Thought I’d post this here since the other thread is knee deep in a Lovecraftian orgy of number fornication, with the hope of Yog-Sothoth being summoned.
There seems to be an assumption that “the colour” is in the pictorial depiction. I’d suggest this is not the case, and broadly patterns after a Grossbergian idea around “response normalization”1.
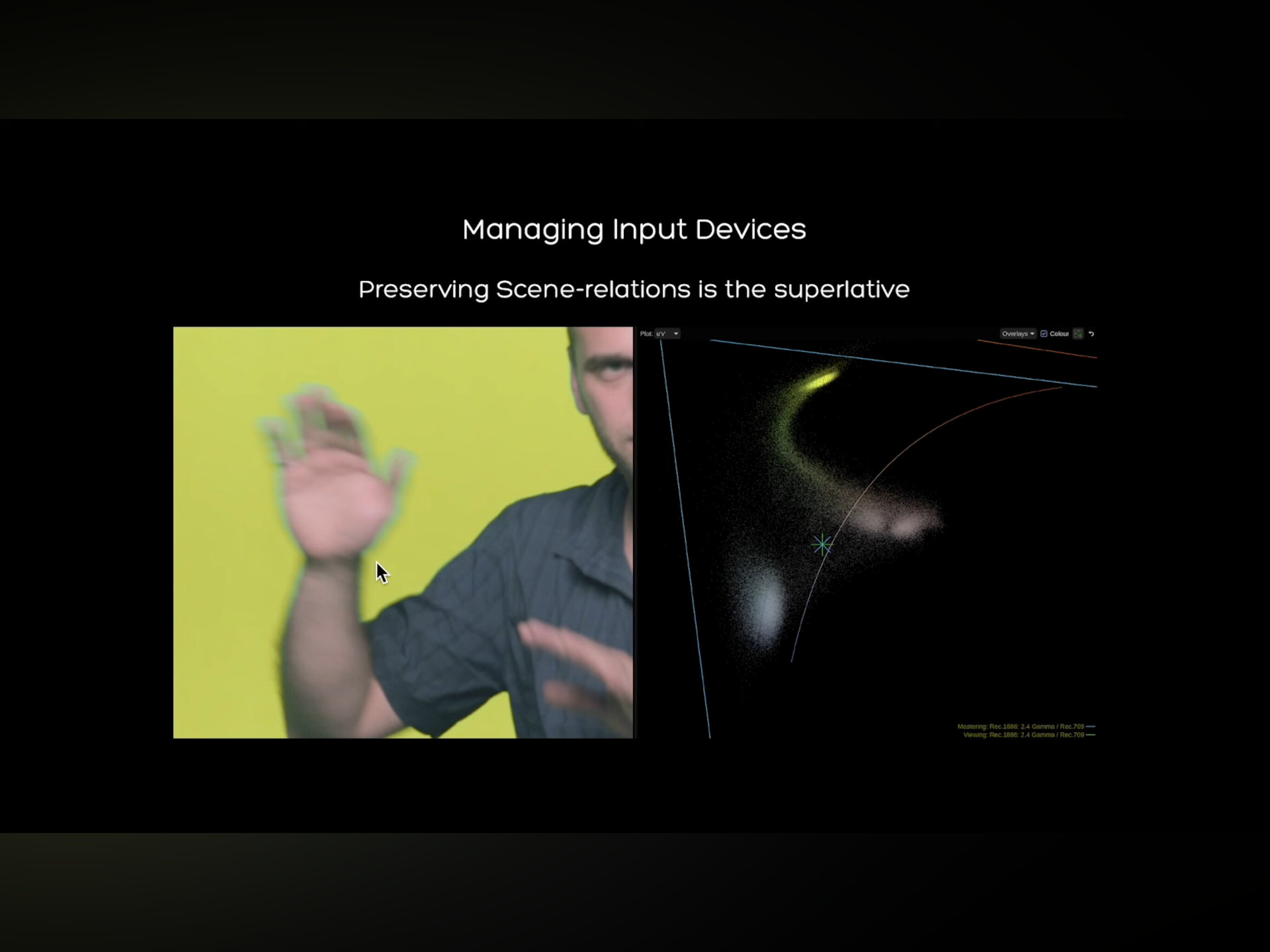
When we look at a pictorial depiction of “motion blur” I would suggest that we are fissioning the forms / entities into a decomposition based on probabilities of something “over” some other “form”. Daniele’s videos show some of this rather nicely, although @TooDee has been trying to draw attention to this for a long time, and sadly no one has been paying attention.
