Of course there is not. The elasticity of our visual cognition is perhaps deluding us? The reasons this is fundamentally impossible is because our visual cognition is a fields-first cognition loop. There are countless examples of the influence of fields, including quite a number of models that provide such a transducer stage, post fields analysis. Citations as per some of the names already offered, and others if anyone sees any use.
If one truly believes that a field-agnostic metric is of any service, one merely needs to look at examples as to how the spatiotemporal articulation is a primary stage in our visual cognition, cascading upwards and receiving feedback downwards in the reification of meaning process. I have found no better demonstration than those of Adelson’s Snakes.



Given we know from these demonstrations that the spatiotemporal articulation fields are incredibly low in the order stack, we can also hypothesize that the fields and visual cognition will shift with a shift in spatiotemporal dimensions.

Some conclusions one might draw from these demonstrations:
- Visual cognition, such as the reification of lightness, clearly has a primary driver of field relationship in the reification process, as well as a bit of research suggesting that instability based on cognition is also present.
- The idea of the transducer as well as amplification becomes apparent in the field relationships. Has implications for HDR, for example. IE: The R=G=B peak output of the last diamond set is often cognized as exceeding the tristimulus magnitude of the display in terms of lightness reification.
The last question is in relation to the following demonstration, posted by @priikone, which I believe is the ARRI Reveal system:

We should be able to predict that at a given quantisation level of the signal that we can induce the cognition of “edge” or “other”. The picture in this case, expressed in some unit of colourimetric-adjacent magnitudes, relative to the observer. Indeed it seems feasible that at some scales, the signal is discretized, and an aliasing may be more or less cognized:

Indeed we see a repeating patterned relationship with the classic Cornsweet, Craik, and O’Brien demonstration.
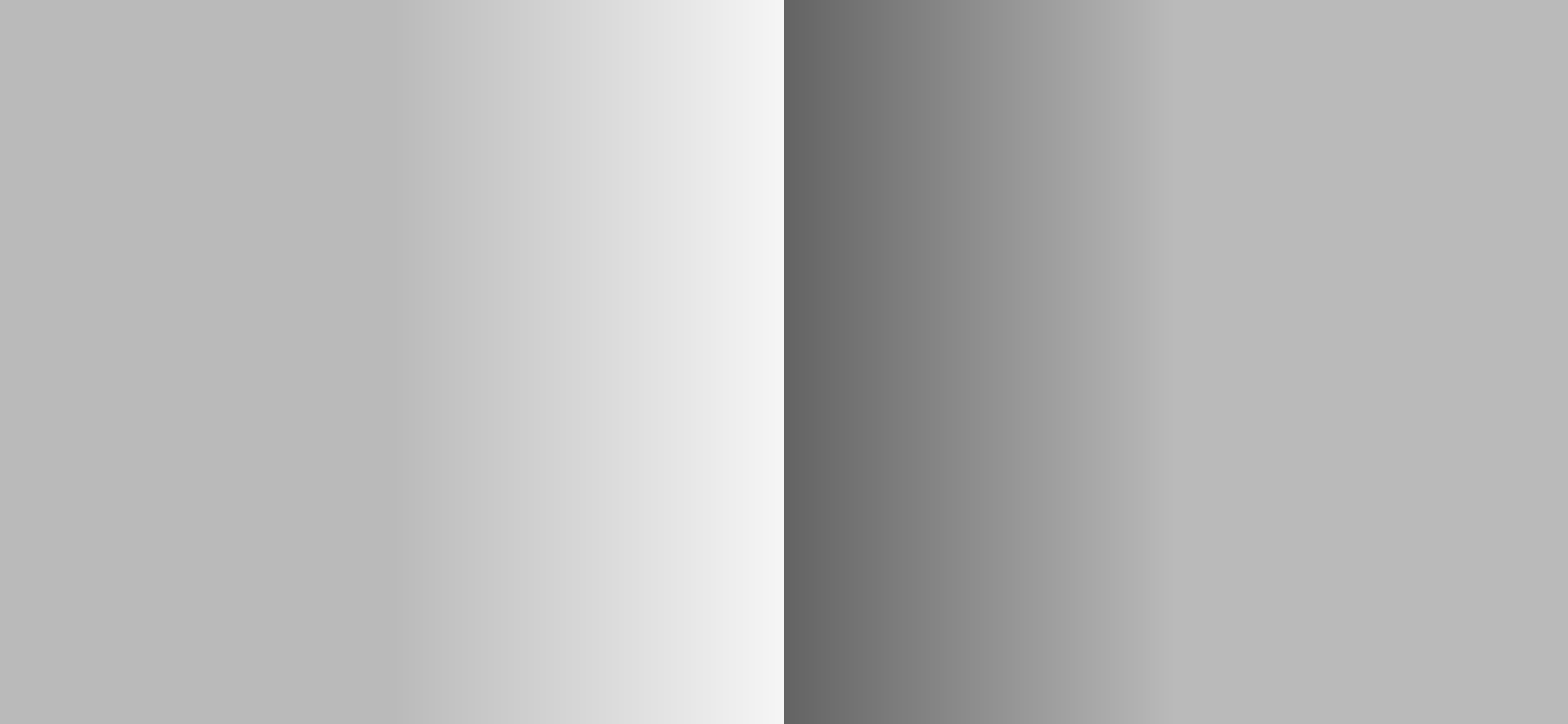
Observers of the picture may cognize:
- A “left looks lighter than right” reification.
