In an effort to tackle a narrow portion of the complex topic this working group is engaged with, I would like to discuss here the Tonescale.
The way I see it, the Output Transform should consist of a few different modules:
1). Tonescale: Compress dynamic range from scene-linear to display linear.
2). Gamut Mapping: Map hue from source gamut to display gamut. Perhaps there is some default rendering decisions in here as well such as desaturation of highlights, shadows, etc.
3). Display EOTF: Apply the display transfer function. Perhaps there are other things in here as well such as surround compensation.
In the current Output Transform, 1 and 2 are intertwined because the tonescale is applied directly to the RGB channels. (Not to mention the 2 saturation matrices applied before and after the tonescale). This is problematic because hue is not exposure invariant (brighter blues turn purple). It also adds complexity.
I’ve included options for different norms, so that we compare the differences in how the norm affects the image rendering.
Luminance - Rec.709 luminance weighting.
Max RGB - Calculates norm with max(r,g,b)
Weighted Power - Uses the weighted power norm described in Doug Walker’s talk. Options for basic 1.0 weights, and for the weighted yellow power norm coefficients.
There is no gamut mapping applied here. So it’s ACEScg directly to display.
Because the tonescale is hue invariant, it’s possible that gamut conversion and hue alterations could be done before the tonescale in the scene-referred domain, or after the tonescale in the display-referred domain.
Another concern would be how to make saturated highlights look bright again. This process renders saturated bright highlights with a very dim appearance. How could we control saturation of highlights (and maybe shadows too) in a simple way?
A ratio preserving tone curves gives us a lot more control, but we may need to develop some methods to recreate the aspects of the previous rendering that we have lost with it.
I preface this series of questions with the fact that I have no idea what anyone means by “tone”, let alone “mapping”. I’m sure there are people facepalming.
I’d dearly appreciate it if someone could explain what the X input axis is and the Y output axis is?
1.a How is this relationship related to “tone”?
Isn’t the point of an aesthetic transfer function to perform a compression of an input gamut volume along X to an output gamut volume along Y?
2.a In this case, isn’t the “dimming” exactly as expected?
2.b If this is expected, is there an error of logic with respect to the dimension of the input X range?
2.c Is there a limit to the display gamut volume range of expression of output Y?
2.c.1 If there is a potential limit, is there a means to glean a maximal quantization increment with respect to input X and output Y?
2.d Are there quantization limits at both the upper and lower end impacting the expression of a given radiometric-like chromaticity and / or perceptual hue?
With respect to norms, how does this relate to the aesthetic ground-truth of the past century of photographic media?
3.a Wasn’t film explicitly radiometric electromagnetic energy transformed into chemical energy?
3.b What happens with high energy radiometric-like saturated mixtures with respect to high energy, lower saturated mixtures?
3.c If there is a difference in 3.b, does this create a cognitive dissonance with respect to the typical aesthetic ground-truth of the past hundred years of photographic media?
Again, tremendous work.
PS:
Assuming the luminance is used as the input lookup value, it would seem the magenta skew might indicate that the decompression is being applied incorrectly in the luminance norm case?
It might be informative to see how non-maximally saturated values translate to each approach?
Side note: I’ll continue to use the term “tonescale” in this post, because it is what is used in the ACES CTL. I remember using the word tone to refer to sections of the exposure range back in college developing black and white film negative in the darkroom. I do agree the term tone is a bit ambiguous though. If there is a more appropriate term to refer to the process of compressing scene intensity to display intensity, please let me know.
A Decision Taken For Granted
Implicit in my previous post is the assumption that we had collectively decided to use a chromaticity-preserving “tone scale”. Maybe that’s not the case, or maybe we haven’t fully evaluated the implications of the decision.
For me it seems that this is the first decision that needs to be made, because every step after follows from this.
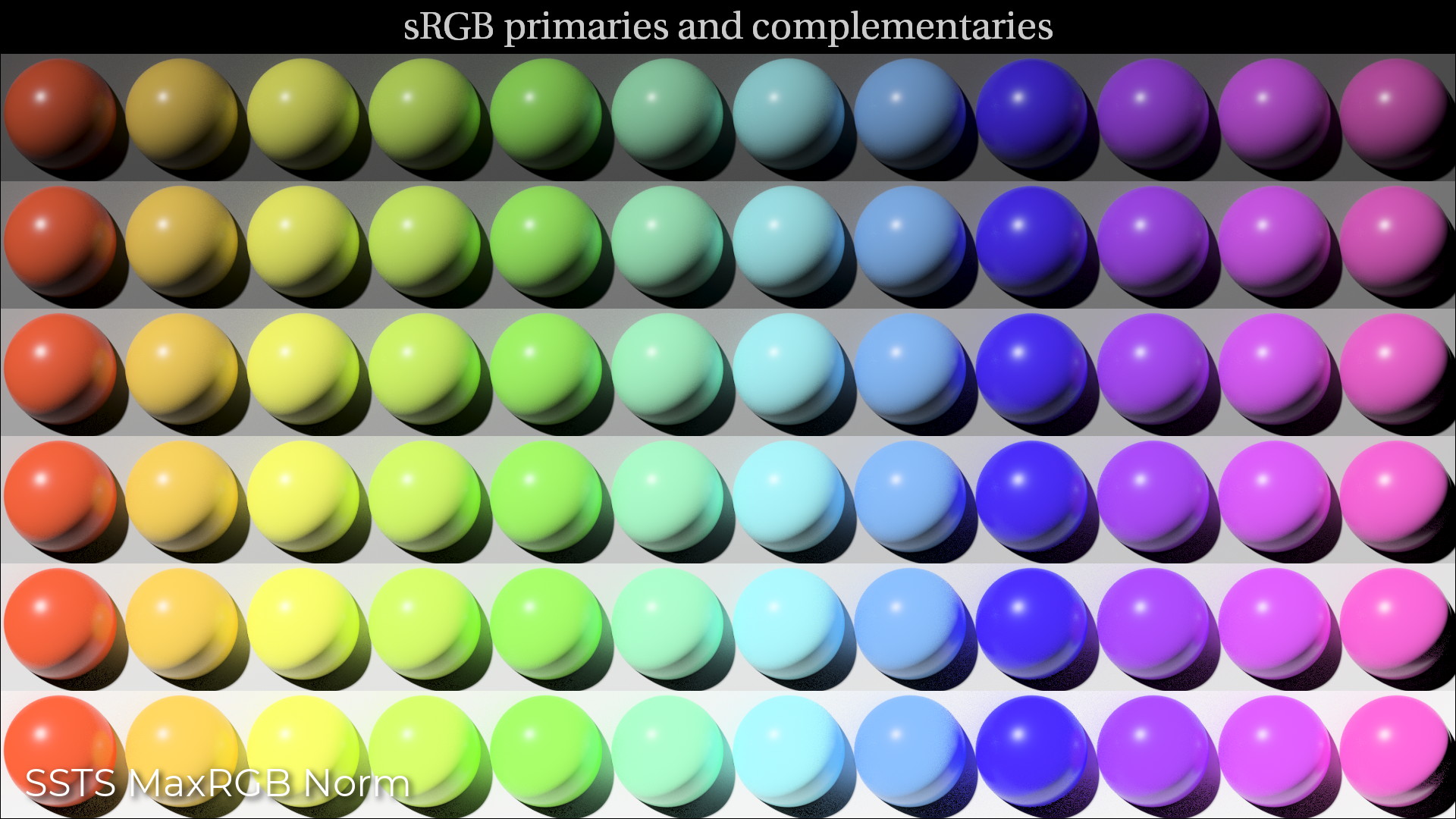
The reason to use a chromaticity-preserving tonescale is clear to me. Input chromaticity matches output chromaticity. Here are some pictures to show visually what that means.
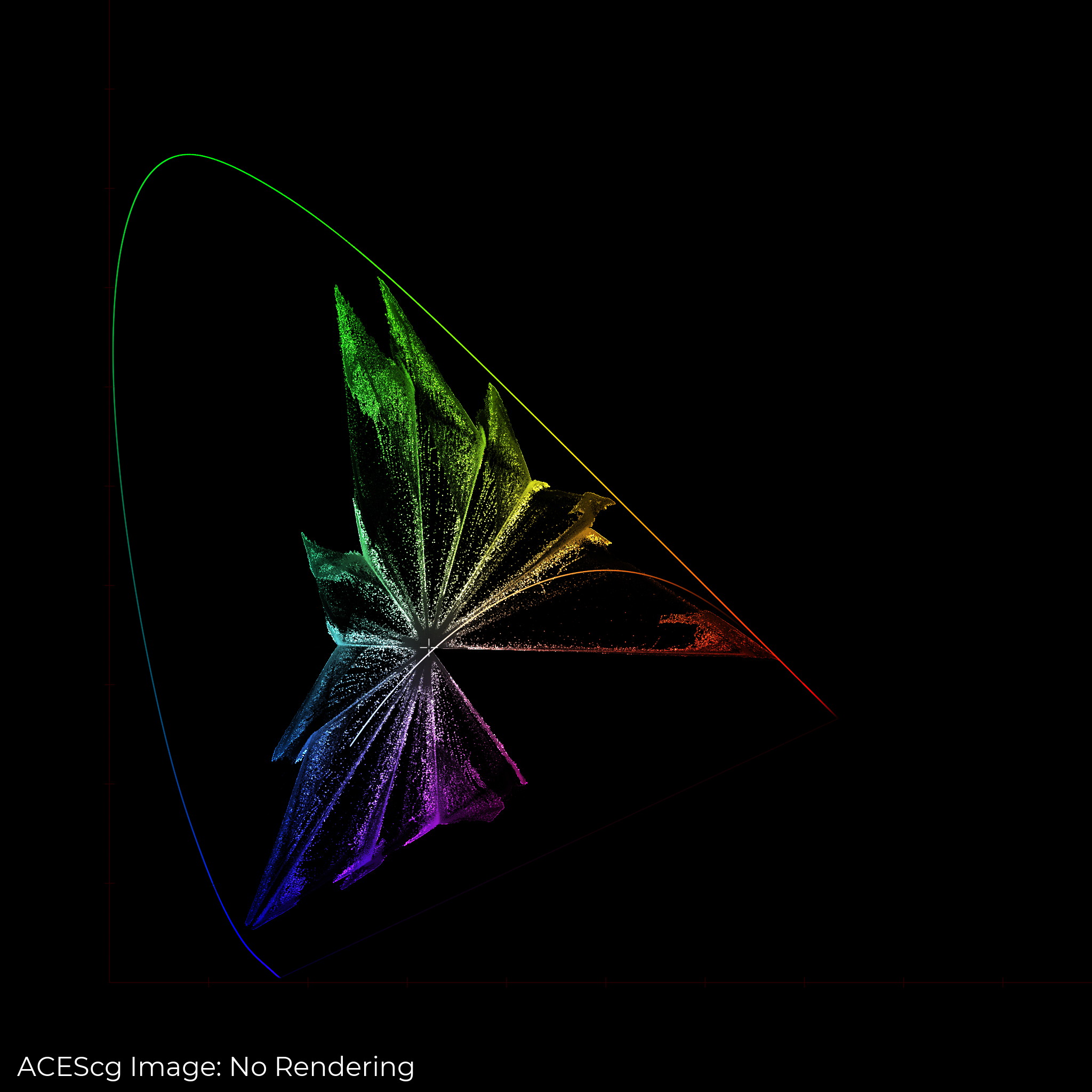
Here’s an image which shows what I mean pretty well. @ChrisBrejon’s cg_sRGB_spheres_001_aces.exr.
Shown above is the image in acescg rendered directly into a jpg and uploaded here. No tonescale applied.
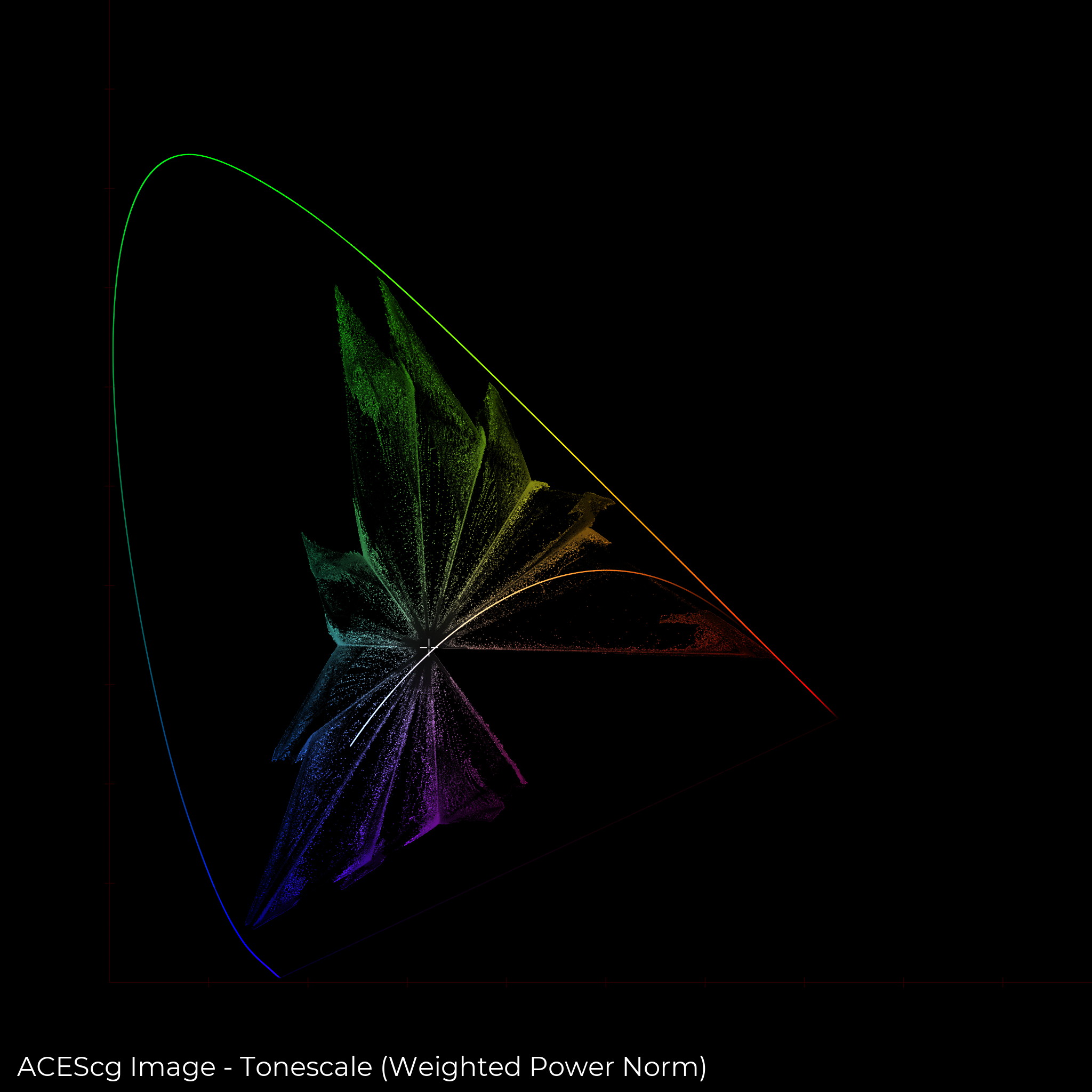
And here’s the same image using the Weighted Yellow Power Norm tonescale. This is using the ACES SSTS algorithm. Note this is display linear, no display EOTF applied.
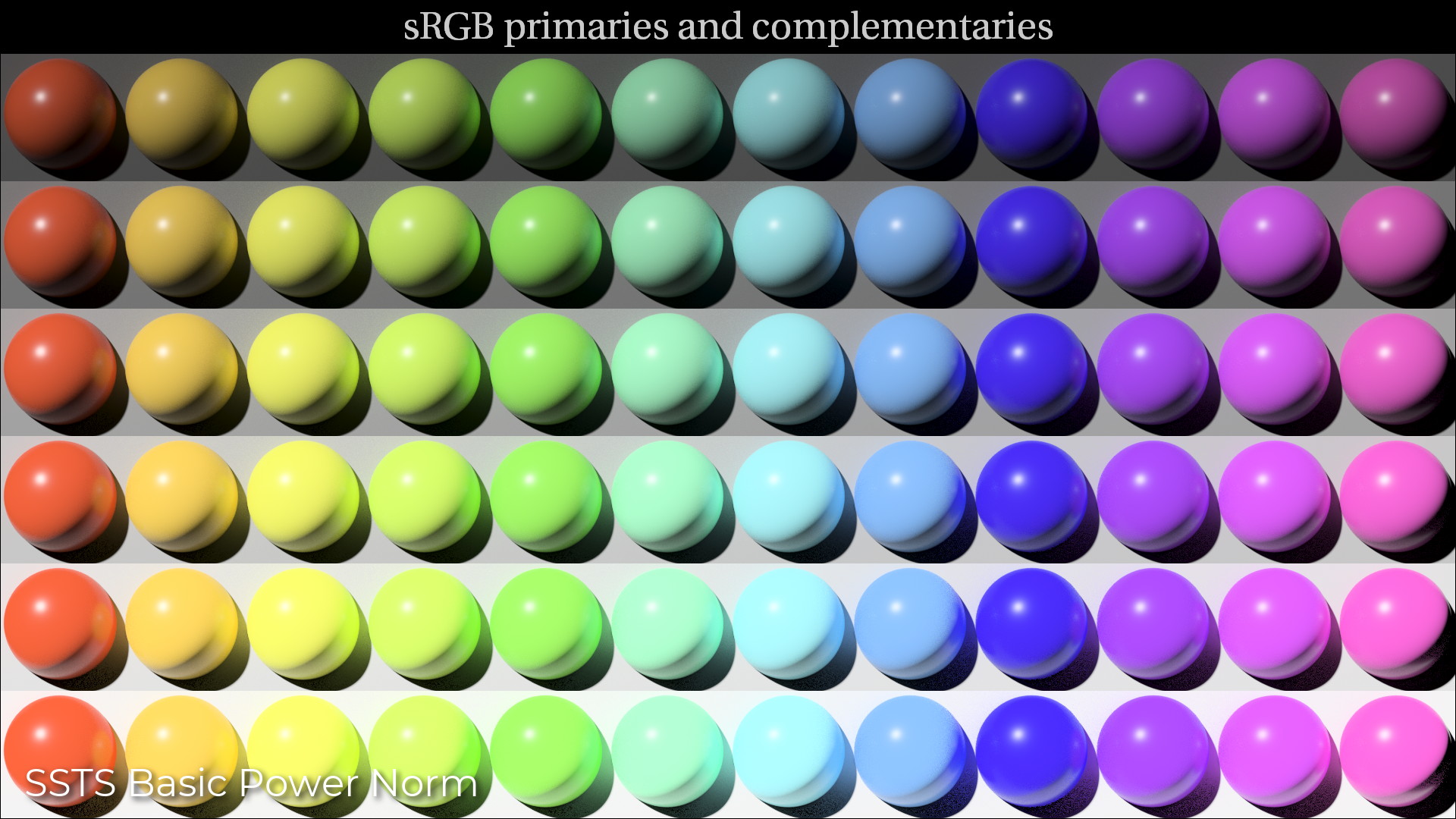
It is clear that a norm-based tonescale does not alter the chromaticity of the input image. And that an RGB based tonescale is doing all sorts of things, some nice, some not so nice.
