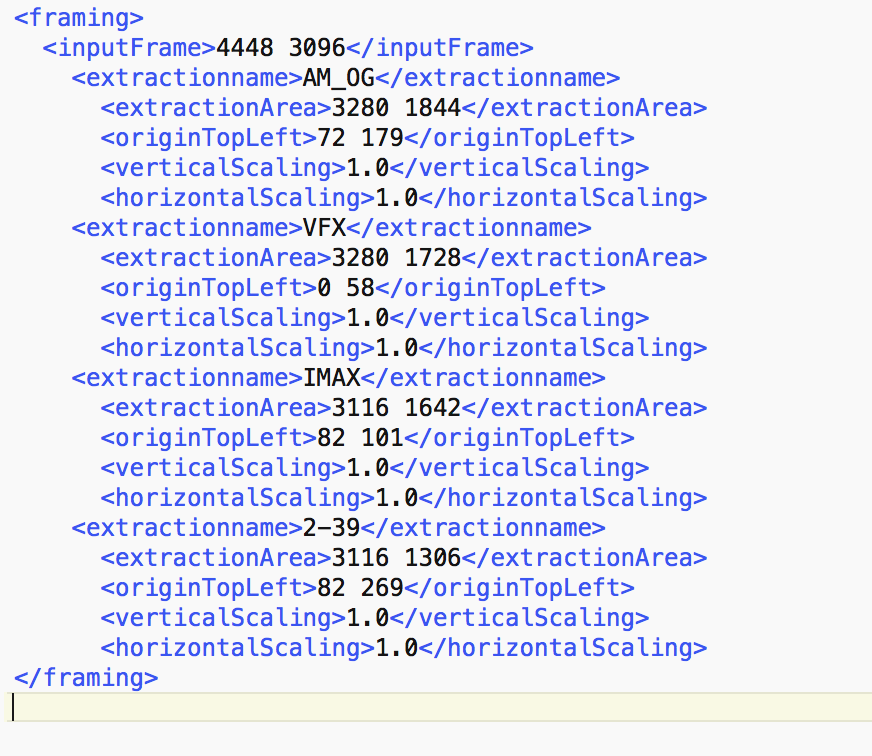
This would be the AMF:
<framing extractionName="AM_OG">
<inputFrame>3424 2202</inputFrame>
<extraction>
<extractionArea>3280 1844</extractionArea>
<extractionOriginTopLeft>72 179</extractionOriginTopLeft>
<verticalScaling>1.0</verticalScaling>
<horizontalScaling>1.0</horizontalScaling>
</extraction>
<activeArea activeAreaName="VFX">
<activeAreaSize>3280 1728</activeAreaSize>
<activeAreaOriginTopLeft>0 58</activeAreaOriginTopLeft>
</activeArea>
<target targetName="IMAX">
<targetArea>3116 1642</targetArea>
<targetOriginTopLeft>82 101</targetOriginTopLeft>
</target>
<target targetName="2-39">
<targetArea>3116 1306</targetArea>
<targetOriginTopLeft>82 269</targetOriginTopLeft>
</target>
</framing>
The same AMF would work for VFX pulls and dramas, but not for dailies. Since for AVID we normally crop the east-west edges of the frame to the target frame and then we leave the north-south to fill the 1.78:1 container, when it is possible. So, the version of the above AMF for dailies would look like:
<framing extractionName="AM_OG_dailies">
<inputFrame>3424 2202</inputFrame>
<extraction>
<extractionArea>3116 1752</extractionArea>
<extractionOriginTopLeft>154 225</extractionOriginTopLeft>
<verticalScaling>1.0</verticalScaling>
<horizontalScaling>1.0</horizontalScaling>
</extraction>
<target targetName="IMAX">
<targetArea>3116 1642</targetArea>
<targetOriginTopLeft>0 55</targetOriginTopLeft>
</target>
<target targetName="2-39">
<targetArea>3116 1306</targetArea>
<targetOriginTopLeft>0 223</targetOriginTopLeft>
</target>
</framing>
This should cover most of the needs for this project.
- Anamorphic 2x squeeze, with extra room for VFX area (from Aladdin)
The AMF would be:
<framing extractionName="ASXT_4-3_2x">
<inputFrame>2880 2160</inputFrame>
<extraction>
<extractionArea>2880 2160</extractionArea>
<extractionOriginTopLeft>0 0</extractionOriginTopLeft>
<verticalScaling>0.5</verticalScaling>
<horizontalScaling>1.0</horizontalScaling>
</extraction>
<activeArea activeAreaName="VFX">
<activeAreaSize>2578 2160</activeAreaSize>
<activeAreaOriginTopLeft>151 0</activeAreaOriginTopLeft>
</activeArea>
<target targetName="2-39-desqueezed">
<targetArea>2450 2052</targetArea>
<targetOriginTopLeft>215 54</targetOriginTopLeft>
</target>
</framing>
This time VFX gets the full gate, as well as DI, so no crops required for post. Once again though, we need to extract differently for dailies:
<framing extractionName="ASXT_4-3_2x_dailies">
<inputFrame>2880 2160</inputFrame>
<extraction>
<extractionArea>2450 2160</extractionArea>
<extractionOriginTopLeft>215 0</extractionOriginTopLeft>
<verticalScaling>0.5</verticalScaling>
<horizontalScaling>1.0</horizontalScaling>
</extraction>
<target targetName="2-39-desqueezed">
<targetArea>2450 2052</targetArea>
<targetOriginTopLeft>0 54</targetOriginTopLeft>
</target>
</framing>
This would cover most of the needs for this show.
The general idea is that the frame gets pre-processed by the software following the extraction node, then the active and target areas could only be a visual reference or, for some software implementations, become useful to set up the project/timeline or double check that the existing timeline/canvas size matches to what is required. I’m guessing, for example, that AVID would be able to transform the target frame instructions into a blanking filter for the timeline, as the editors now manually set up. Davinci could do the same (with the blanking).
I understand and now agree that we don’t want to over-complicate things with output scaling resolutions and leave the softwares to adapt these framing numbers to the desired resolution using their own methods, but if we add those additional nodes we could at least allow for every useful information to be carried through and properly communicated to each vendor.
As I’m writing this I’m also realising that the target area should really be put down as a relative number, like ARRI does in the xml framelines, so that the pixel count can be calculated by the software after the internal scaling (if you scale a source frame of 2880 px to1080 px then the target area numbers won’t mean much unless they get scaled as well, but maybe it’s easier if they get written down as relative instruction in the first place).
I know I’m insisting a lot here, but I just wanted to make sure that my points were clear.
I’m not going to bring this up again if you guys think I’m overthinking it.
As usual, sorry for the thousands words.
F.
 But I personally like that one considering it checks all scenarios I have came across, regardless of how likely they are to come up. The other thing I would wonder is if it’s possible to actually label it:
But I personally like that one considering it checks all scenarios I have came across, regardless of how likely they are to come up. The other thing I would wonder is if it’s possible to actually label it: