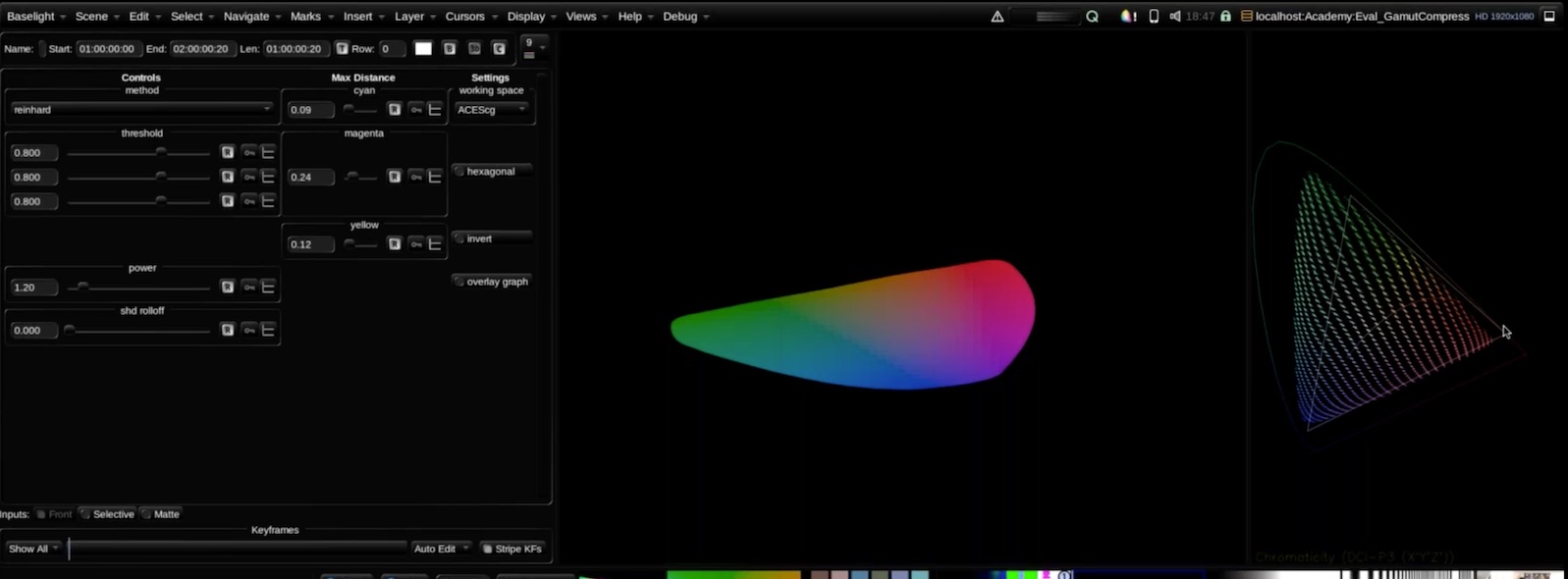
I wonder if when we send it out for broader testing we should just have equal defaults of e.g. [0.2, 0.2, 0.2] and let people form their own opinions on what good values are. Currently there is a tendency to just leave them at Jed’s defaults.