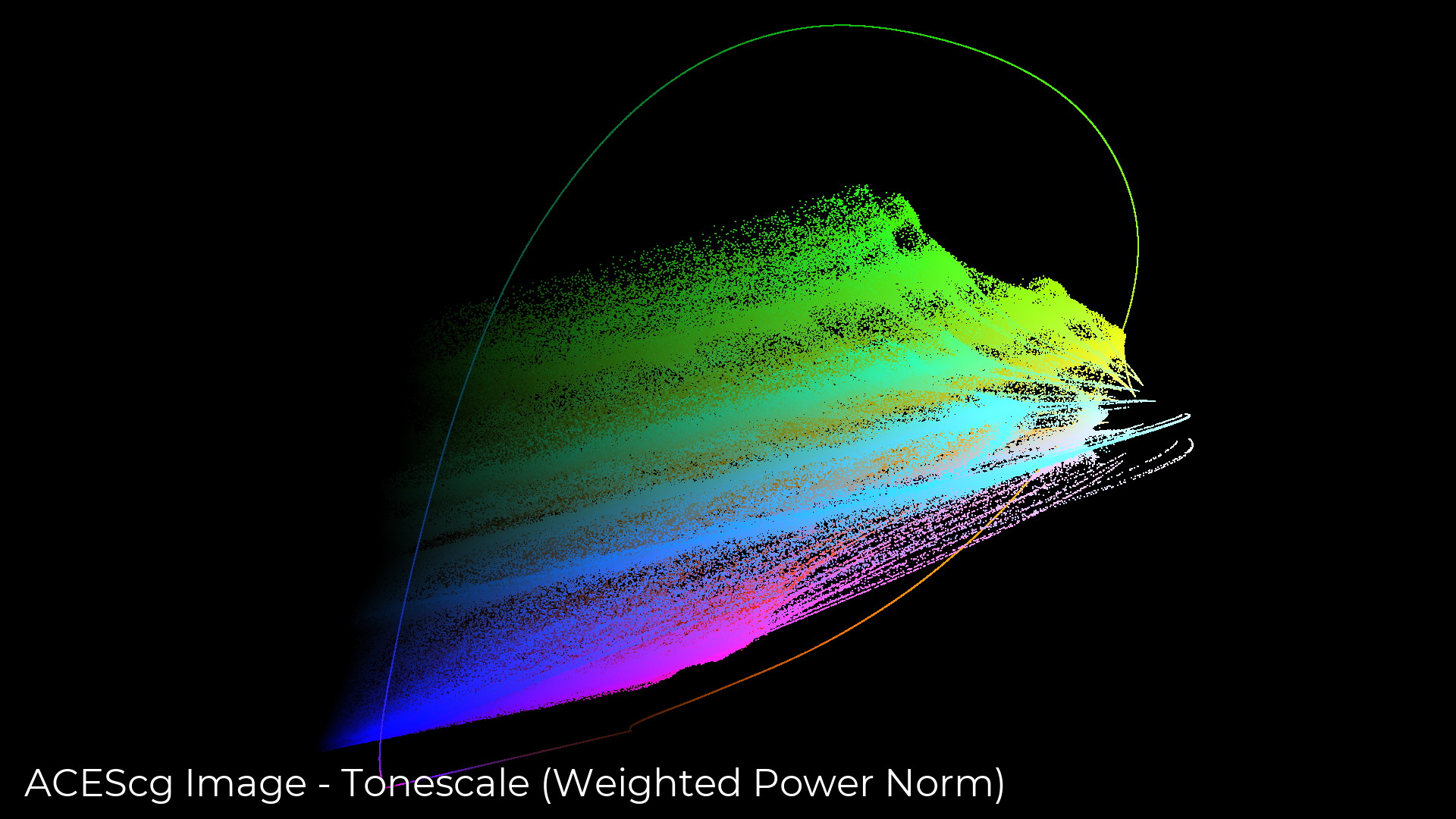
Looking at the same image from a roughly 45 degree angle, we can see what is happening to saturation over the range of brightness. In the RGB per-channel approach, saturation approaches 0 as brightness approaches the maximum code value or 1.0 in display-referred. The problem is that we have no control over the way that this happens.
From Which Place Do We Start
If we were starting to build a display rendering transform, I personally would much rather start from the result of the norm-based approach, because I have control over what is happening. If we started from the per-channel approach, sure there are some nice looking results, but there are also some not-so-nice looking byproducts which would be very difficult to reverse later on.
If we all agree that starting from a chromaticity-preserving tonescale is the desired method, then we could move on to talking about how to emulate a look. For example, what are the aesthetic characteristics that we would like to preserve, and how do we make that happen.
I’m going to make another thread about gamut mapping and throw out some ideas for some things.
