Having just watched Alex Fry’s ZCAM experiments, and seen Jed’s efforts, it seems that there’s a very interesting demonstration that potentially illustrates the importance of a suitable brightness metric for the dynamic range of image formation.
This is predicated on the idea that the most important facet of image formation is the brightness representation, which of course is a deeper rabbit hole caught up in HVS elements and other facets. To be clear, the term brightness employed here relates to the absolute stimulus scale. Lightness would be the relative processing of the stimulus in relation to higher order processing including spatial and temporal components. The former term brightness is intended here. The latter term lightness, while important, is beyond the scope of spatial per-sample image formation.
If one does not subscribe to the general idea of the importance of brightness, read no further.
Specifically, in the LDR version of Mirror Performer, the accidental compression as the volume ascends the sRGB gamut boundary, is yielding something that @daniele noted in one of the VWG meetings recently, as being too aggressive. That is, he noticed that the attenuation of chroma appeared too strong. By comparison, we can take the extreme case of the errors and breakdowns in the ACES renderings of the usual suspects in Blue Bar, Red XMas, Reactor Tube, Brejon Lightsabers, etc. as existing on the opposite end of the continuum. Even in the more nuanced take of Jed’s work, we can see that parametrically driven chroma attenuation can exist as either too aggressive or not aggressive enough.
Sadly, it felt like a terrific opportunity to discuss chromatic attenuation further was missed. As such, given the excellent demonstration using EDR encoded video that Alex Fry recently posted, I’d like to draw attention to a couple of points, specifically with Mirror Performer. For the record, this post ignores the fact that colour management isn’t possible I believe with the Jed approach due to stimulus escaping the volume, hence some skews happen. The general premise here I believe is not significantly adversely impacted by this.
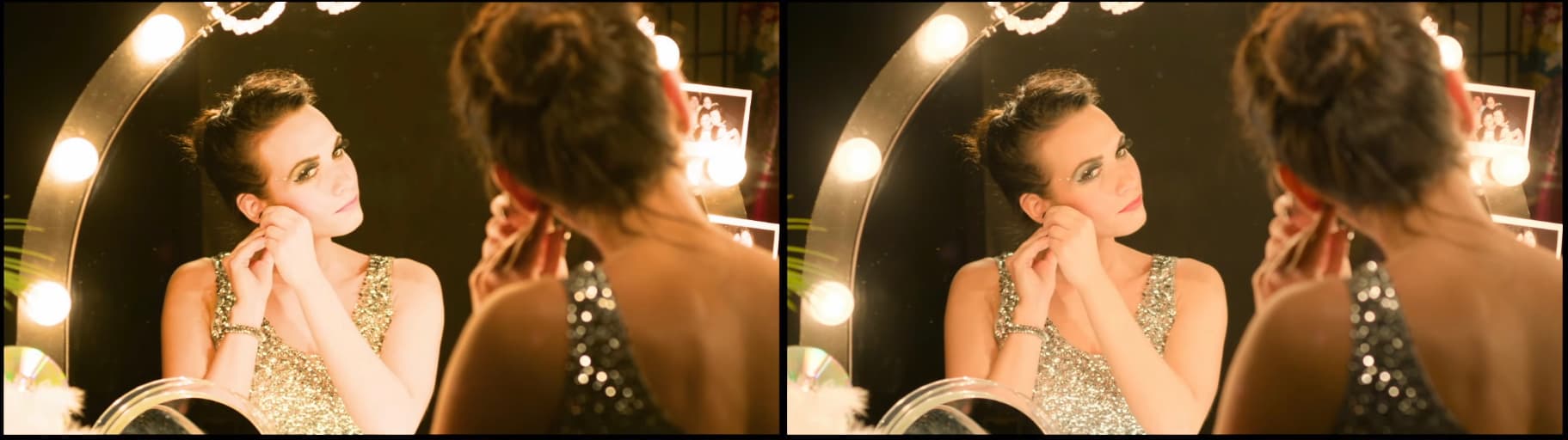
I have no real means of screenshotting the differences in the EDR variation of the reformations. If you have access to a EDR 1000 type of display, please have a look at Alex’s demonstration.
Looking at the LDR rendering from this thread, the one that @daniele cited as being too aggressive, and captured in the above still images, we can see that the chroma attenuation is indeed potentially greater than required. But that leads to a more useful and interesting question of “What defines too aggressive or too weak? Is there an underlying mechanic at work?”
Given that typically, for non spectral based stimulus, the peak brightness range will rest along the achromatic axis of a medium. Chroma laden primaries or paints will almost always achieve a lower “brightness” at maximal emission / reflectance of stimulus. This means that achieving a smooth-with-respect-to-observer-sensation appearance that is maximally fit to a medium, the achromatic axis will provide the greatest breadth.
Chroma laden mixtures will implicitly be of a lower “brightness” here. Brightness in this case is used in scare quotes, because a majority of the metrics used to derive brightness are based on the additivity facet of luminance. Heterochromatic brightness is not additive in nature, however in most instances, the same rule of thumb applies; chroma laden heterochromatic stimulus mixtures will typically be of lower brightness than the achromatic spine of representation in a medium.
This means that there is a fundamental exchange between the maximal brightness and the maximal chromatic representation. Hence attenuating chroma can be used as a mechanism to achieve greater brightness, and is in fact the sole way to do so in most well behaved mediums.
If we look at the LDR rendering above, and compare against the EDR rendering cross linked, we can see a very interesting reversal happen. In the LDR case, while the chromatic attenuation is likely too strong in the ZCAM case, it visually cues the light transport in the scene given the subject’s distance to the bulbs. Conversely, in the EDR version, the ZCAM case ends up almost posterized in terms of sensation of tonality, and as a result visual cueing of the light transport present, across the face.
The Jed Jz demo on the other hand is somewhat flipped around; in the LDR formation, the degree of brightness potentially disrupts the light transport cues in the scene, while the EDR example attenuates the chroma accidentally more greatly, and greater visual cueing is presented.
I reckon this also can adequately describe the the happy-yet-accidental crosstalk rate of change in decent models such as ARRI’s LogC / K1S1, where the per channel crosstalk attenuates at a rate that more closely matches expectations of visual cues for light transport.