On Sonys website it says that X-OCN uses 16bit scene-linear encoding.
My first assumption was that it would be half-float. But they also say “2^16 gradations” which would mean 16bit int.
as far as I understand storing scene-linear data in an integer format is highley inneficiant. as the values double with every stop of exposure increase.
I doubt deriving scene-reffered values from sensor pre-debayering is possible(but maybe it is? , as without knowing the filter used infront of the cmos it shouldnt be possible to derive scene-reffered data due to the non-linearity of spectral respone.
Not even considering non-linearity of the sensor , even if modern cmos apparently are pretty close to linear. but i guess it could maybe be done in processing
But even then the first thing still applies, I cant name one scene-linear integer format and no application that processes those.
Most camera RAW formats are linear and integer (usually 16-bits) because that’s what hardware does. You’re right that the code values double for every stop so usually you’ll see that the majority of the values in the camera RAW file are pretty small assuming normally exposed scene. Most camera RAW formats position the code values to leave room for 2-4 stops of extra room above a scene 100% white reflector before the values clip. The usable range on the bottom end is usually dictated by the SNR of the camera system. So long story short, is that there’s plenty of digital cameras that use integer to store scene-linear images. DNG, NEF, CR2, ARI, R3D are all linear integer encodings.
On the topic of scene-referred … scene-referred doesn’t mean directly encoded scene colorimetry. It simply means that it’s data for which there’s a way to estimate it’s relationship to the original scene. So, yes you can estimate the original scene’s exposure values and colorimetry from camera data. Estimating from camera RGB values to scene colorimetry is usually done with a 3x3 matrix (though this is only an estimation as its usually a non-linear relationship) so generally camera RGB is considered scene referred.
Thank you really appreaciate the answere but now I am confused I thought that CR2 e.t.c are not scene-reffered but “device reffered” if its just a matter of scaling the curve back up by multiplying it to get 0.18 to be mid gray , we should be able to derive scene-linear light values, no? If thats the case then how would that work in practice? I have not gotten any of those raw formats to debayer into anything scene-reffered, I have went down that rabbit hole here: Help me understand Photography Raw
Practically all the different raw converters seem to not give me scene-reffered
values back.
But maybe you can explain more and I got something backwards here.
A lot of end-user focused Digital Still Camera RAW converters don’t make it obvious, or maybe even possible, to get linear estimations of scene colorimetry out because that’s not useful to their primary audience. What are you trying to do?
Right now its more about learning more and trying to undestand the underlying science behind it.
If I go back to my “understanding photography RAW” that all came down to not beign able to get anything matching the scene-linear data from a alexa from those cameras , practically all tools like rawtoaces e.t.c just gave me linear values that seemed to be normalized or “compressed” , and as @Troy_James_Sobotka said,
The device transfer function a vendor chooses is there for good reason; it’s a valuable compression function. The time of linear raw encodings is likely soon to be relegated to the discard bin of history for this very reason; they are horrifically inefficient, but because digital sensors are so f#%king horrible, we haven’t quite noticed.
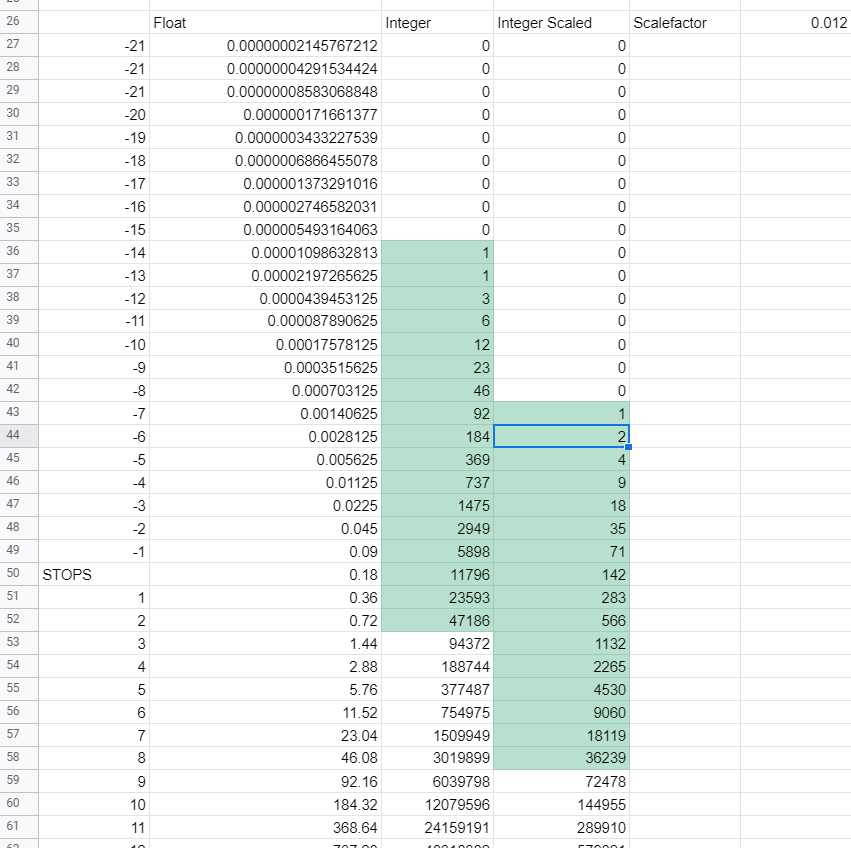
I mean I guess its possible to store like 17 stops of scene-linear in a integer format but why would you do that, seems way more efficient to just fit the sensor data into 0-1 and deal with the “desqueezing” later in processing. Made a little visualisation to show how linear scaling effects the code values , aka moving middle grey around. which gives me -8 and +8 stops around middle grey, which I guess would be ok-ish