A Question: Proper Handling of EOTF?
One question I do have for some of the smarter minds than my own is should the display EOTF be included in the chromaticity-preserving tonescale? That is, should the display EOTF desaturate and change chromaticity values when it is applied, for example if a gamma 2.4 transform is applied for Rec.709, or should compensation for this desaturation happen before?
I’m getting rather nice results with an order of operations that looks like this:
Gamut compression -> Tonescale to display linear -> 3x3 Matrix to convert to display primaries -> Display EOTF
But I would be curious to hear thoughts on this.
Edit: Here’s the nuke script used to generate these images.20190119_tonescales.nk (681.7 KB)
Thanks for your post @Troy_James_Sobotka. Your questions helped me frame some of my thinking about this topic.
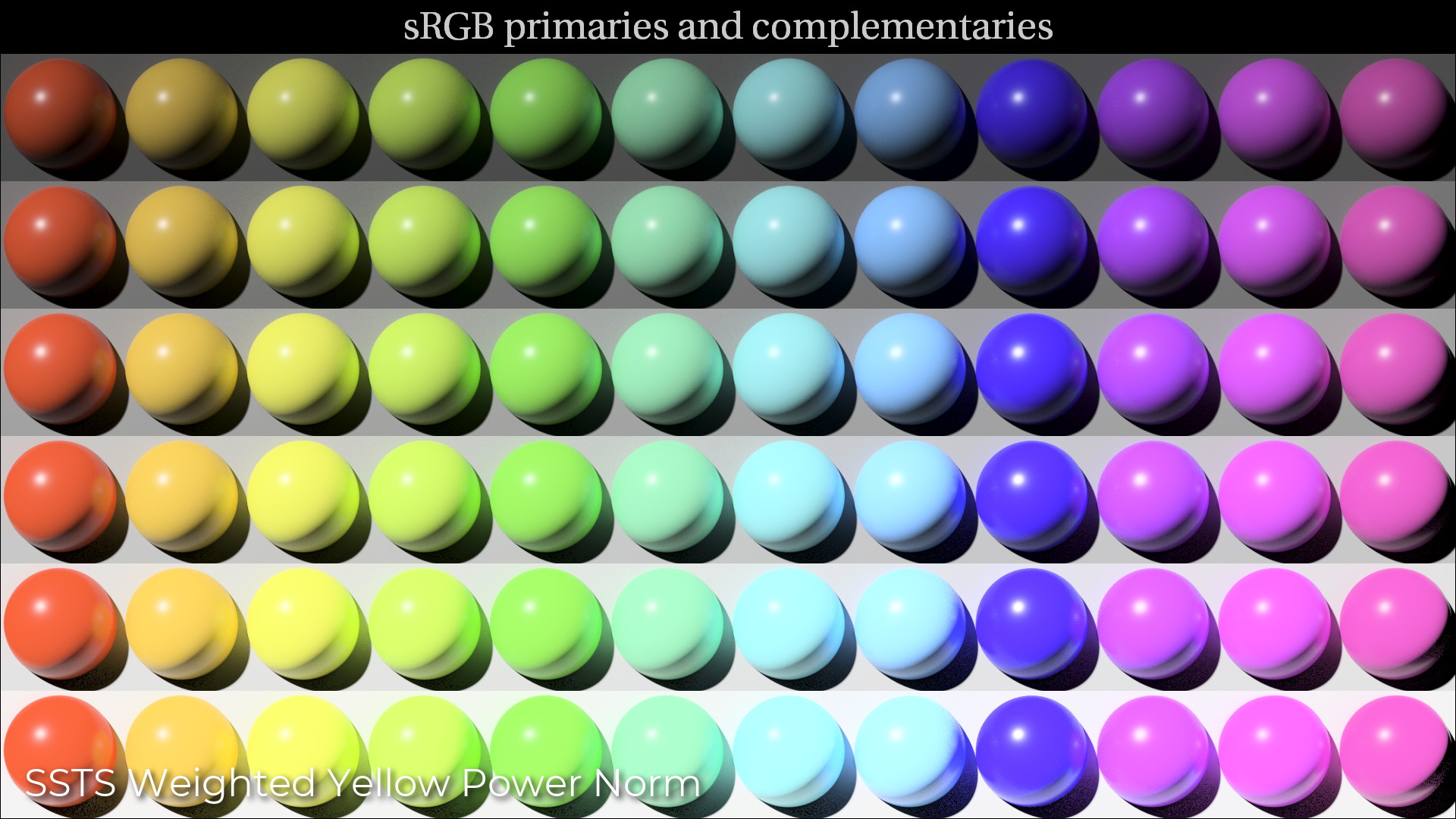
Apologies, my image was a bit misleading for the Luminance Norm examples. There is no chromaticity shift with this approach, but the image after tonescale has values > 1.0 in the blue channel, which got clipped and caused an apparent magenta hue in the jpg.
After quite a bit of testing, I really like the behavior of the weighted power norm approach. Adjusting the weights allows good control over the brightness of different hue ranges without changing chromaticity, and would allow for another point where an aesthetic decision could be made.
The issues with all non-radiometric like norms is that they add a convolution on top of the curve. As in the meaning of the curve is not clear, because there is another energy “balancing” at work, which will distort the curve at various points, calling into question the whole idea of a single curve to begin with.
Wiser minds can probably plot this issue without breaking a sweat.
While we certainly played with the maxRGB concept during the development of ACES 1.0, Doug’s Weighted Power algorithm came after.
