I put together a Tonescale Model Selects colab, with the most successful models in my trash pile of experiments.
I would say they all have different pros and cons.
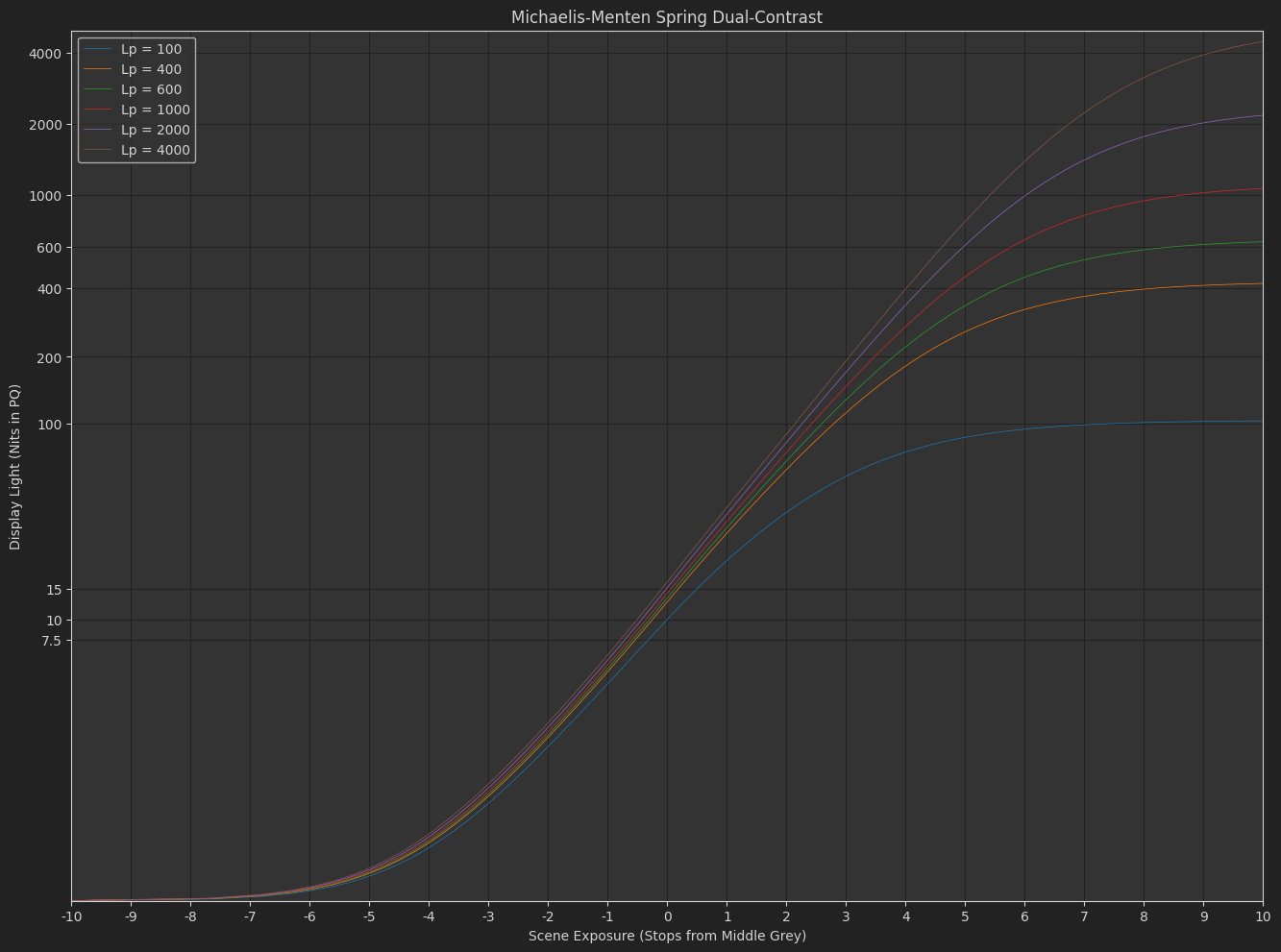
I like the simplicity and look of the pre-tonemap contrast with linear extension + michaelis-menten function. The Michaelis-Menten Spring Dual-Contrast model in the above colab is the one I will use moving forward I believe.