But if you look at the value distribution it seems pretty nonensensical to allocate bits like that half of all the avaiable bits are just “wasted” between stop +7 and + 8 , while float seems way more suited for this kind of stuff as its precision is going down the higher the values go. Not even just from a sensor technology standpoint, which might or might not be Scene reffered , storing data like this doesnt seem efficient, but maybe they have found a smart way of compressing this stuff I just dont know how and why they would claim its “better than 12bit” if their direct competitor is storing data as 12bit log (Arriraw) , and I never saw arri reffering to their 16bit linear sensor data as scene-linear , just linear .
Could very well be that there are 2 different meanings to “scene-linear” though, maybe what I am looking for is " radiometrically linear " ?
We can’t quite get to radiometrically linear with respect to a tristimulus system, given they inevitably end up photometric. But with that said, that’s my preferred term, and it is synonymous with “scene” linear to the best of my understanding.
I have found folks to get confused over “scene” given that some colour operation can remain more or less radiometrically-like linear, but depart from notions of “scene”.
Yes. And don’t look at those first few stops, as they too will horrify you.
An additional point is that while some (particularly still focussed) raw formats may store the linear integer data “as is”, this is not always the case. DNG includes an optional linearisation LUT, allowing non-linear data to be stored and subsequently re-linearised. ARRIRAW is uncompressed, but still uses a 12-bit logarithmic encoding of the data internally to reduce the data rate and make more efficient use of the bits. X-OCN and R3D are “black boxes” which take in linear integer data and can return the same. Their internal workings are not published, but they are both compressed, so one thing we can be sure they are not doing is storing that linear data “as is”.
Thank you all so much I love just grinding this stuff and understanding more!
So basically we cant say sony is using the term “16bit scene-linear” in a wrong way, but its also not very exact to what it actually is and their claims “its so much better than 12bit” is sort of just marketing with no sustance behind it.
I sent a email to sony Pro support asking for clarification as well but I am not getting any answer without providing a venice serial number I would honestly assume they use some kind of log or float internally for storing and its just “transparent” 16bit scene linear data after processing which as its a blackbox doesnt matter to the end user. just like how prores444 can be used for RGB sources but its still YUV internally…
and I learned that there are a lot of definitions out there to whats scene-linear
I have no knowledge of what Sony are doing or not doing with the 16-bit linear data in X-OCN. All I know is that they are compressing it, and they don’t claim that compression is mathematically lossless.
Yep - The sensor does the dual analog readout, combines it and maps it to 16-bit linear, transforms to 12-bit log, and stores it as such in the raw format they use.
 I would honestly assume they use some kind of log or float internally for storing and its just “transparent” 16bit scene linear data after processing which as its a blackbox doesnt matter to the end user. just like how prores444 can be used for RGB sources but its still YUV internally…
I would honestly assume they use some kind of log or float internally for storing and its just “transparent” 16bit scene linear data after processing which as its a blackbox doesnt matter to the end user. just like how prores444 can be used for RGB sources but its still YUV internally…