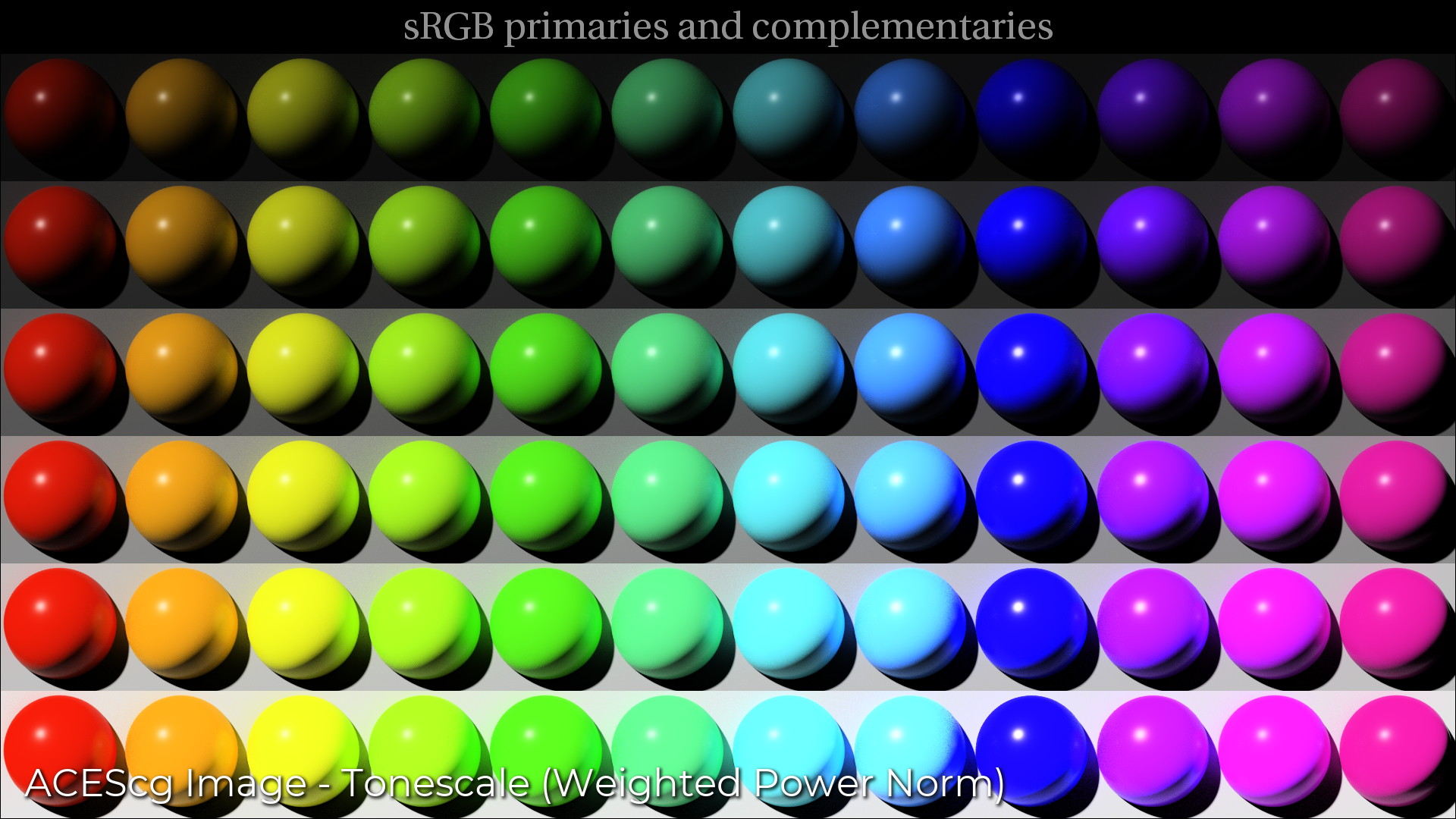
Just for kicks, I applied it to some of the ACES 1.0 test images. Interestingly, it produced similar pictorial results to the maxRGB that caused us to move back to RGB tonescale methods in the current ACES system. rgbMax and weighted power certainly do a better job at preserving hue invariance as exposure increases, but as you noted, the saturated, bright highlights are certainly a less-than-desirable side-effect. We noted that highlights don’t desaturate until the source is clipped regardless how high their radiance is.
In the end we came to the conclusion that you hue linearity and saturation are desirable … unless they aren’t.
Each of the following images was rendered using @jedsmith nuke script referenced above using the weighted power option with yellow weights and the BT1886 EOTF
Retaining hue linearity and saturation looks good on neons and tail lights
Exposure sweep of MacBeth Color Checker lifted 10 stops in ACES linear space (ACES * 2^{10}) - Nothing blows out unless the source data converges in all channels as happens with camera clipping.
In my mind this is likely a question of if HDR and SDR (and DCI) will need different treatment of the highlight desaturation. A “universal” desaturation would clearly be ideal if it works across the board.
How “convoluted” are we talking? Invertibility seems high on the priority list, but I don’t think that necessarily restricts us to a simple curve if it can reasonably be undone (although I infer from your post that you think we’re beyond that in this model).
This was a bit of a brain-fart stupid question on my part, which was quickly clarified by multiple people in the last meeting.
To summarize: The display EOTF transform should not preserve chromaticity values. The EOTF applies a temporary encoding as the image is sent “across the wire” to the display. At the display, the opposite of the EOTF is applied before the picture is rendered on the screen. In fact, as @doug_walker pointed out in the meeting, the display EOTF should probably more accurately be referred to as the “Inverse EOTF”, because it un-does the transform which the display later applies.
Long story-short, if the “Inverse EOTF” is applied properly, the radiometric display-linear code values just previous to the “Inverse EOTF” transform will be displayed exactly the same as light emitted from the monitor.
Agreed. Desaturation should be a function of the compression curve rather than a separate operation. Exactly how is an open question though
Except it is a different medium to film, no? What does a “tone” mean here? Is it somehow different to the double duty that a density plot represents with film?
It’s a shifting nonlinear result underneath a nonlinear curve. This would seem to make it nearly impossible to comprehend the meaning of the curve in question, given the plot is nonlinear that it is on top of?
Yes, in the perfect world with no performance, energy or bandwidth constraints, the EOTF is not required, e.g. a full floating-point display chain. Generally best to leave it alone and think about it as a no-op even though it is not necessarily strictly the case. Put another way we do have an EOTF mostly for (good) cost reasons.
I have been doing a bit of research and experimentation in the domain of tonescales. Specifically, simpler formula-based alternatives to the spline approach used in the ACES SSTS. Full disclosure, I’m embarked on this adventure partially because I am too dumb / don’t have the knowledge yet to implement splines myself. And I find their complexity a bit overwhelming, and have the gut feeling that there are simpler alternatives.
