Hello,
I’m a compositor using mainly Nuke in ACEScg and I wonder why a log working space like ACEScc(t) is used most often in the grading tools?
Isn’t it “better” to use the gain in linear to adjust exposure by instance?
Davinci Resolve does not even have ACEScg as working space, so, what is the reason?
The maths of traditional grading operators was designed to operate on perceptually uniform image data, limited to the 0-1 range (and maybe a littler bit outside that at either end) such as log or “video” encodings. Scene-linear image data is not perceptually uniform, and can have values way outside the 0-1 range. Traditional grading operators working on this kind of image data may not respond in an intuitive and easy to control way.
Simple gain is an exception to this, and plenty of people transform to linear and back in order to apply linear gain for exposure adjustments. I have actually written a DCTL for Resolve which incorporates the transform to linear and back, and adjusts exposure with linear gain, although the user control is logarithmic and marked in stops.
Maybe this is because I’m used to work in linear with Nuke but using color corrections in ACEScc feels a bit confusing. Two examples:
trying to match and adjust white balance (which is nothing more than a gain) seems to give better results in a linear working colorspace.
using the lift tool in ACEScc(t) does not look lifted. I understand that particularly the lift is made for a range between 0-1 because the pivot is at 1, but in ACEScct, this tools does not look to lift the black. It looks a bit more like a slight variation of the gamma/power.
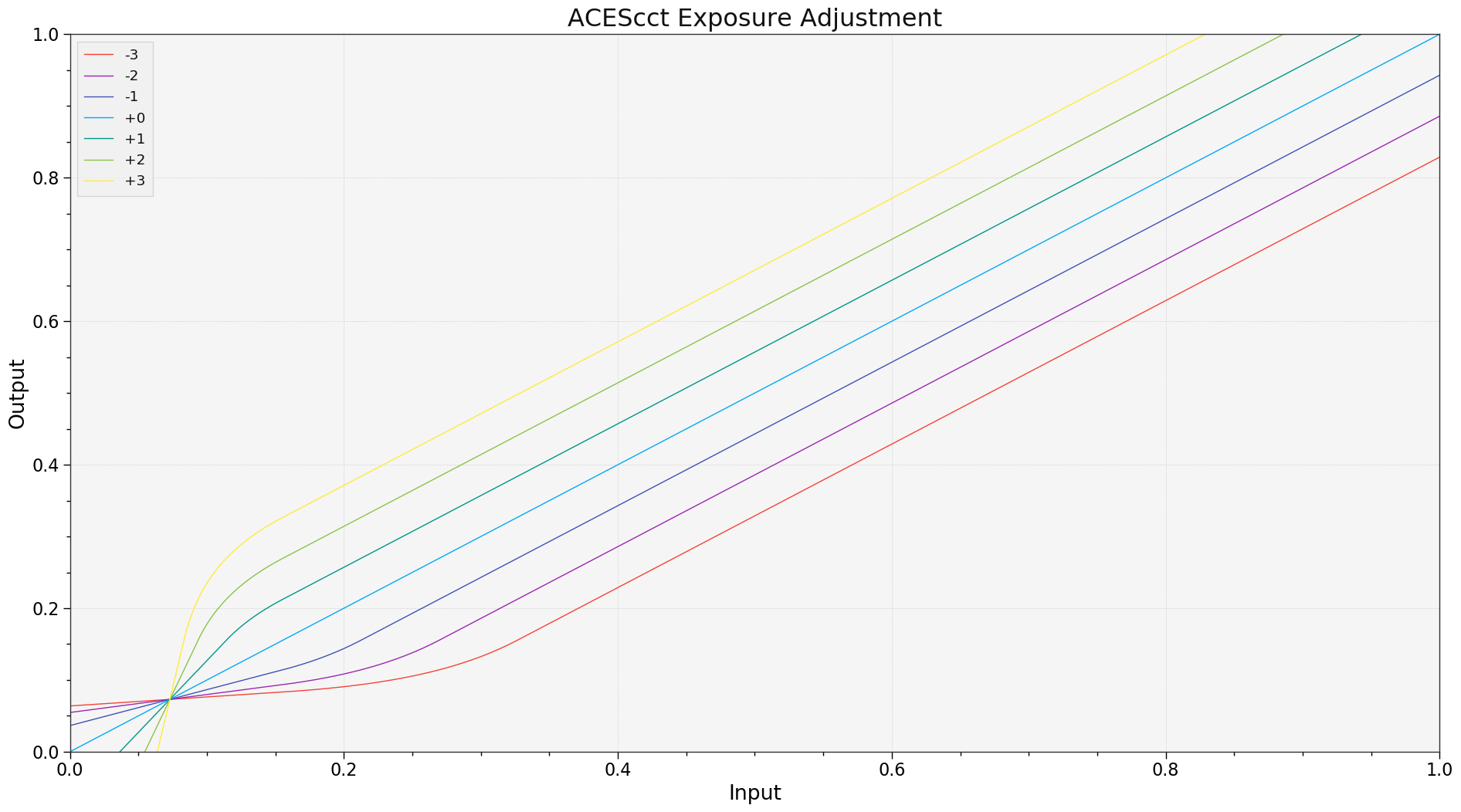
The offset is a pure addition on all the values. Gain is a multiplication which is equivalent to 2**stops I think. I’m not sure that using offset to adjust exposure is the way to go because it will change your blackpoint.
EDIT: I compare and indeed you’re right: gain in linear is offset in ACEScc!
For values >0 it is. ACEScc does not code negative values because it is a pure log coding, with no “toe”.
With ACEScct (or any camera log coding) offset is equivalent to linear gain in the logarithmic part, but is noticeably different where the offset moves values into or out of the linear portion of the curve.
Here is a plot of the curve adjustment needed to match exposure changes in ACEScct. As can be seen, it is a simple offset in the upper part, but very different at the bottom:
The ideal space for an operation depends on what you want to simulate.
If you are after modelling physical phenomena, then some sort of scene linear is probably the right domain. If you want to model perceptual phenomena, then typically a perceptual space (like a quasi-log or opponent space) is the right thing.
Some example:
If you want to do white balance/exposure, multiplication in the linear domain is the right thing to do.
If you are after simulating an optical blur also linear light is the right space.
If you want to sharpen an image, then log is the right domain because there is no physical process of sharpening a scene. (Sharpening is probably happening in our neural pathway)
It becomes tricky if you do things that incorporate several things at the same time. Scaling, for example, has both a physical component (anti-aliasing) and a perceptual component (sharpening). So there is not really a right or wrong way. Most of the time, you scale in quasi-log because the disadvantages of the sharpening components produce artefacts in linear (overshoots).
Modern colour correcter tend to develop into the direction that each operator is operating in the space appropriate for its design goals.
For the argument of addition in ACEScc vs multiplication in linear:
The result might be identical for the operation of a white balance or exposure change. But you should not forget that ACEScc will put the image into a state which overemphasises the energy in the shadows. Subsequent operations like saturation changes or scaling might not work correctly in ACEScc with lots of “dark energy” :-).
So ideally you do white balance in linear and then convert to a quasi log representation for things like sharpening or scaling.
I think generally ACEScc is quite difficult to use because it is not a physical nor a perceptual space.
Then legacy tools have lots of “assumptions” build into them.
FilmGrade (Offset/Contrast) assumes that the image is encoded in a cineon like quasi-log space. This is for what this particular tool was developed for.
Same is true for legacy keyers and other tools. The same way most of the compositing tools were designed with the assumption that the image data is presented in linear light.
It really does highlight the base need to understand where and why you’re performing the specific colour processing that your are. There is too much mis-information driven by antiquated pipelines and photochemical film based advice, than warrants.
Thank you for speaking frankly in that there are real trade-offs between a physical-based phenomenon and a perceptually based phenomenon…
These are the details that regularly get swept under the rug and provide a true disservice to all that don’t even understand the basics. It all falls back to conventional-ism…
Hello,
I have been reading this post quite a few times and I find it very interesting… Someone has recently told me :
Theory offers guidelines, Experiment offers decisions.
And I find it particularly true when it comes to colour management… So we have been doing some grading tests with ACEScct VS ACEScg. And I was pretty surprised by the results.