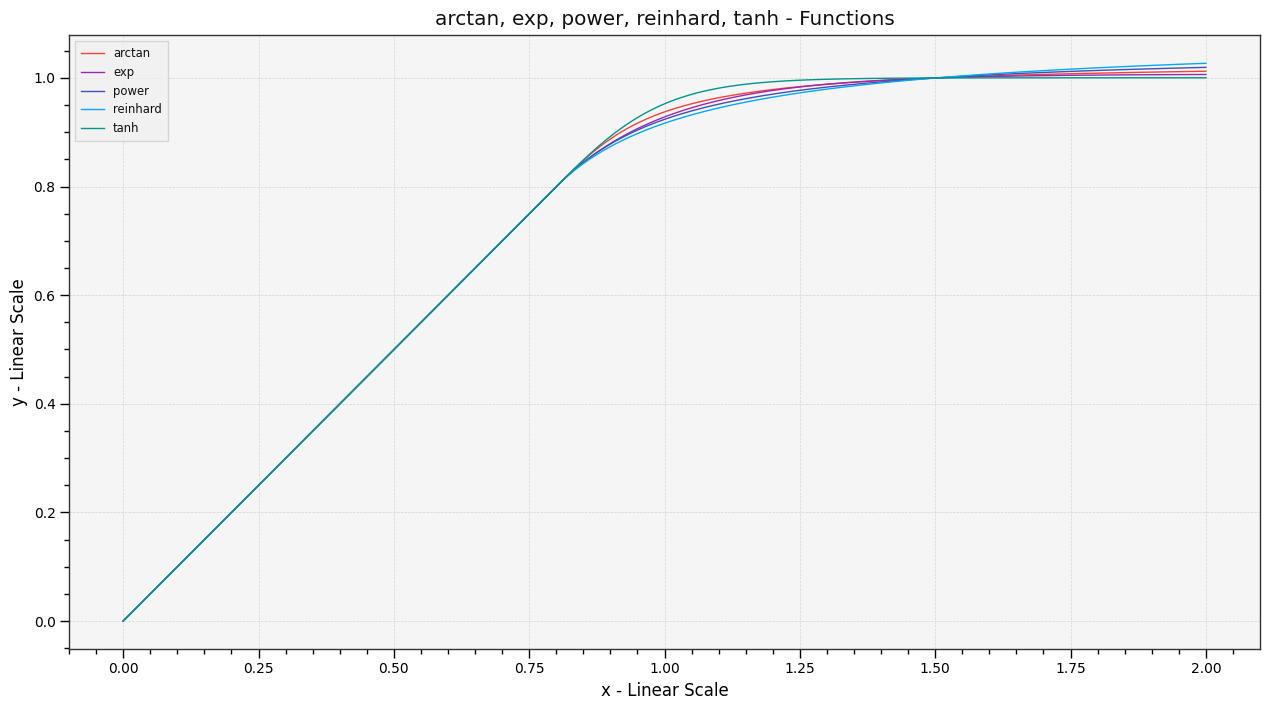
We can fiddle with the parameters and re-run, I will probably make some sliders later but I’m confident that we can fit a lot of scenarios while producing results that are orders of magnitude under the detection threshold.
Cheers,
Thomas
PS: @Alexander_Forsythe: I humbly request a badge for being the first non-Academy person to use the new LaTeX feature!