- A “dip” immediately adjacent to the ramps, aka “Mach” band.
If we attempt to provide a metric to this, we might harness luminance metrics. While it can be stated that the transduction / amplification mechanism makes no singular luminous efficacy unit function feasible, for a high level analysis, it seems at least applicable.
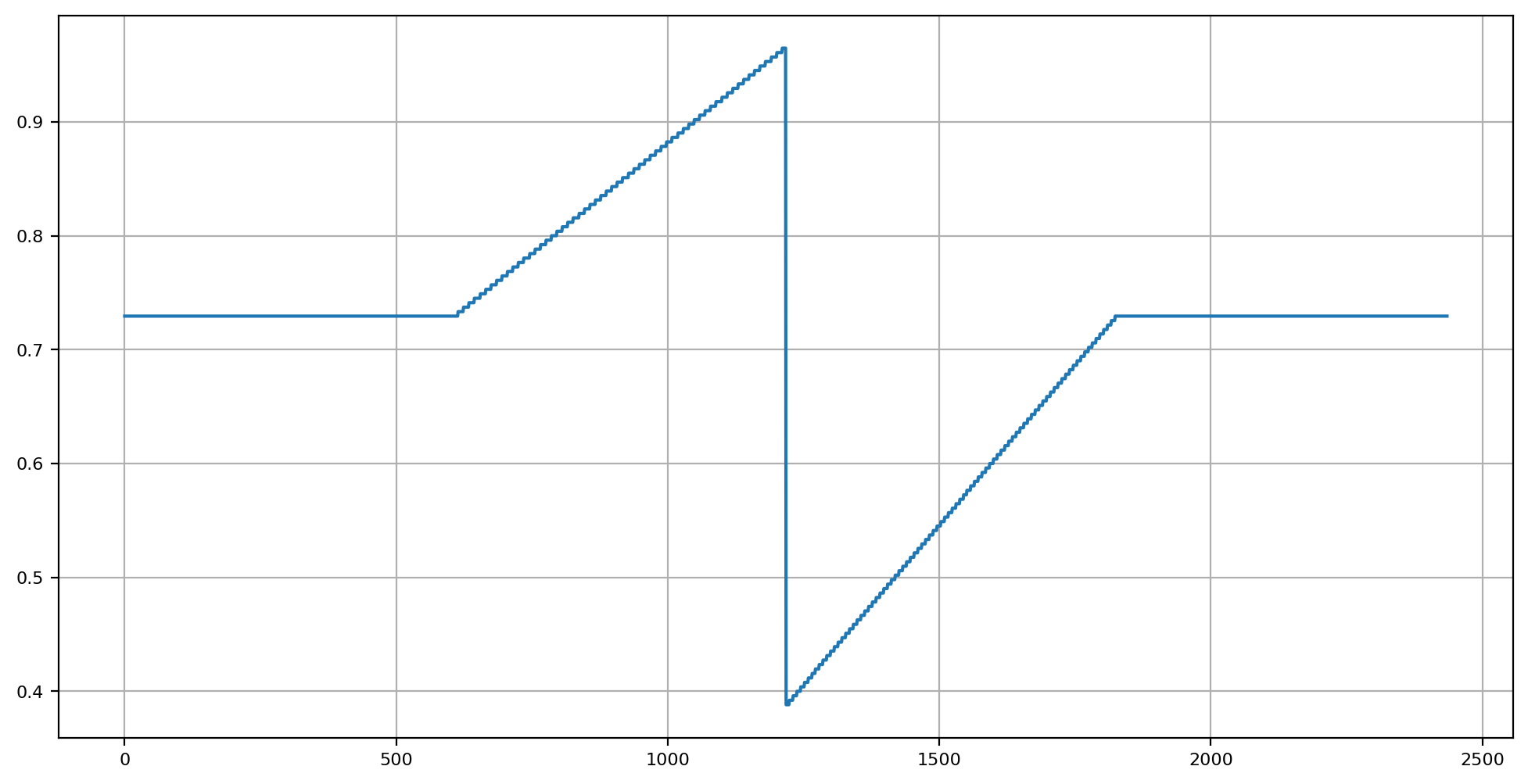
At specific octaves, we are able to at least get a semblance of visual cognition reification probability at the “full screen” dimension. For example, at low and middling high frequencies, and assuming a simplistic calibration to something like a 12” diagonal at 18-24” viewing:
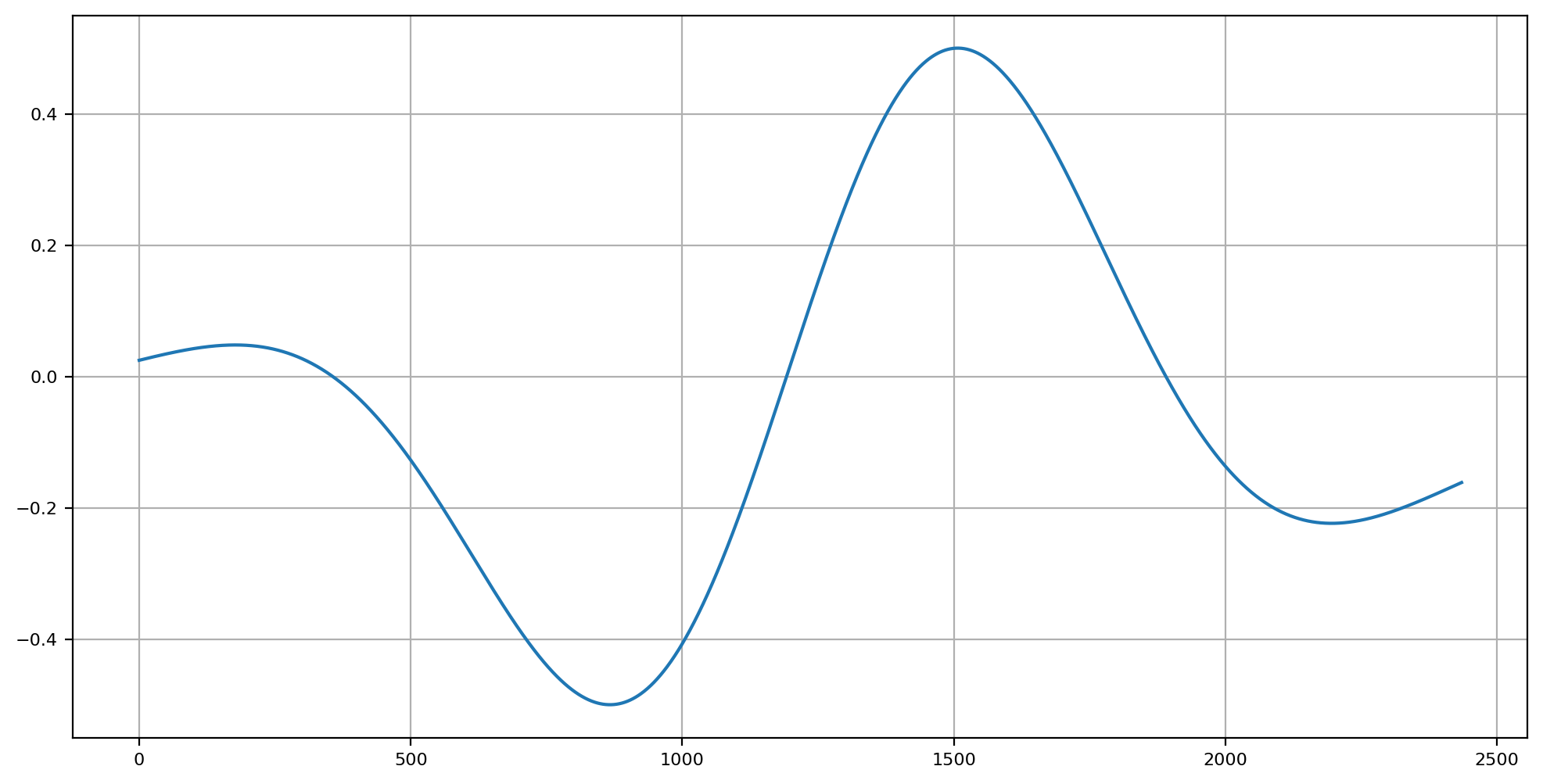
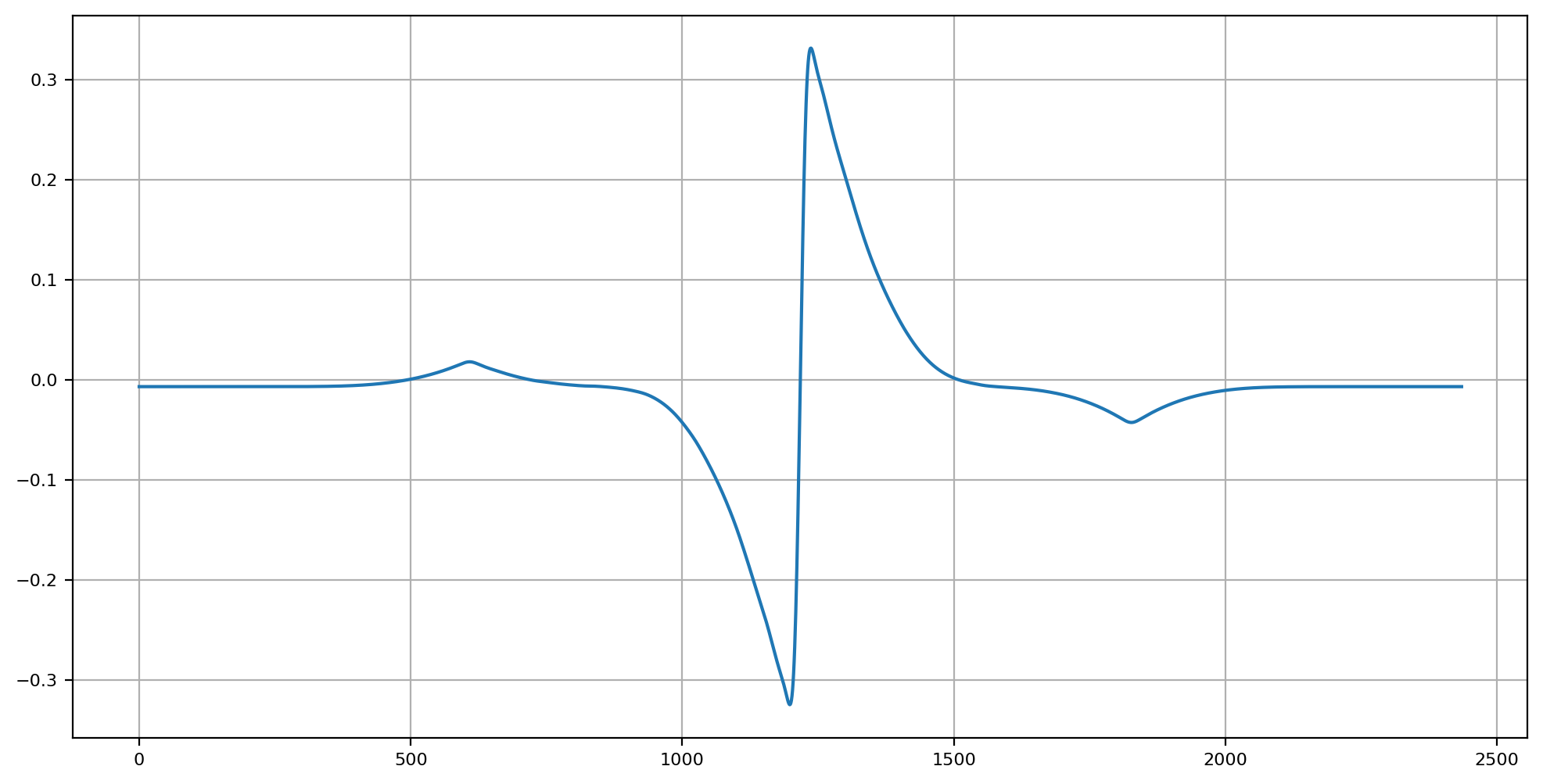
We can at least see some degree of hope of a practical utility to help guide our analysis of the signal that may aid in locating regions that cognitive scission / segmentation has a higher probability of occurring.
