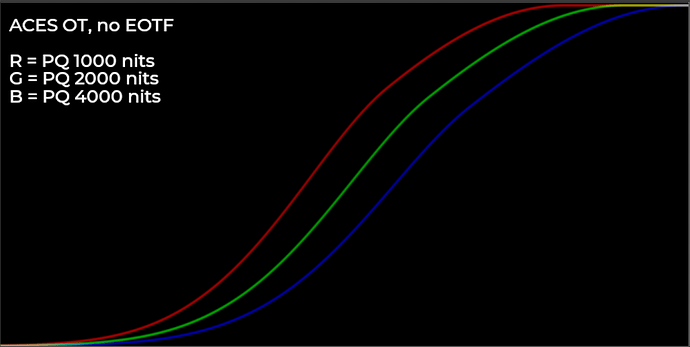
Wouldn’t this create a “kink” though ? I don’t have a HDR monitor to check but I was curious about it.
Also, I am linking here this topic that is related :
Hope this helps, Chris