Here is a version of the tone scale formula which compensates for the reduction in exposure introduced by the (Display) Flare compensation.
As the first equation does not change the slope at zero (besides the gamma value) one could change the order without significant difference, but I find this cleaner.
t_1 as most of the parameters is there to give us leverage on many different issues at once.
Some are:
- it compensates the display flare without moving 0.0; this is important in a relative black system
- it compensates for the shadow wash-out, which is introduced by the first part of the equation
- most importantly, it compensates for the kink you get from the toe of the log grading space toe, this is important for the “gradeability” of the system.
with t_1 = 0.0 we get a ACEScct to Rec.1886 mapping like this:
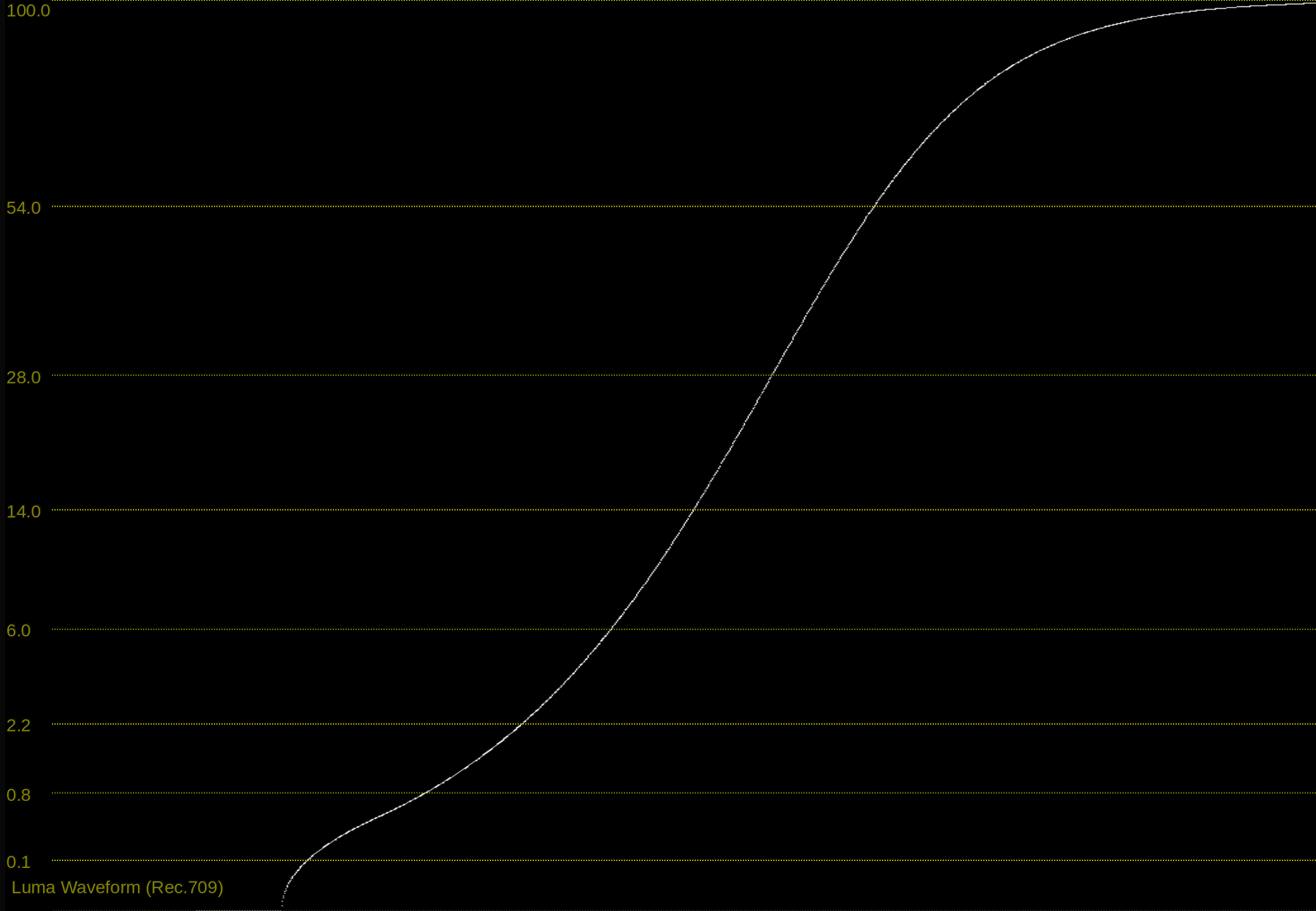
This makes grading in the working space very unenjoyable.