I will share here a few things I made along the way in case anyone finds it interesting or useful.
Hable Piecewise Power Tonemap
One of my first experiments was diving into John Hable’s Piecewise Power tonemap, which was discussed previously by @Thomas_Mansencal. I was intrigued by the (relative) simplicity of the piecewise power curve fitting, but I didn’t really understand how it worked on a mathematical / technical level. So I decided to implement it myself starting from scratch.
Above is a link to a desmos implementation. I have changed the parameterization a bit from what is proposed by Hable. The parameterization expresses
The linear section pivot as an xy coordinate
The slope of the linear section
The shoulder and toe linear section length
The shoulder asymptote position as an xy coordinate
The toe asymptote position as an xy coordinate (Note that the Hable implementation assumes a 0,0 coordinate at the origin, and is thus a bit less flexible).
I also added an inverse transform based on the same parameterization.
This s-curve would be applied in a log domain.
There is a Nuke implementation here, and a blinkscript version here.
The big downside of this curve is that it’s not possible to control the slope or behavior of the shoulder, and the shoulder tends to compress values too much as it approaches asymptote. One can work around this by adjusting the shoulder asymptote xy position, but it’s tricky and doesn’t work super well.
PowerP Sigmoid
Frustrated by the Hable shoulder, I decided to embark on an adventure in math to make my own parameterized sigmoidal curve using the Power( p ) compression function that @JamesEggletonposted here. After a couple of weekends learning calculus I finally figured out the math to solve for the intersections, and made this:
It has similar parameterization for the pivot, and toe / shoulder linear section length.
Has “power” adjustments for both shoulder and toe compression curves.
Has a solve for shoulder limit and toe limit, to specify what x value crosses y=1 and y=0.
Has an inverse, (it’s a little buggy in the desmos implmentation but the nuke version works okay)
Note this is pretty similar to the tonescale in the NaiveDRTPivoted node, but all combined into one transform instead of being separate pieces.
The curve is very flexible, but unfortunately I wasn’t very happy with how it looked. I really struggled to get the curve for shadows to look good in images.
Hill-Langmuir Equation
I got distracted into implementing a few more color models in my growing collection, and read Fairchild’s HDR-IPT paper. It mentioned the Michaelis-Menten model of enzyme kinetics used in biochemistry as a way of describing the human visual system response to increasing light stimulus. This is also discussed a bit in the Kim / Weyrich / Kautz 2009 siggraph paper Modeling Human Color Perception under Extended Luminance Levels. I was very curious about this curve because it has almost the exact shape of 1D lut component of a print film emulation lut, and many show luts I have encountered over the years. I was also particularly interested in this curve because of how insanely simple it is.
I chose to use a variation of the Hill-Langmuir formulation, because it provides a bit more flexibility. I solved for the inverse, solved for the y=1 intersect.
I also did a variation with a linear extension on the toe and shoulder, but later thought I probably didn’t need this.
The Hill-Langmuir tonescale is the one I’m using in my OpenDisplayTransform project.
Nuke implementation with the linear extensions available here, and a simpler version with a log-domain wrapper available here.
Here is another one:
It takes scene-referred linear whatever and outputs display-referred linear whatever
It is already formulated so it can be directly applied to images and addresses the whole SDR/HDR problem space.
It is the most simple form I could think of, and it could be expressed in actual a single line instead of the two lines rendering code (which I added for readability).
Invertablitiy is trivial.
It is based around the Michaelis-Menten equation.
It has a gamma model for surround compensation as well,
If you look at it in desmos it does not look like a typical sigmoid, this is because Desmos does not have log ranging axis.
This is so elegant and simple it makes my brain hurt. Thanks so much for sharing this @daniele!
After a lot of fiddling about, I managed to figure out how to fake a log-plot on the x-axis on desmos (I made a simple acescc function with x stops above and below 0.18, then ran the functions through that).
As usual, I can’t understand anything until I implement it as a Nuke node… so here’s a rough implementation of your math if anyone wants to experiment with it.
EDIT updated to fix bug with blue channel, and including inverse ToneCompress.nk (2.2 KB)
Also as usual, I’m gonna swoop in with some stupid questions.
Over the weekend I did some reading on HDR, trying to learn a bit more about it. I read ITU-R BT.2390-8 and ITU-R BT.2100-2 among a few other things. I still don’t feel like I have a good grasp of the rendering side of it.
So, stupid question number 1:
If you specify peak luminance in nits, is there any reason why normalized white would be different than peak luminance? Are there certain variants of HDR (all?) where these two should be different? To phrase the question another way: Should peak luminance be mapped to display linear 1.0 always, or not? (Maybe this has to do with the inverse EOTF?) (Maybe this is a useful parameter to limit the max luminance? Say if you wanted 600 nit peak brightness on a 1000 nit display?)
If I interpret the ACES Output Transform correctly (this being my only open-source reference point for HDR display rendering), it looks like the only difference between the 1000, 2000, and 4000 nit variants of the Rec.2020 ST-2084 PQ HDR Output Transform is an exposure offset of the tone curve, similar to what the “Exposure” adjustment in your equation does. (Although I might be missing something here).
Do you feel that a simple power function is sufficient for surround compensation? I spent a while digging around in papers from the 1970s trying to find the actual math for the Bartleson-Brenneman equations, which you mentioned in one of your talks for Filmlight… But I was never able to implement it fully to compare with the (seemingly) more common power function.
Stupid question number 3:
When you boost the shadow toe flare/glare compensation, it lowers the asymptote of the curve by the same amount. Is this by design, or is there a normalization factor to counter this toe adjustment missing?
Finally, a few naive observations:
It is super interesting from a simplicity standpoint to not have to wrap the a sigmoid in a log domain transform and then jump through a bunch of hoops to go back and forth between linear and log domains.
It is really helpful (at least for me) to see what a proper parameterized formula-based implementation might look like. I’ve been shooting in the dark a bit with my experiments, and this is useful to shape my thinking (in addition to being just plain useful).
normally you want to establish a common metric in both input and output domains, the normalised white helps with this.