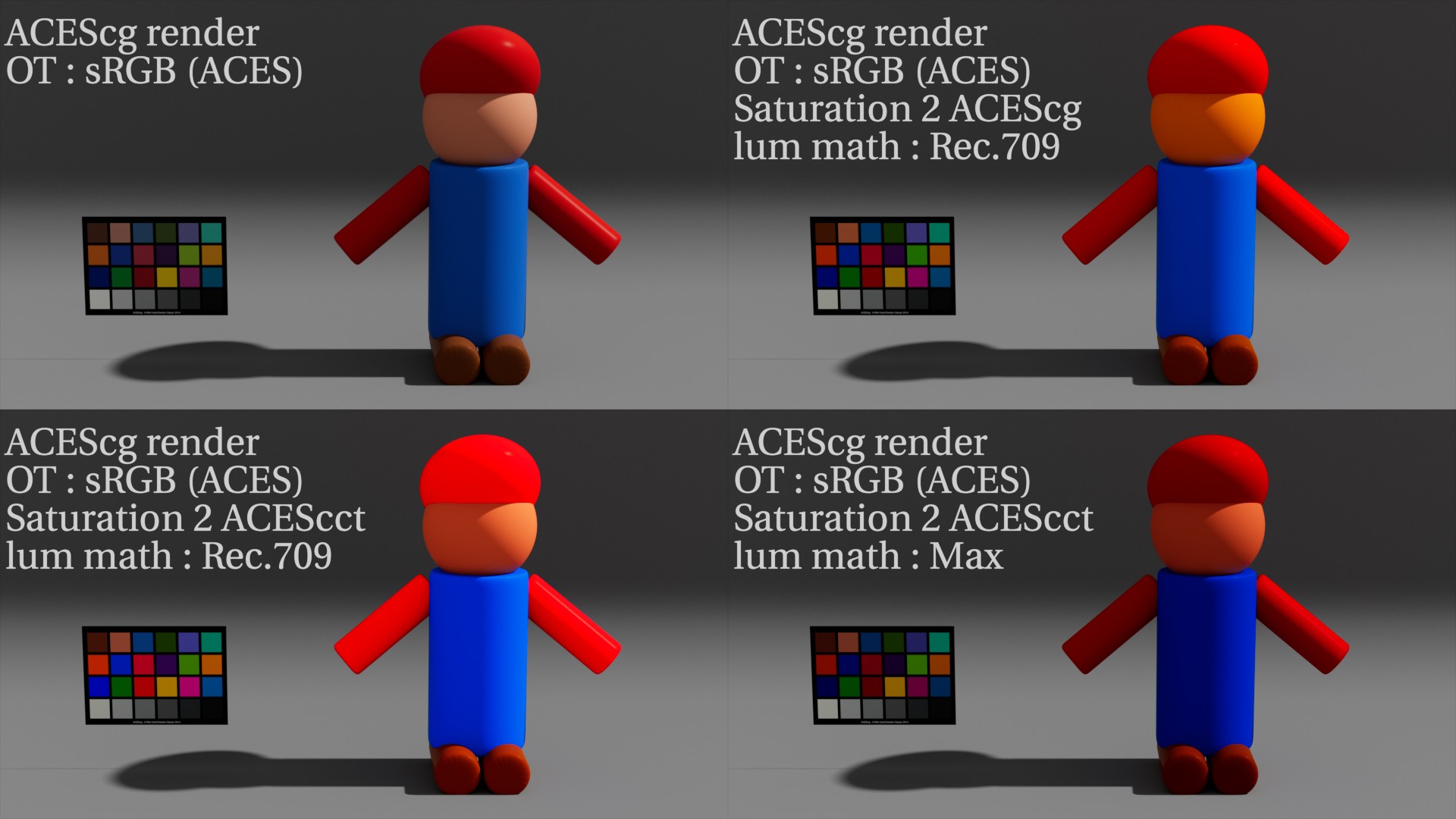
Here are 4 renders:
Top Left is an ACEScg render, displayed in sRGB (ACES).
Top right is an ACEScg render, with a saturation at 2 (lum. math : Rec.709), displayed in sRGB (ACES).