Here are the two demonstrations selects that I pulled from the video. Pay attention to the “hand” depiction, which can be challenging with the depiction of a “rugged Italian German” cropped at the right of the frame:
I believe it is important to wipe away all of our nonsense about “scene” and “display” for a moment and realize that what we are parsing are the pictorial fields presented to us right now.
We can clearly see that in one case the pictorial form leads to “hand of rugged Italian German on ground of ‘green’” and in the other “hand of rugged Italian German with a tremendous looking grape-like forehead on a ‘ground’ of ‘yellowish’, and a ‘ring’ around the ‘hand’.”
But these ideas are a tad deceptive, and I would suggest that we are engaging in the aforementioned response normalization by way of the neurophysiological signal energies.
First up… Let’s see if the “colour” we think we are seeing is present within the stimuli:
I’ll go out on a limb and suggest that most would agree that the cognized computed colour that we think is “around” the “hand” is an unsatisfactory match to any singular stimuli sample. Feel free to reject this idea, and find a better sample.
So this leads to the question, if the colour we are cognitively computing by way of the fissioning mechanism / normalization, is not present in the stimuli, what specific facet of the gradient is leaning our probability computation to read the stimuli as “other”, and a “ring” around the hand?
The answer thankfully must be present in the stimuli presented in the pictorial depiction, without falling into Giorgianni-Kodak’s bunko rabbit hole of “scene” and “display”. We could say that there’s a rather tenuous link between the gradients present in the quantal catches, as Daniele has showcased, but in the end, what we are presented with in the pictorial depiction is all the evidence we likely need to diagnose the crime scene. And we know that a physicalist energy cannot account for this phenomena, as the computation is meatware based, from the neurophysiological signals. Somehow we are fissioning out the “cyan green” “ring” around the “hand” from the “yellow slime” “ground”, and the “pale pink-yellow” depiction of “hand”.
I’ve been sort of fascinated by this local response normalization by tracking how chemical film introduces the offset dimension2, where electrical sensors do not. Might be interesting to some folks. The picture a film scan from Pixel Fed’s Bogat23k:
The key point is that our computation of the “blueness” of the door is plausibly an unsatisfactory “match” to any given sample of stimuli. Somewhere in this cognitive fission mechanism we should be able to spot a pattern of local differential gradients.
If we loop back to the Daniele “hand” depiction, we can get a sense that at a given spatial viewing frustum3 the depiction of the “hand” is cutting across “three” differential gradient boundary “slope zeros”, and our meatware computation might be triggering on these as high probabilities of “boundary” as opposed to “same”.
—
1 This has a massive amount of research papers, but this one is useful for a broad summary of the idea of normalization around pools / fields of neurons. Carandini, Matteo, and David J. Heeger. “Normalization as a Canonical Neural Computation.” Nature Reviews Neuroscience 13, no. 1 (January 2012): 51–62. Normalization as a canonical neural computation | Nature Reviews Neuroscience.
2 I strongly believe that the totality of the cognitive fission response normalization can be mapped along gain to offset dimensions, and that the crucial difference between chemical creative film and crappy electronic sensor data rests in this dimensional projection. One integrates the offset, one can only integrate the gain, and leaves the formulation of the offset dimension to the pictorial formation algorithms. Which leads us to the Lovecraftian Orgies of Yog-Sothoth.
3 I would suggest that viewing frustum dimension must be crucially important here for we can “zoom out” to a point where we would suggest a low probability of “boundary”, and likewise “zoom in”. That is, the physical energy that lands on our log-polar density of cells is likely influencing the differential gradients of the On-Off / Off-On cells. Viewing frustum matters of course, for anyone who has sat in front of a 40 meter screen and experienced iPhone level camera shake probably would attest.