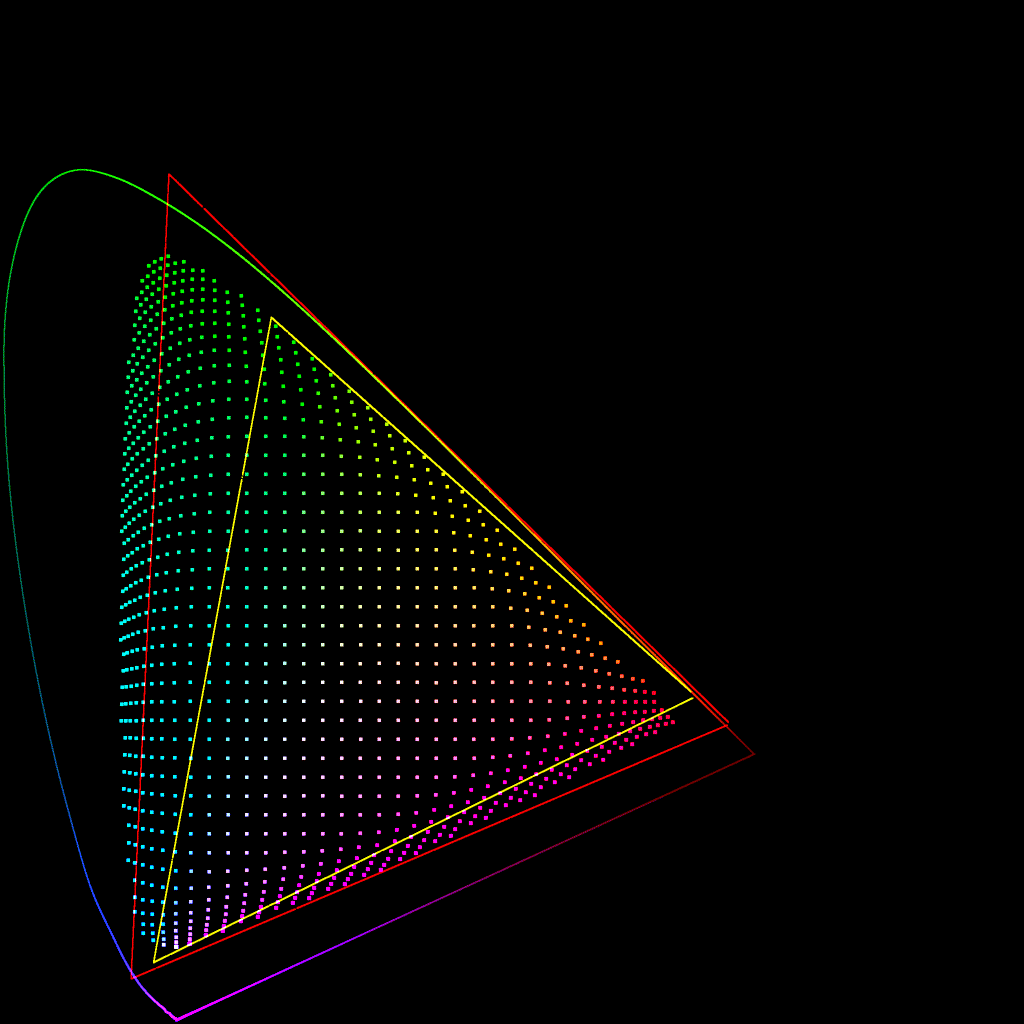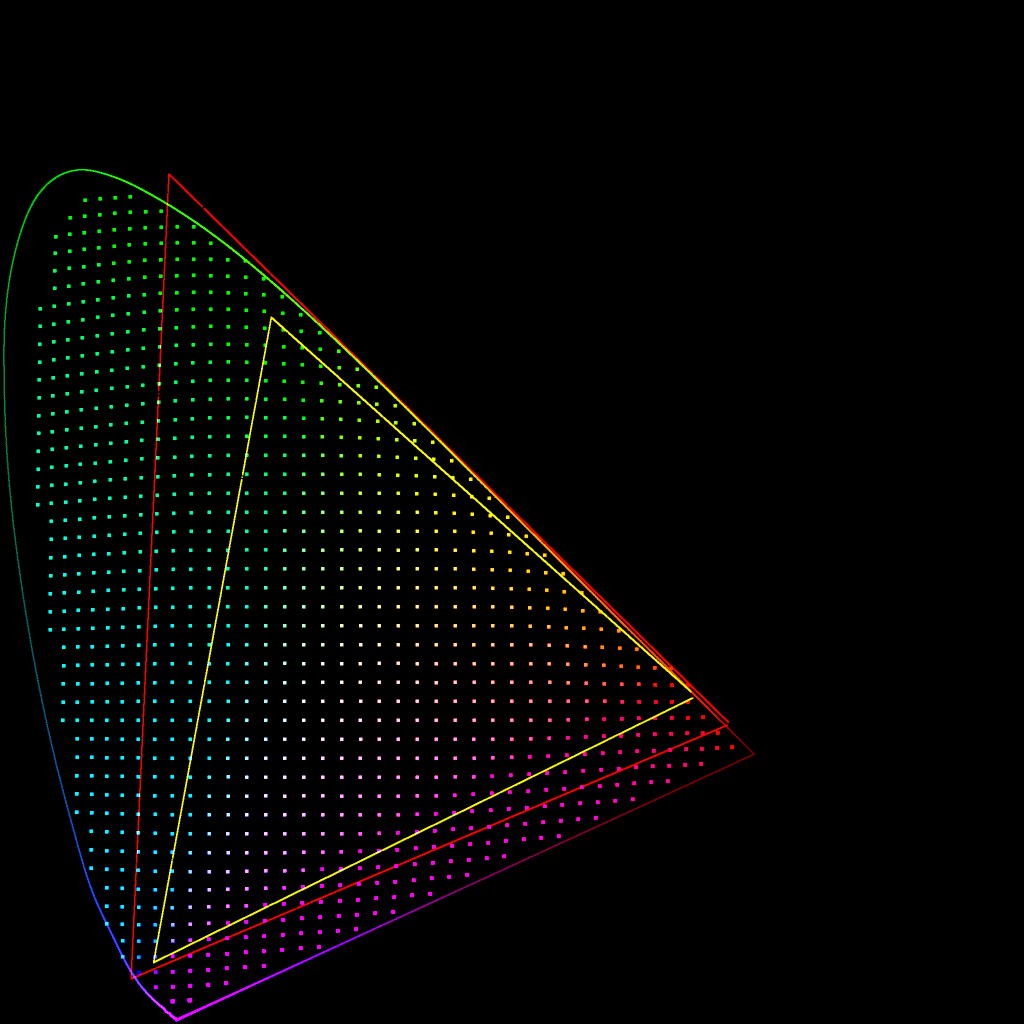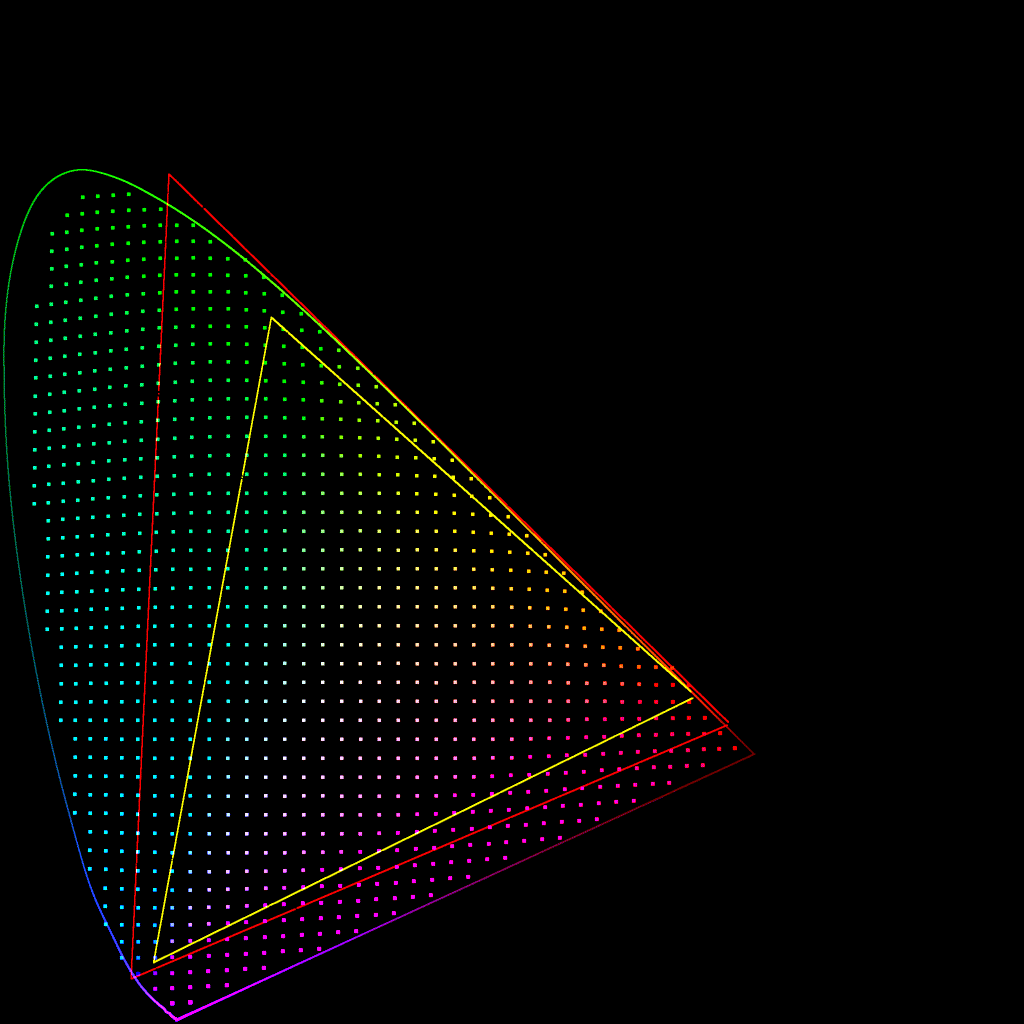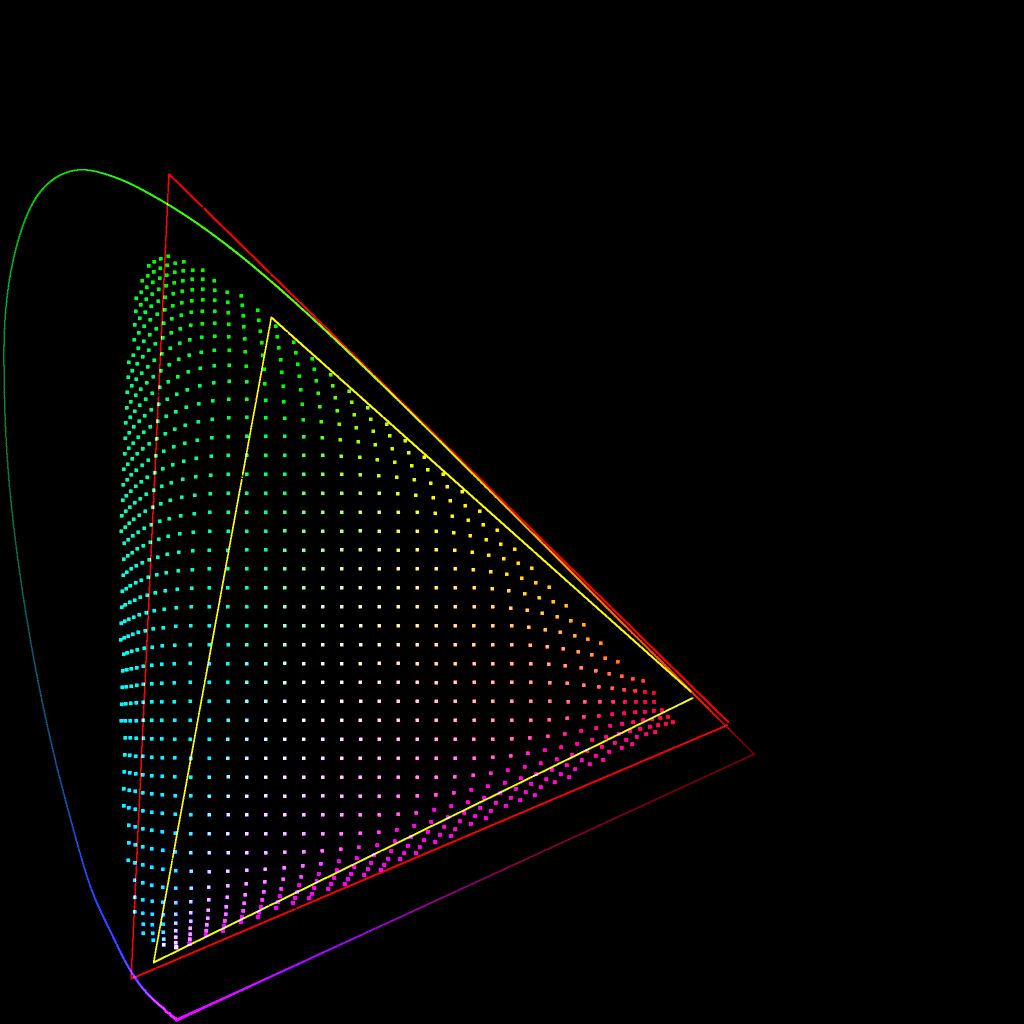
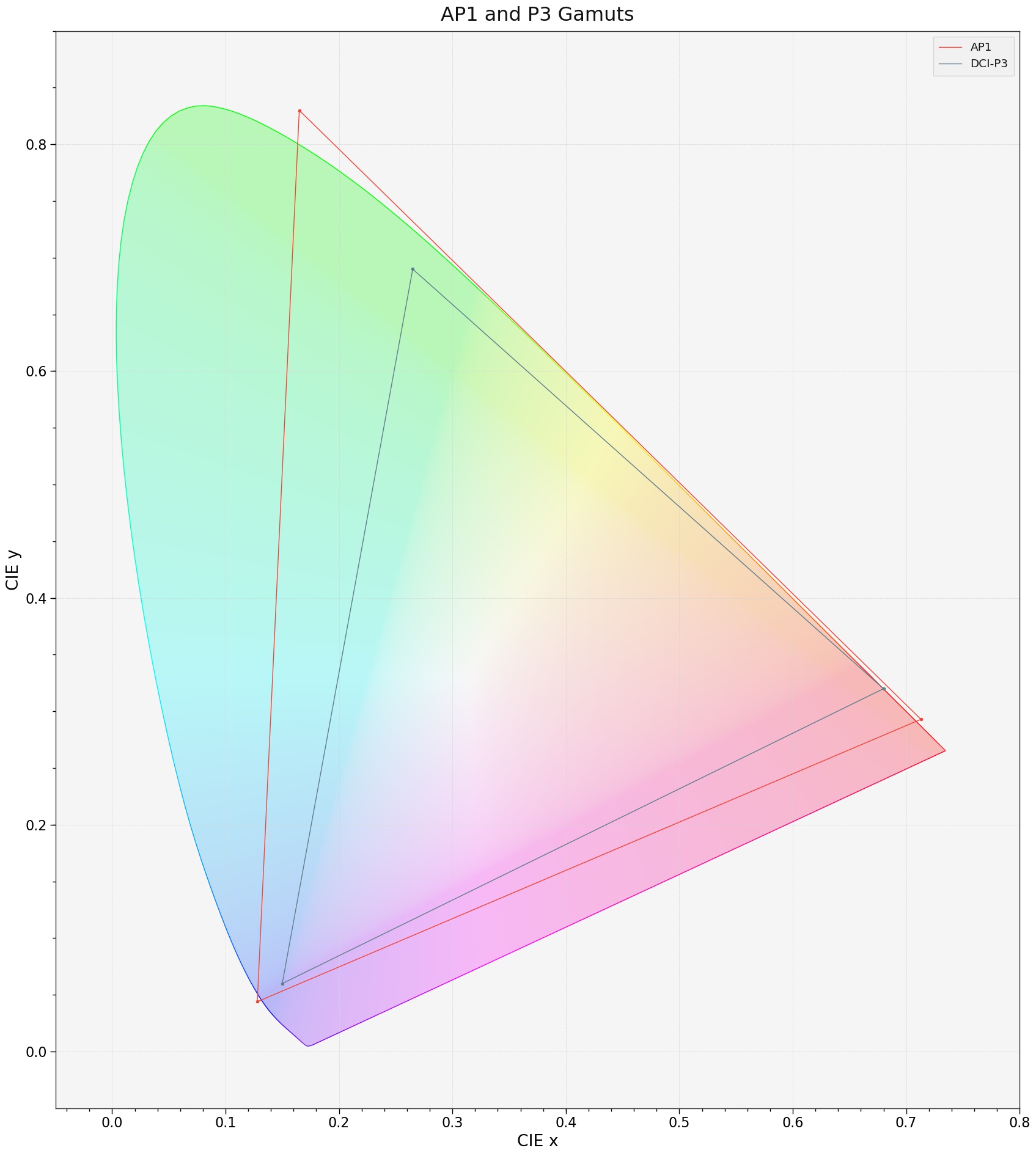
@daniele brought up during the last meeting that the gamut mapper compresses the area of the spectral locus such that there is a ‘slice’ by the P3 red primary which is empty. This is also the case, to a lesser extent, with the P3 blue primary.
But thinking further about it, I believe this is inevitable with any gamut compressor. Since the red to green edge of the AP1 gamut lies hard up against the edge of the spectral locus, if the compressor is to bring colours outside that edge to within the gamut, it is inevitable that colours on the edge need to be ‘pulled in to make space’.
So a value can only end up at the P3 red primary if it starts outside the spectral locus.
We should also remember that if the gamut compressor is applied just after the IDT, then subsequent grading is still able to push a colour back to the P3 red primary if that is creatively desirable.
Yes, this is also true for BT.2020 which makes it even more important to be able to remove/disable the operator if highly saturated colours are desired.
It seems likely the consequence of doing the compression in ACES RGB space. This is exactly why a lot of gamut mapping is applied in spaces that attempt to be uniform like CIELAB or CIECAM-UCS. It would be interesting to think about ways to translate the ACES values to the destination space first and compress relative to those RGB primaries as our goal is slightly different as a scene-referred gamut mapping and we want to fill the destination space. Just musing … obviously the math gets tricky.