Thanks for summarizing the effort (and debate) so far, its good to see it all laid out. Sunlight is the best disinfectant, as they say 
What I’d personally really like to see at the end of this document are definitive questions that we will collectively work to resolve moving forward.
I’ll propose the following:
- Along what dimension are we mapping values?
- What is the boundary of the zone of trust/safety/maximum-viable-gamut/no-touchy?
- What is our metric of success?
Imbued in my proposed questions are some assumptions so I’ll spell out my thoughts with regard to each one, and maybe we can settle on some good questions that we can rally behind.
Along what dimension are we mapping values?
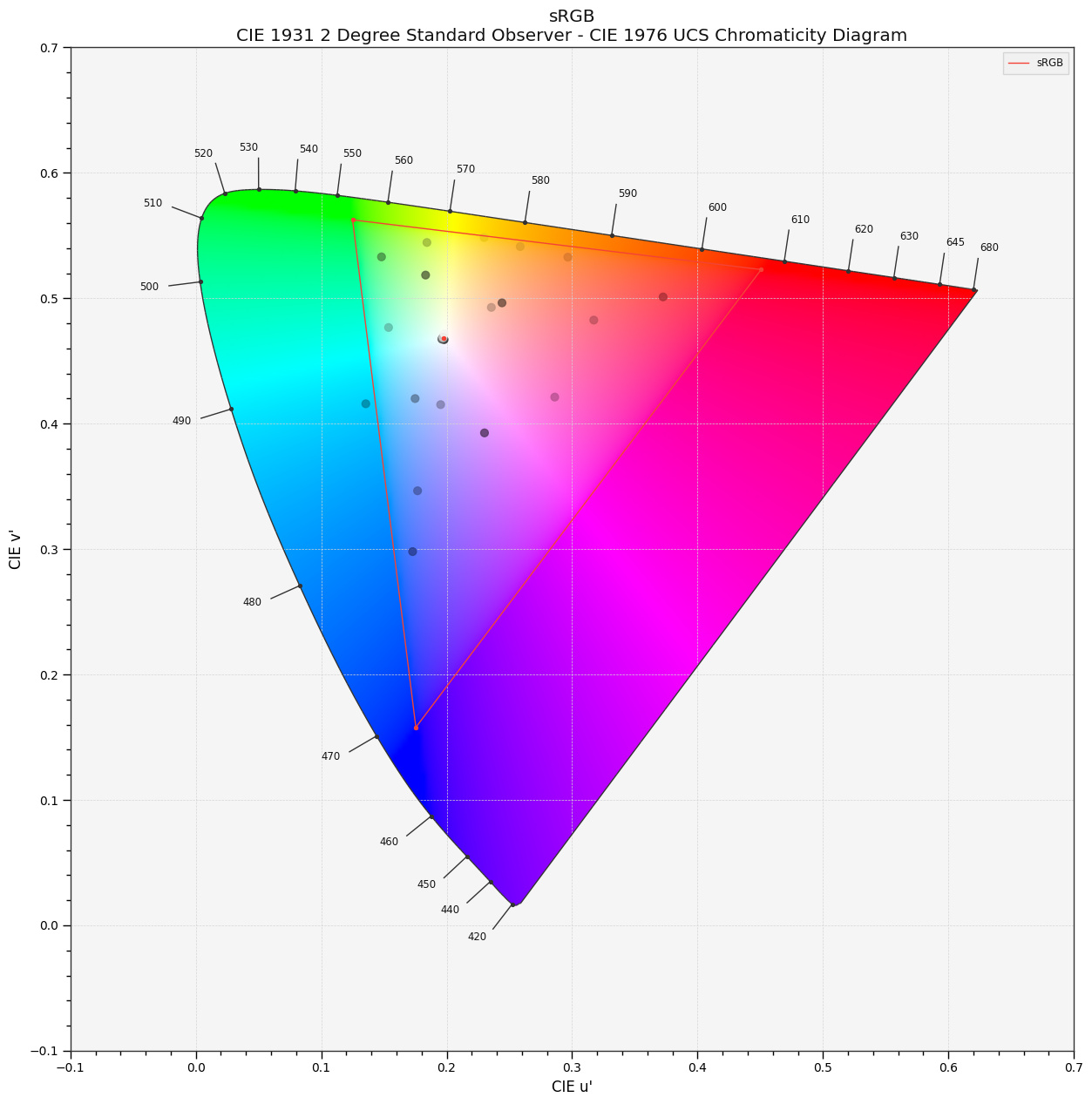
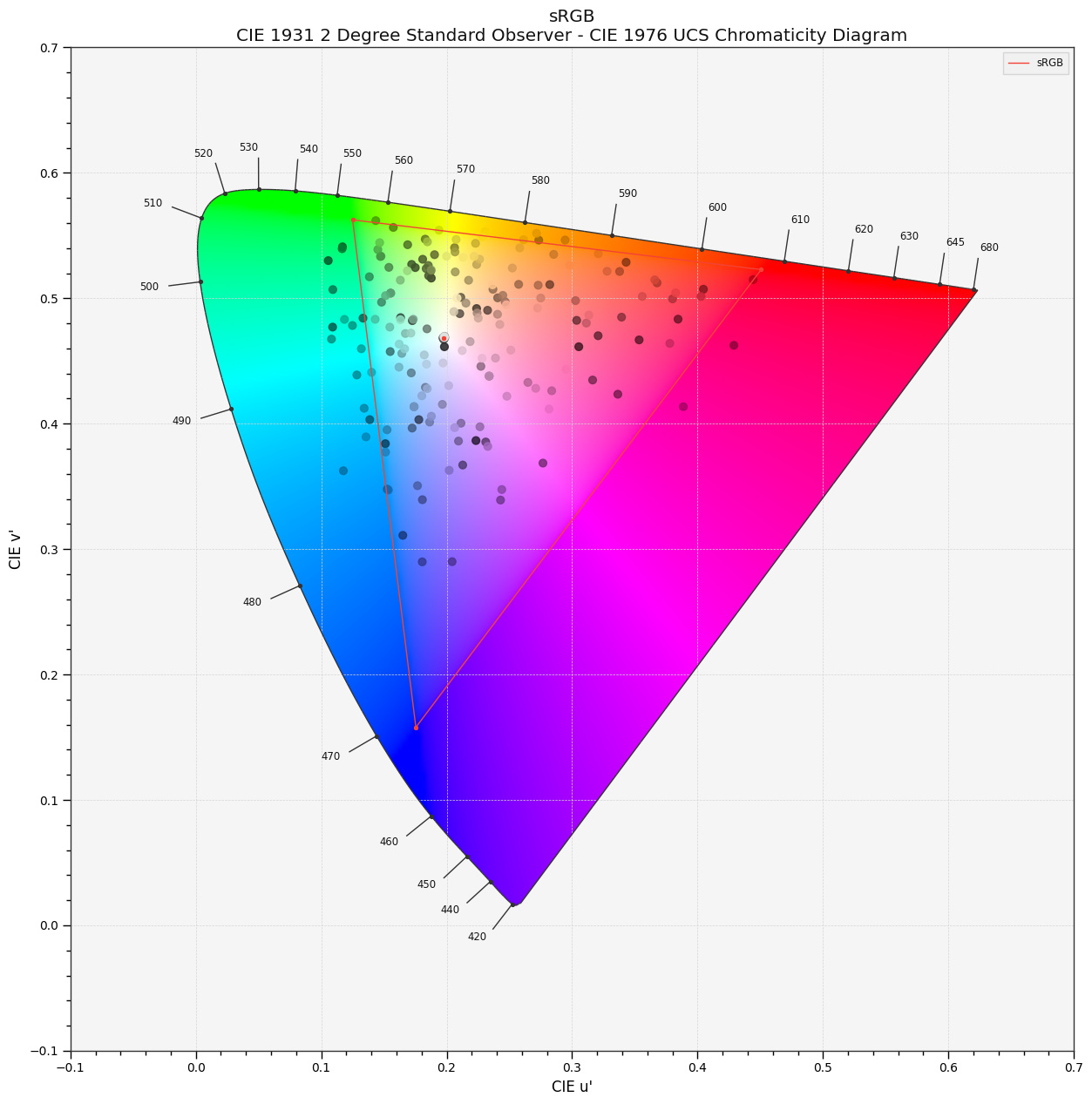
This was the long-and-short of what my initial investigation was digging into. We seem to have settled on a a consensus that we won’t use perceptual models (CAMs) to guide the mapping which I would agree with, but I haven’t seen a discussion specifically around what we do instead. It seems there is unspoken agreement that we need to map along a dimension of saturation/purity (perceptual, physical, or otherwise) and preserve some concept of hue (perceptual, physical, or otherwise). So I think it would be good to pull this topic to the forefront and work towards an answer.
What is the boundary of the zone of trust?
This question assumes that we all agree on the “zone of *” concept, which seems to be the case? If so, what defines the boundary? Is this boundary static or dynamic?
What is our metric of success?
I’d break this down further into two categories.
First, when we’re testing answers to the above questions, how are we judging good versus bad solutions? I don’t think there is any question that subjective judgements will play a role, but are there objective measurements could we think of?
Second, when do we know the VWG is successful? When we solve very specific real-world problems? If so, which ones? Is there a way to implement test-driven development? Are there specific tests we can perform to know we’re done?