This is so elegant and simple it makes my brain hurt. Thanks so much for sharing this @daniele!
After a lot of fiddling about, I managed to figure out how to fake a log-plot on the x-axis on desmos (I made a simple acescc function with x stops above and below 0.18, then ran the functions through that).
As usual, I can’t understand anything until I implement it as a Nuke node… so here’s a rough implementation of your math if anyone wants to experiment with it.
EDIT updated to fix bug with blue channel, and including inverse
ToneCompress.nk (2.2 KB)
Also as usual, I’m gonna swoop in with some stupid questions.
Over the weekend I did some reading on HDR, trying to learn a bit more about it. I read ITU-R BT.2390-8 and ITU-R BT.2100-2 among a few other things. I still don’t feel like I have a good grasp of the rendering side of it.
So, stupid question number 1:
- If you specify peak luminance in nits, is there any reason why normalized white would be different than peak luminance? Are there certain variants of HDR (all?) where these two should be different? To phrase the question another way: Should peak luminance be mapped to display linear 1.0 always, or not? (Maybe this has to do with the inverse EOTF?) (Maybe this is a useful parameter to limit the max luminance? Say if you wanted 600 nit peak brightness on a 1000 nit display?)
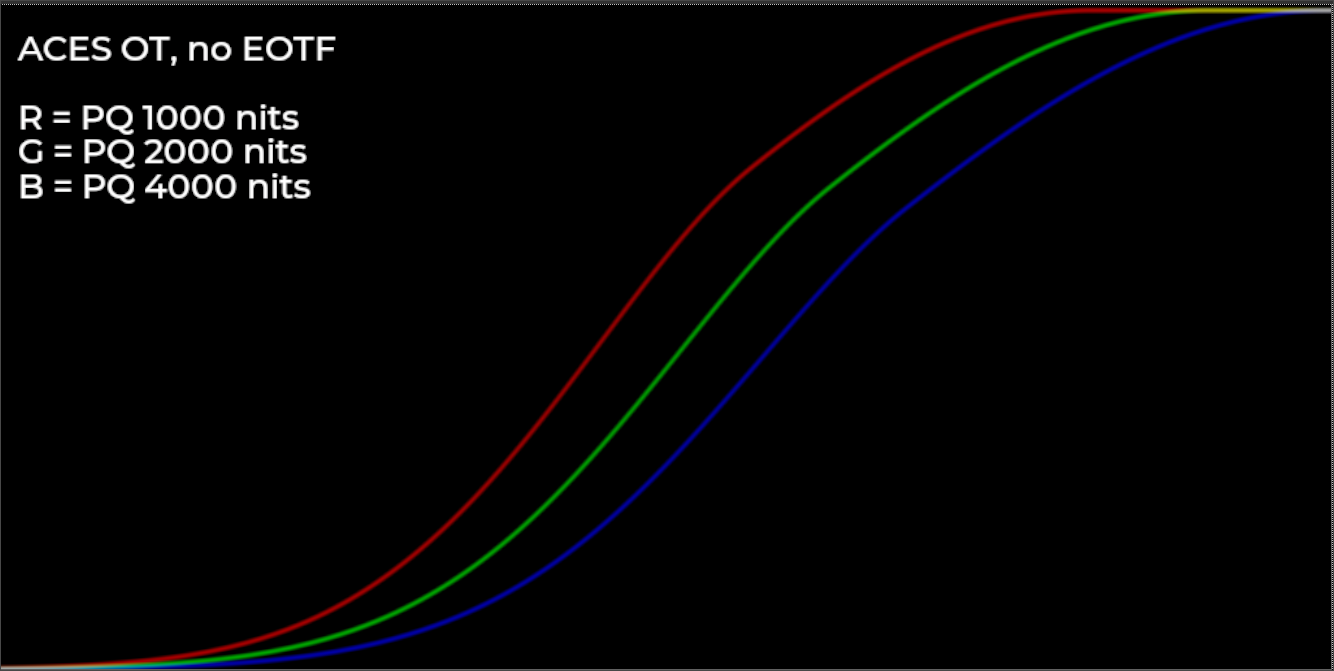
If I interpret the ACES Output Transform correctly (this being my only open-source reference point for HDR display rendering), it looks like the only difference between the 1000, 2000, and 4000 nit variants of the Rec.2020 ST-2084 PQ HDR Output Transform is an exposure offset of the tone curve, similar to what the “Exposure” adjustment in your equation does. (Although I might be missing something here).
Stupid question number 2:
- Do you feel that a simple power function is sufficient for surround compensation? I spent a while digging around in papers from the 1970s trying to find the actual math for the Bartleson-Brenneman equations, which you mentioned in one of your talks for Filmlight… But I was never able to implement it fully to compare with the (seemingly) more common power function.
Stupid question number 3:
- When you boost the shadow toe flare/glare compensation, it lowers the asymptote of the curve by the same amount. Is this by design, or is there a normalization factor to counter this toe adjustment missing?
Finally, a few naive observations:
- It is super interesting from a simplicity standpoint to not have to wrap the a sigmoid in a log domain transform and then jump through a bunch of hoops to go back and forth between linear and log domains.
- It is really helpful (at least for me) to see what a proper parameterized formula-based implementation might look like. I’ve been shooting in the dark a bit with my experiments, and this is useful to shape my thinking (in addition to being just plain useful).