The post-tonemap contrast Michaelis-Menten Spring function is very neutral and performs very nicely in HDR, but the shadow contrast is too low in SDR. This is what I was previously fighting by modeling an exponent that started higher and decreased as peak luminance increased. I never liked this. Included in the Michaelis-Menten Spring model is an idea for a “default tonecurve lmt” which adds a bit of contrast to compensate and seems to work okay through the transition to HDR.
And I figured I would throw in a refinement of an earlier experiment with the Piecewise Hyperbolic Tonescale Model. In this one I do like that values below middle grey can be kept strictly linear if desired. It is more controllable. I also like the stronger highlight appearance, and the ease with which you can transition from SDR to HDR with a consistent contrast.
All models include a parameter for surround compensation using an unconstrained post-tonemap power function.
Tonescale_Selects_v01.nk (33.8 KB)
Here’s a nuke script with all the models as well.
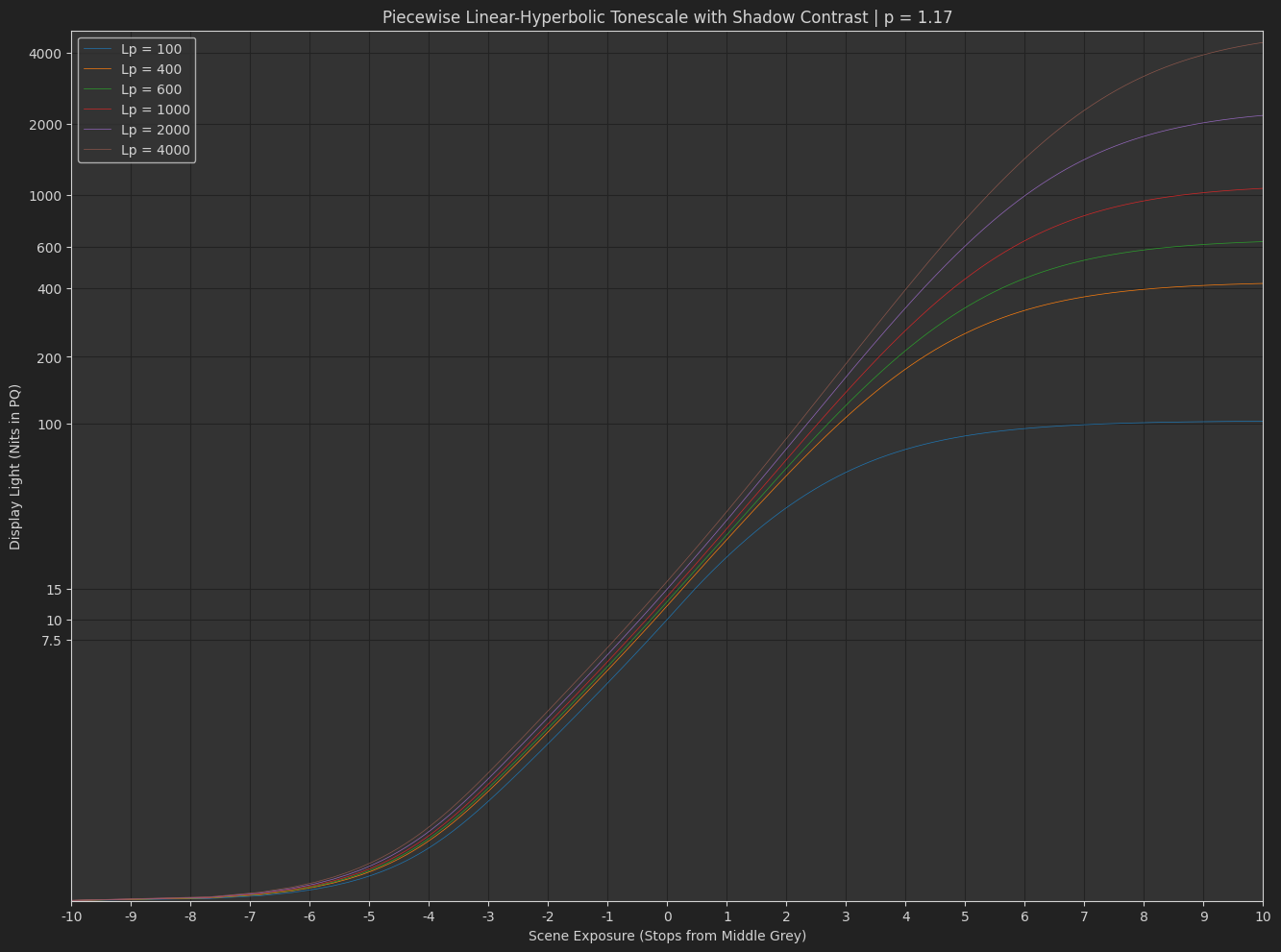
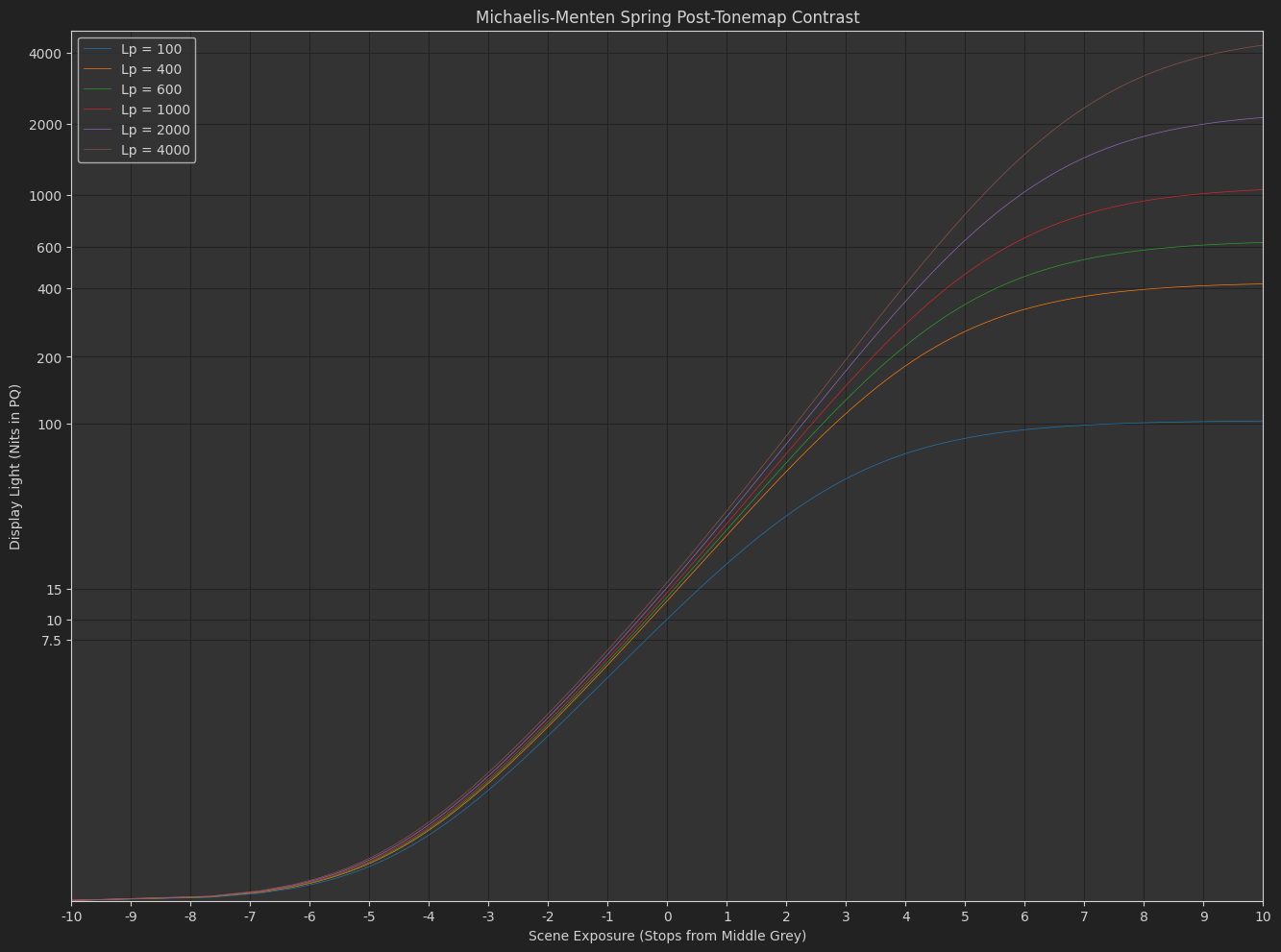
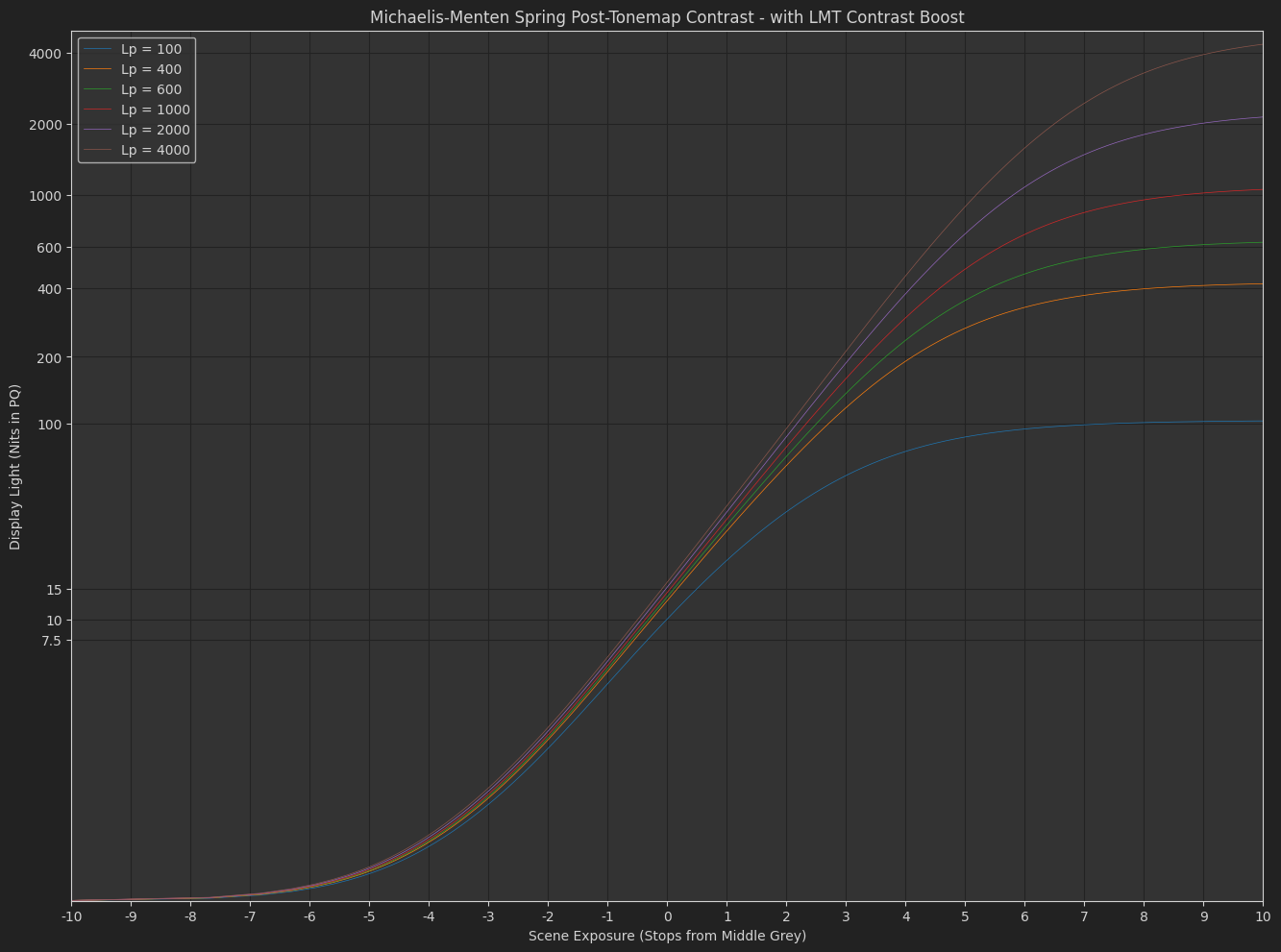
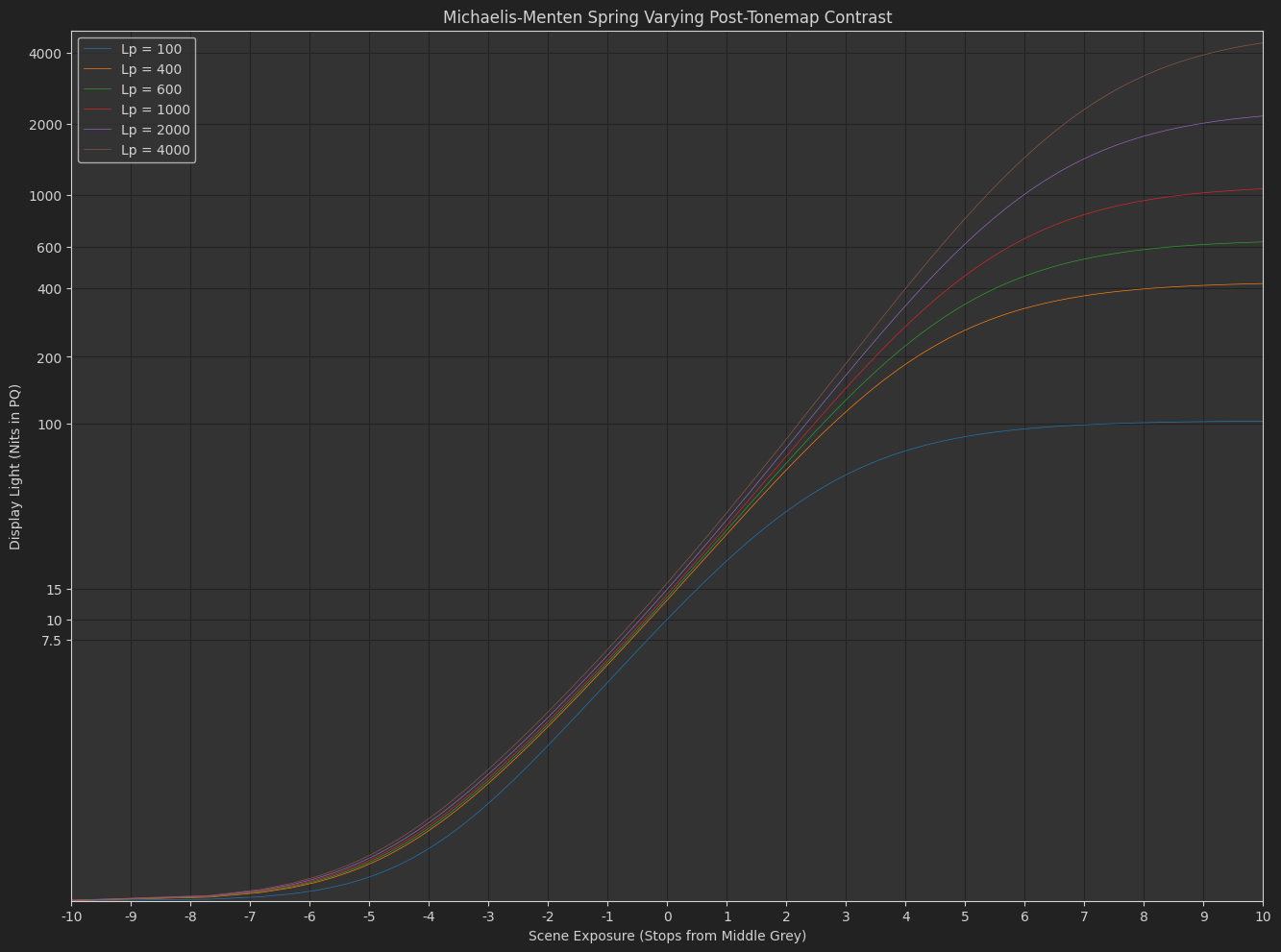
I’ve also pushed OpenDRT v0.1.2 that uses the “dual contrast” tonescale model above.