You may join via computer/smartphone (preferred) which will allow you to see any presentations or documents that are shared, or you can join using a telephone which will be an audio only experience.
Please note that meetings are recorded and transcribed and open to the public. By participating you are agreeing to the ACESCentral Virtual Working Group Participation Guidelines.
Audio + Video
Topic: ACES Virtual Working Group Meetings
Time: This is a recurring meeting Meet anytime
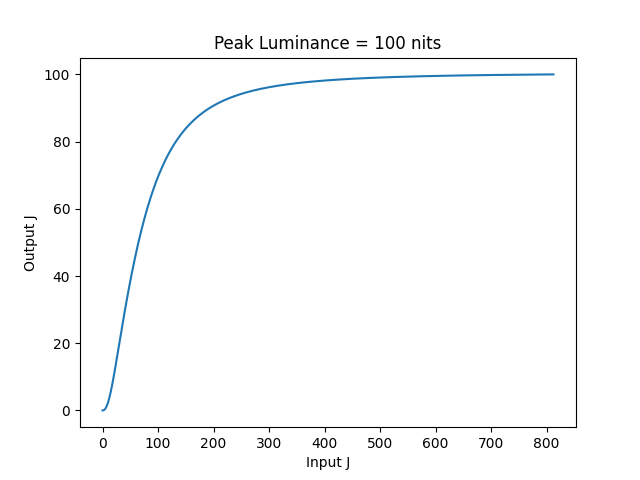
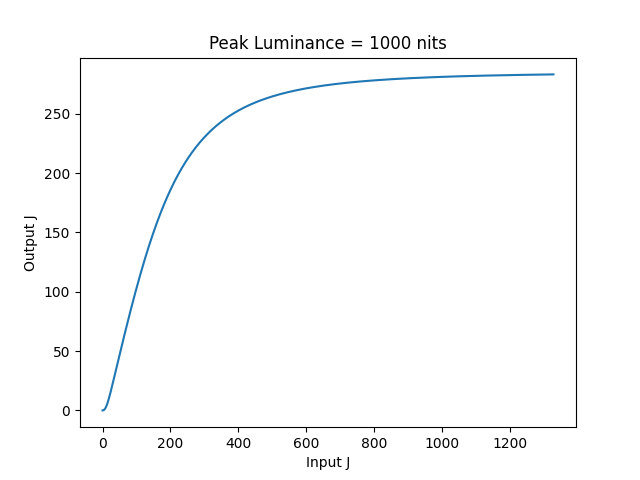
I’ve done some calculations of the domain that a 1D LUT would need to cover in order to apply the ACES 2 tone curve directly in J. In the table below, limitJmax is the output J value of the given peakLuminance, and maxJ is the input J value which will be tonemapped to limitJmax .
Since the tone curve is clamped at zero, the LUT would not need to deal with negatives. The current Output Transforms are also clamped to the peak luminance, so in theory a 1D LUT only needs to go up to maxJ. But for an OCIO built-in, a small overshoot could be helpful.
I made a couple of plots of the J to J tone curve at 100 and 1000 nits.
The tonescale currently amounts to 5 powf functions calls (plus arithmetic), I think there should be a substantial gain replacing it with a simpler 1DLUT or fitted curve. Fractional power functions have a non negligible cost from what I have seen so far (including one log + exp calls per evaluation) and this can add up quickly. In OCIO I profiled on the CPU and around 45% of the total time of the ACES2 DRT was spent on powf calls (we currently don’t have SSE acceleration or powf approximation in place). There was similar profiling done on the GPU and powf was also identified as an hot spot.
This might be somewhat OCIO specific, though the code currently follows the CTL reference quite closely, feedback from other implementers are more than welcome!
In general, I’d say any computation we can avoid or any way we can simplify the DRT would be a win.
You are putting a few things together here, let’s stay on the tone curve:
Do you have figures on how much the 5 power functions actually cost, compared to a 1D Lookup?
I highly suspect that it is not measurable on a GPU.
And replacing the tone scale with techniques which involve a lot of branching will certainly increase the computation time, or even worse make it image content dependent.
Do we really think that the bottleneck of the DRT is a conversion from and to J and two lines of straight forward math?