For the inquisitive, visual fields play a tremendous role in the reification of colour in our cognition, which the aforementioned fields-first frequency analysis can provide some insight and predictive capability. There is likely a direct line to this and some of the incredible complexity in the formed picture from Red XMas, for example. Discs in the following are equal tristimulus magnitudes, and follow the patterns outlined above in the transduction / amplification concept.


Broad conclusions:
- Fields first thinking should be at the forefront of analysis.
- A general consistency of the viewing field in terms of spatiotemporal dimensions is likely mandatory for evaluating “smoothness” of fields.
This is not what I think. I am a dilettante idiot buffoon that reads vastly wiser and experienced minds. I don’t have an original thought in my body.
It strikes me that the claims of such systems are bogus. That’s just my pure hack opinion. Folks are free to evaluate the evidence and believe what they want.
Not a single tristimulus triplet in terms of colourimetry as it exists in the open domain data buffer is ever presented in the form of a spatiotemporal articulation. Not a single one. If we were to apply some colourimetric measurement between the thing we are looking at (the picture / image), versus the colourimetric data in the EXRs, there are new samples formed.
The whole discussion of hue flights and the attenuation of chroma? That’s a byproduct of the crosstalk from the per channel model, not the higher level lofty idea of the model. It is an accident.
Maybe this is how you personally approach understanding. I do not. I’ve been openly saying forever that I don’t even understand what “tone” means, and I’ve tried to be diligent in exploring concepts and understanding without cleaving to the orthodoxy. So let me be clear:
I have no ### idea how visual cognition works.
I consider picture-texts a higher order of complexity above the basic ecological cognition of moving a body through space.
What I do believe, is that much of the iron fisted beliefs that orbit in some small circles do not afford any shred of veracity under scrutiny.
I have proposed what I have believed to be the best paths for a long while now; attempt to enumerate the rates of change and model them according to a specific metric that holds a connection to the ground truth in question. Try to hook the map (the metric) up to the territory (the specific thing attempted to be measured).
Curves, for example…
The basic mechanics of a curve in a per channel model is far from “simple”:
- A curve does not hold a connection to reified lightness, yet it is analysed as such. It holds a direct link to a metric of luminance in exactly one edge case of R=G=B when applied on a channel by channel basis.
- A curve adjusts purity in terms of rates of change, depending on the engineering of the three channels, in the output colourimetry.
- A curve adjusts the rates of change of the flights of axial colourimetric angle.
- A curve adjusts the intensity in a non-uniform manner, origin triplet depending.
Some questions I believe deserve due diligence:
- When considering a triplet of “high purity”, how does the transformation to result relate to the curve rate of changes of the above three metrics? “Middling purity”? “Low purity?”
- When considering the above three broad classes of “purities”, how do the above track in relation to the equal-energy case, and at what spatiotemporal frequencies?
- Are there known methods that can be used to broadly analyse, predict, and estimate where visual discontinuities exist? Could they be leveraged to make predictions in relation to the given curves at given spatiotemporal frequencies?
- In the case of negative lobed values, are there broad trends that can be used to coerce those values into the legitimate domain prior to picture formation? Are there “rules” that should be established here? Why?
Of course not.
The reason behind the link you posted is to try and get a handle on how the seeming simplicity of per-channel mechanics in forming pictures is actually incredibly complex. I have used the experiments and the basic mechanics to glean insight into the surprisingly complex interactions when projected as colourimetry, and tried to get a better understanding on how these rates of change interact with our picture cognition.
I think we all can, or should aspire, to be far better at kindling our understanding of pictures.