with t_1 = 0.01 we get a ACEScct to Rec.1886 mapping like this:
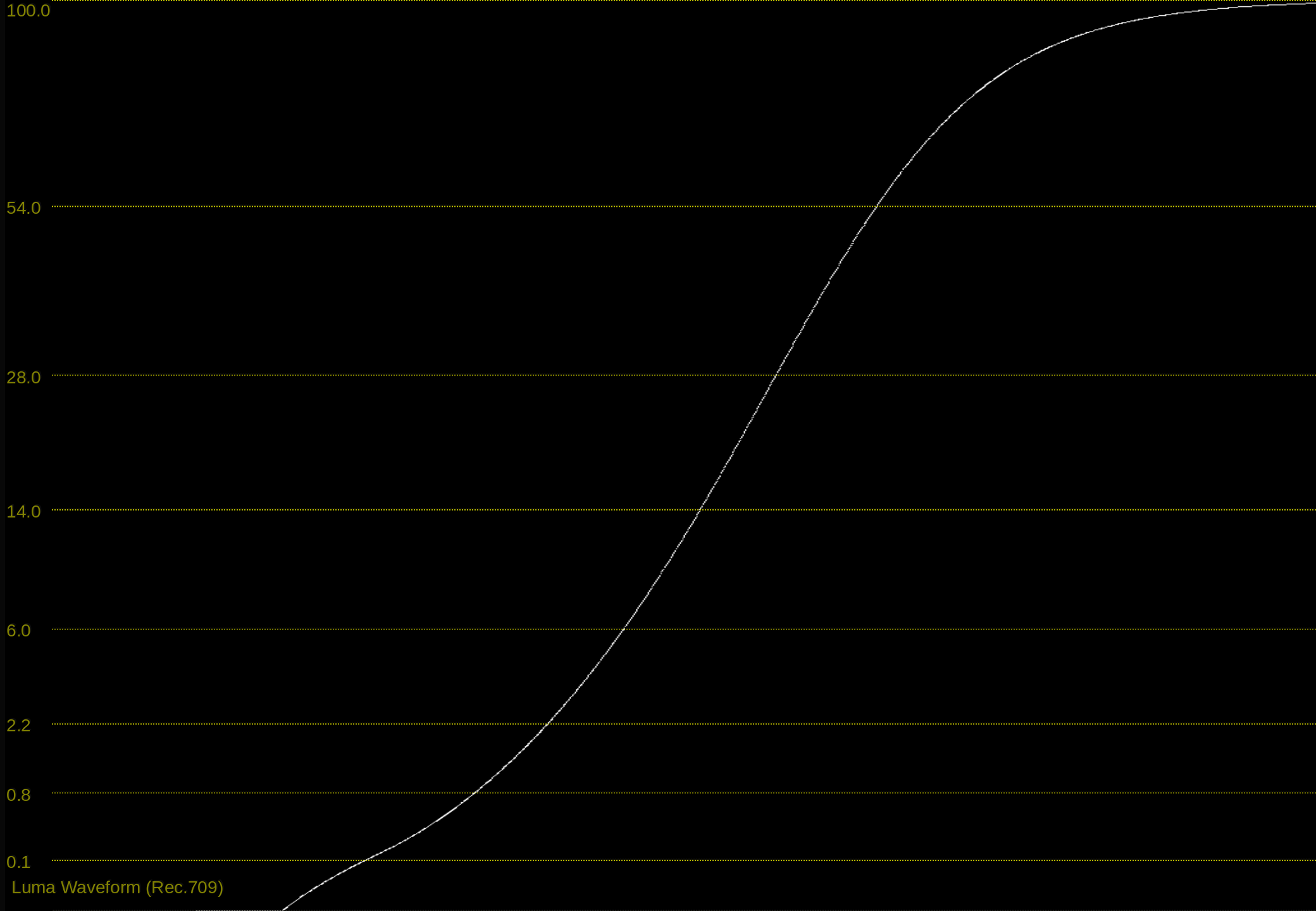
A bit better but still not good
with t_1 = 0.05 we get a ACEScct to Rec.1886 mapping like this:
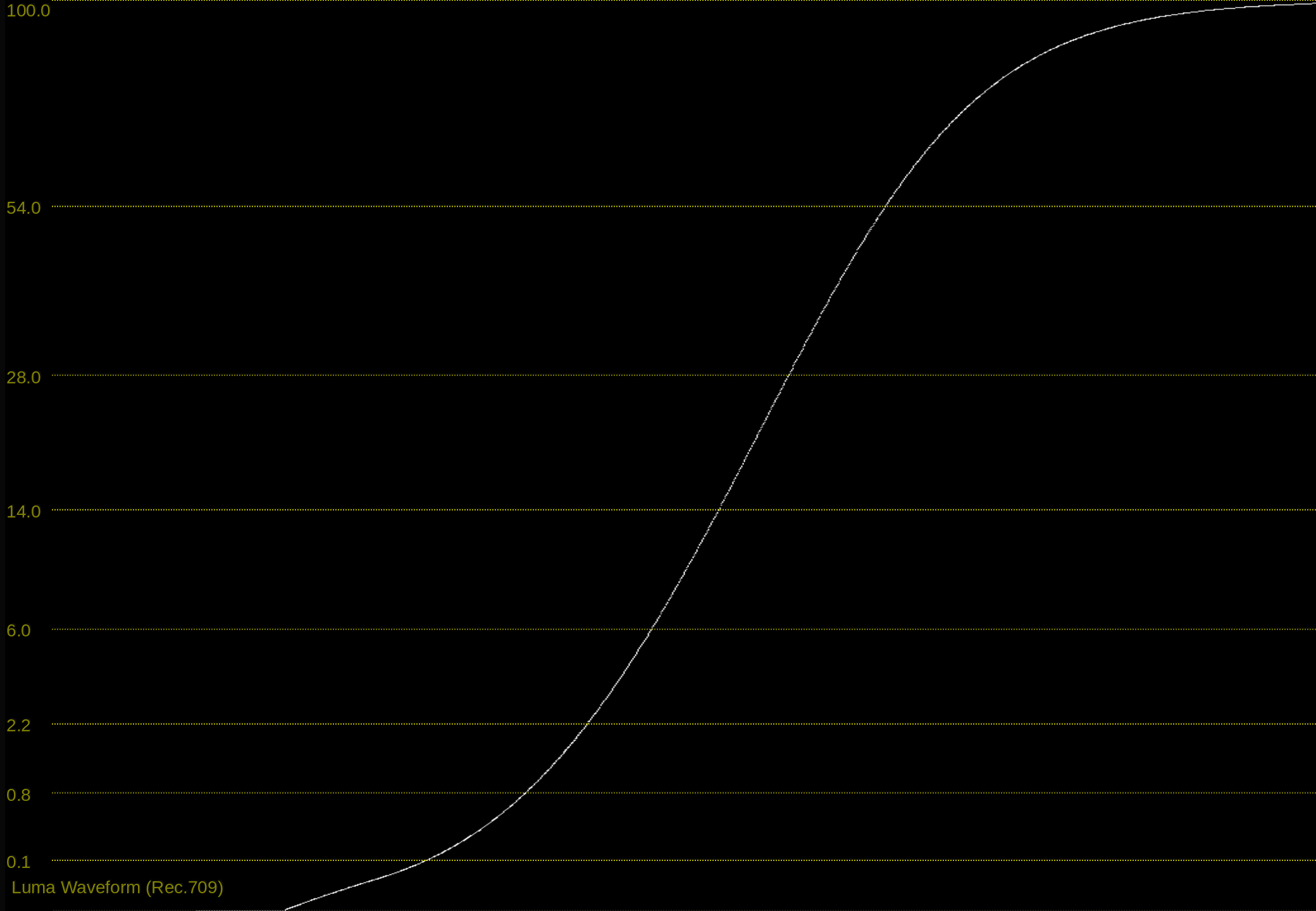
Even better.
So the right value of t_1 is influenced by many factors, but mainly by the toe function of the default grading space and the EOTF of the display.