If you would choose luminance as the output domain you could define 1.0 as 100 nits so 10.0 would be 1000 nits etc…
How you translate then the scene-referred image into that specified output domain is again another topic.
But the normalised white is kind of the anchor point of this consideration.
Q2)
Works great and it is super simple.
Q3)
I did not bother putting t into the calculation of m because it is a tiny nudge in white really - so it is not visible, but of course, you could say m=\frac{n}{n_{r}}+t . This would correct for t in peak white roll-off. In practice, you choose n a bit brighter than the actual display peak so that you run into the peak with a finite scene-referred value.
In HDR, normalized white usually means reference white so around 107 nits in original Dolby PQ documents or 203 nits in updated ITU BT. 2408-3 (must read) which tries to match PQ levels with HLG levels for broadcast. Protip: when blending SDR display referred logos and menus over tonemapped HDR, you want to scale the max white of your original SDR content to a bit brighter (between 1.25x and 1.5x) than the HDR reference white you’re using since you want your logos and menus to visually pop.
Peak luminance in nits is an absolutely crucial parameter to have given the state of HDR PC monitors (shots fired at DisplayHDR 400 monitors and those who buy them). When switching to HDR mode, we use this to calibrate the tonemap curve to the user monitor. As for lower nits sim on a higher nits monitor, it is just a matter of adjusting the calibration parameter when using a configurable tonescale curve. Of course, it’s also possible to clip the display referred output if the goal is to preview what a cheap monitor with a clipping internal display mapper would do with the output from an uncalibrated tone curve.
That’s because middle gray in SSTS is calculated to land at 4.8 nits before exposure offset. The exposure offset is calculated based on the parameter which allows to set where middle gray lands. All of the ACES reference HDR curves have it set to land at 15 nits so the differences you’re seeing here are related to the interpolation between the SDR curve and the RRT curve.
That is what scRGB does except that it defines 1.0 as 80 nits and 12.0 as 1000 nits. The problem is that it takes the narrow view that SDR reference white is the correct one to have. The whole debate between 107 nits reference white PQ and 203 nits reference white PQ is a cautionary tale. BT. 2408 adds a further twist and says that 203 nits is only correct when the peak luminance of the mastering display is 1000 nits. For higher or lower peak luminance, reference white should be adapted accordingly.
I guess you miss understood,
The reference white is just a concept to align various DRT from one family. It just defines the output scale. It does not define how and where you map scene-referred data to, this is defined by the DRT itself.
And I agree, the debate about mapping grey or diffuse white is somewhat misleading…
Well, my answer stems from the fact that our current SSTS outputs values in cd/m^2 and I find that very useful so my preference go to keeping it that way. Alright, when using it for SDR, the output has to be remapped to relative 0…1 and any kind of units work since the remapping formula removes the unit (which means they could even be meatballs ).
well you need to rescale for any inverse EOTF ]. PQ for example defines 1.0 at 100000 nits. If you want linear light display values directly in cd/m2 you put reference white to 1.0.
So your preference is one particular setting in the more general framework I have suggested.
It is even more useful if you start with cinema viewing condition where you actually want to map what was previously on 100 nits onto 48 nits or vice versa, but without changing the shoulder.



















 and outputs display-referred linear whatever
and outputs display-referred linear whatever 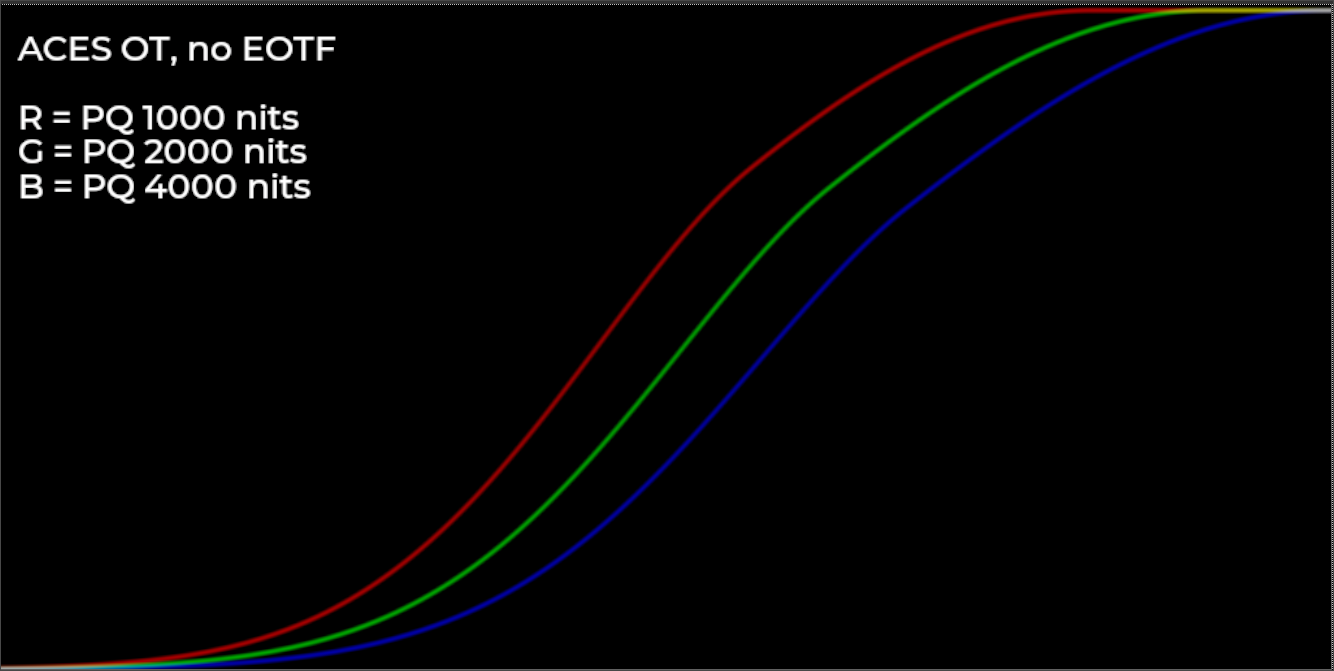
 ).
).