Bottom left is an ACEScg render, with a saturation at 2 (lum. math : Rec.709) on ACEScct, displayed in sRGB (ACES).
Bottom right is an ACEScg render, with a saturation at 2 (lum. math : Max) on ACEScct, displayed in sRGB (ACES).
When we saturate on ACEScg, I agree colours are not very nice, like the skin tone here gets really yellow. But luminance is preserved. When we saturate on ACEScct, colours are more pleasant (at least to me) but the red tones get over exposed really quickly. Which can be an issue when your main character has a really red shirt. I was interested by the lum. math Max as well but it makes the image overall darker. Really not ideal.
It’s not really surprising that using different maths to calculate luminance will give a different result when inspecting the luminance, is it? And equally I would expect using the same maths in a different working space to give different results for many (but not all) operations.
What surprises me is that I have never read anything on the reds behaving weirdly with a log format. I have also tested with a s-log curve and I got the same behavior. I have also tested with lum. math ACEScg and it slightly improves the red behavior, but not much.
For the record, we found the lum. math ACEScg on Natron website and funny story, it seems that MaterialX/OSL also uses ACEScg as lum. math. Contrary to Resolve or the CDLTransform that uses Rec.709 luminance weightings for saturation.
I would love to hear your take on that @daniele What does BaseLight do for instance ? And finally a stupid question : should I look somewhere for lum. math ACEScct ? If there is such a thing…
Now you hit a fragile point here. Saturation, or do you mean Chroma? (Just kidding).
For many image processing problems, we can decide what we take as the reference for our implementation.
For “Exposure” we can, for example, pick the radiometric domain and do stuff in linear light.
For sharpening we can decide, do we want to compensate sharpness loss in optics for example (thanks @Troy_James_Sobotka for pointing that out)) - then we pick linear light (errata for my post above). Or do we go for neuronal sharpness which comes from later inhibition for instance, then a “perceptual domain” would be probably the right starting point (as mentioned above).
Now the thing with saturation is, that it is hard to make a physical scene more saturated (or desaturated). How would you do this? How can you make a real red hat and a blue t-shirt more spectral selective at the same time - together with green grass? You could wet the surface a bit to make it scatter less, but there are limits, and then the t-shirt is wet. You could add particles in the air, but then you also change flare and contrast a lot. There is no simple way. You need to buy a new red hat and a new blue t-shirt which is more spectrally selective.
So what can we do?
You could throw in some energy preserving models:
I talk just about this from ~7.00 min - 30.00 min
You could try to go into a colour appearance space and take sensory adaptation and scaling of the cardinal directions as your starting point. (Good luck with scene-referred data)
musing about this from 15.00 min onwards (sorry for the voice, had an exceptionally bad hangover that morning).
You could look into modelling saturation in spectral-domain. Spoiler: produces unexpected results.
My point is:
there is no “correct” way of adding (or removing) saturation. This is the reason why we have at least 5 different ways to modify saturation in Baselight (currently working on an additional three
I also think that distance functions in both linear and log encoded RGB are not the right thing for this task. But it is something we test against when we evaluate Display Rendering Transforms.
When we use a denoiser (OIDN), for CGI. Is it better use it in liniar and before color grading isn’t?
But denoise is not a physical phenomena, is it? Would that a exception to the rule or I’m missing something? (Provably is the last option, Could you help me to clarify that?)
Noise is a physical phenomena
So the “amount” of noise in relation to the image “exposure” is quite predictable.
Denoiser are complex algorithm and I would reach out to the denoise vendor to find out what assumptions about the colour space are build into the denoiser.
Clearly a denoiser shall be applied in the purest scene referred state without creative colour grading. But an exposure adjustment might be useful to place the image in the intended area.
By the looks of it OIDN uses ML techniques. With ML algorithm in general the image state and colour space of the training data needs to be similar to the image state and colour space of the images you want to apply the algorithm on.
OIDN is trained on scene-referred imagery, it can denoise LDR and HDR images whilst also using Albedo or Normal AOVs to improve the denoising process. This should probably be the very first step before doing anything else on the images in Comp.