For context this proposed optimisation was mainly driven by CPU profiling and after testing it quickly it seems to indeed be effective (using ocioconvert, the original ACES1 Rec709 transform takes 0.5s to process a Marcie from the ACES image repository, 1.8s for ACES2 and 1.3s for ACES2 with the tonescale LUT). I’m not saying we should necessarily adopt such a change but it does indeed confirm this is a bottleneck on the CPU (unoptimised OCIO version).
I’m sure it is possible to profile on the GPU given appropriate tooling (for example NVIDIA NSight) but I unfortunately don’t have the setup for that (such profiles have been shared on the OCIO slack and showed the powf lines as hot spots, but not saying it is the current bottleneck of the whole transform here). I’m relying on OpenGL timer queries to measure the entire draw call time on the toy ociodisplay program. I’m currently running the transform 10 times in a loop within the fragment shader to get measurable results (otherwise the bottleneck is not in the shader computations). I’m also seeing speedups with this change, around 20%, but if these measurements are of any significance the GPU implementation is already quite fast (from 1.5ms to 1.15ms on a mobile GPU and 0.06ms to 0.05ms on a server GPU) and it might not make big differences in practice. Though we have had some negative feedback on the performance of OCIO 2 GPU implementation and are waiting to hear more about it.
I’m not sure I’m following you on the additional branching, this is a texture lookup.
Overall I’m not disagreeing with you I think and there might other parts of the transform, like the gamut mapping, that might make more sense to look into for GPU optimisation. Yet another part we discussed was removing the binary search in the gamut cusp tables sampling, which I also tested and seemed to yield another 20% speedup.
Thanks for clarifying, we need to think also of drawbacks a certain optimisation would have, a range limitation at this stage sounds like quite a high price to pay, for an unmeasurable improvement on a GPU.
Sorry, the branching comment was referring to a suggestion that came up to use bezier or similar joined curves to approximate the tone scale.
I am sorry it’s been very hard for me to attend meetings personally, but I’ve been getting the updates. I wanted to point out that it’s important to contextualize what we mean when we say “slower” or “performance issues”. In OCIO, that is relative to ACES 1, as Remi points out. That’s the measure we currently have that makes the most sense, as it’s what most implementers of OCIO will focus on.
We are not saying the current implementation doesn’t run “in real-time” or relatively quickly - but it is slower in comparison to ACES 1, and that’s a hard thing to justify to implementers, especially if we haven’t done the work to explain why, and why it’s worth it. This is where the work of an implementation group is so essential and necessary. We appreciate the opportunity to chat with other implementers on the 11th.
Looking again at this, the maths can be simplified still further. Because the tone scale is clamped at zero, all the abs and sign functions in the Y <> J conversions to deal with negatives are redundant. And the two max functions in the tone curve can be reduced to a single one applied up front. There are also a couple of multiplies and divides by 100 in there which cancel out.
So a simplified Python version of the tone curve is:
# Clamp input at zero
J_in = np.maximum(0.0, J_in)
# J to Y conversion
A = A_w * (J_in / 100.0)**(1.0 / (surround_y * z))
Y = 1.0 / F_L * ((27.13 * A) / (400.0 - A))**(1.0 / 0.42)
# Apply tone scale
f = m_2 * (Y / (Y + s_2))**g
Y_out = f**2 / (f + t_1)
# Y to J conversion
F_L_Y = (F_L * Y_out)**0.42
J_out = 100.0 * (((400.0 * F_L_Y) / (27.13 + F_L_Y)) / A_w)**(surround_y * z)
If it helped, you could even pre-calculate surround_y * z, 1 / (surround_y * z) and 1 / F_L .
To me, it’s definitely worth making sure that years worth of work gets implemented in the best, most thoroughly tested way possible, within our resource constraints. I don’t have doubts we can work together to find an acceptable solution at all!
Apologies if I was not clear. I meant “worth it” in its current form.
The VWG did the best possible job with a very complicated (one may say impossible) task.
One of my concerns for instance (apart of the overall complexity) is the out-of-the-box “look”. Without a default LMT, there might be a misunderstanding about the what the system is capable to produce (aka a pleasing rendering).
But I guess this might come later down the road like an ACES 2.1 update ?