From the meeting…
@nick:
The idea of kind of being able to slightly exceed the display gamut and having a clamp as a sort of a master in clickable.
I find it peculiar how this idea comes up over and over again.
How can this work?
Every single stimulus encoding present in the headed-for-display encoding will be rendered as something. That something is fundamentally unknown if this is permitted. It strikes me as problematic in a system that is now aspires to be a management system?
Example:
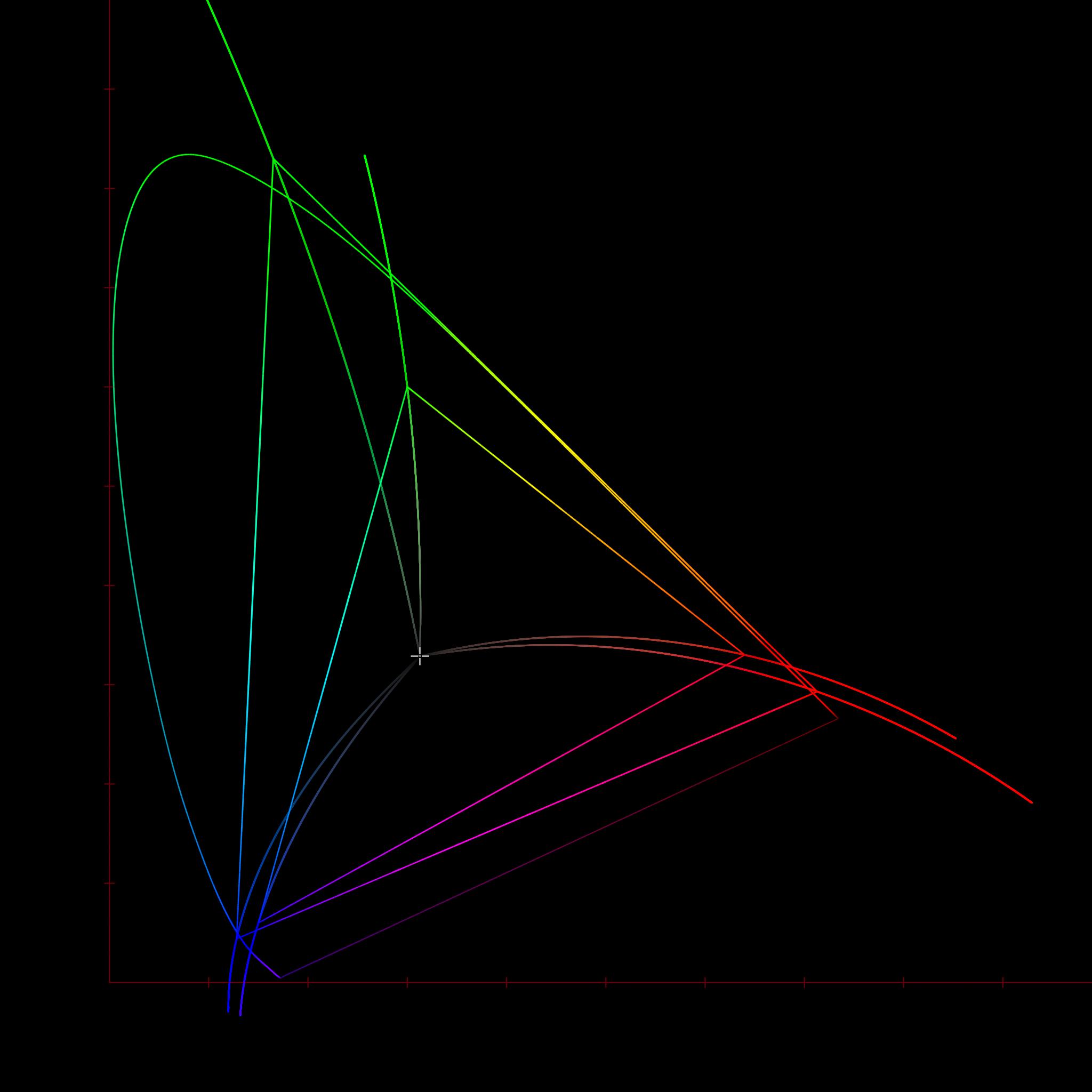
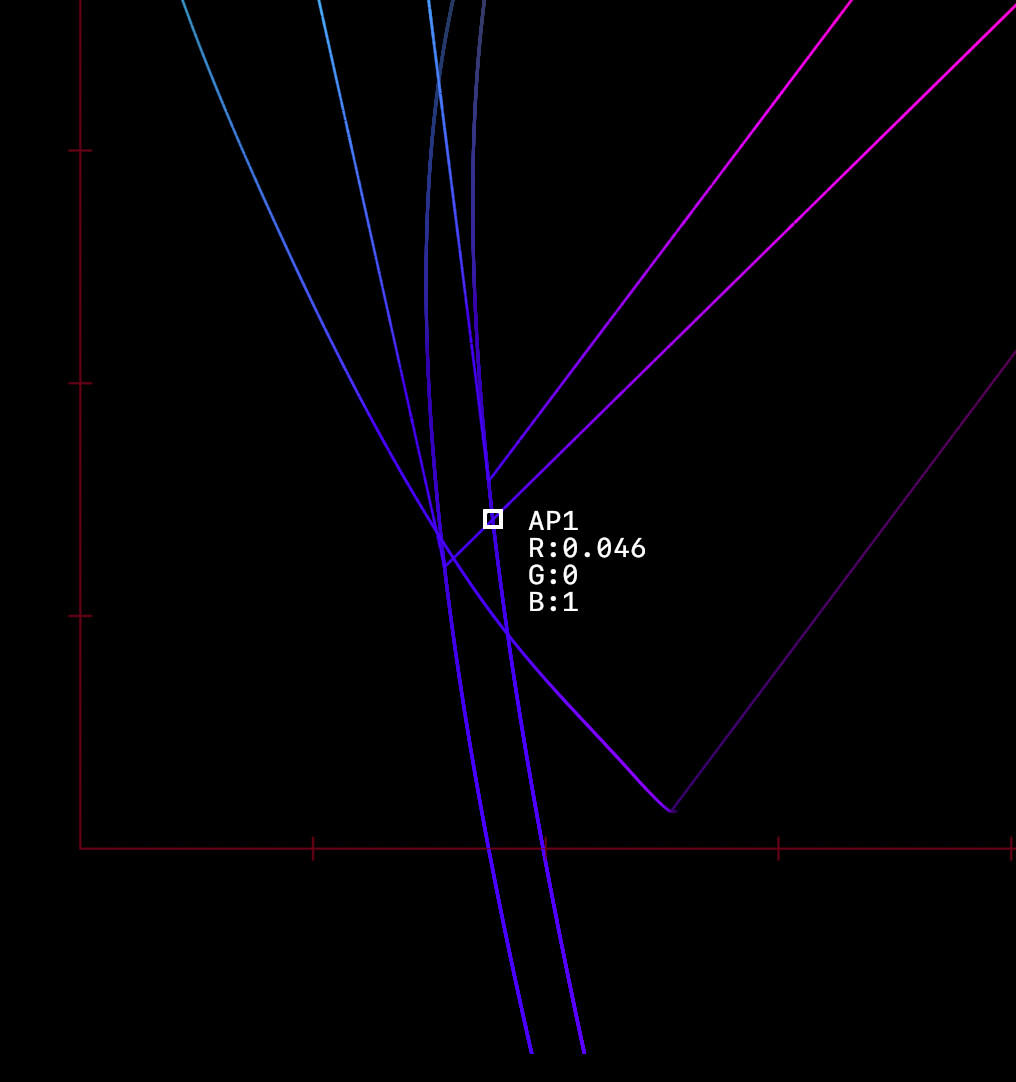
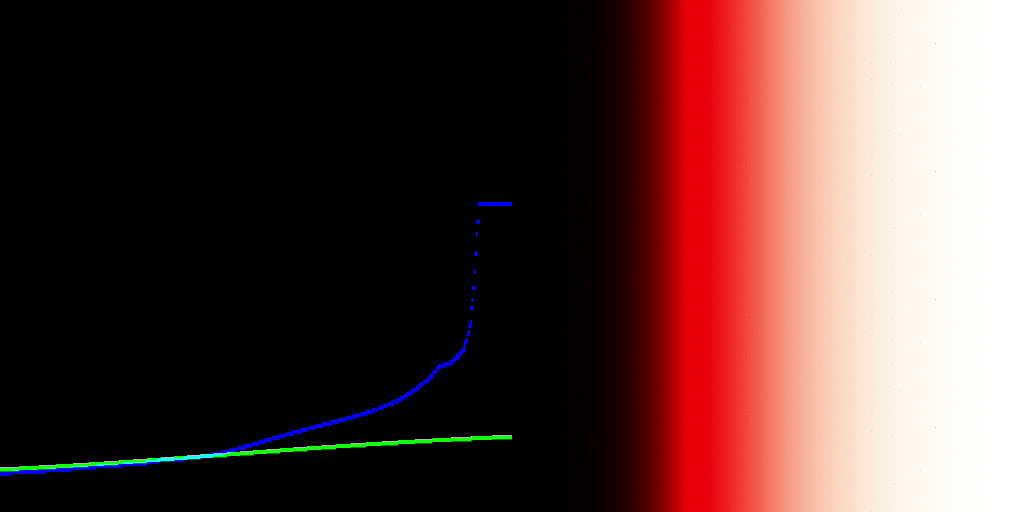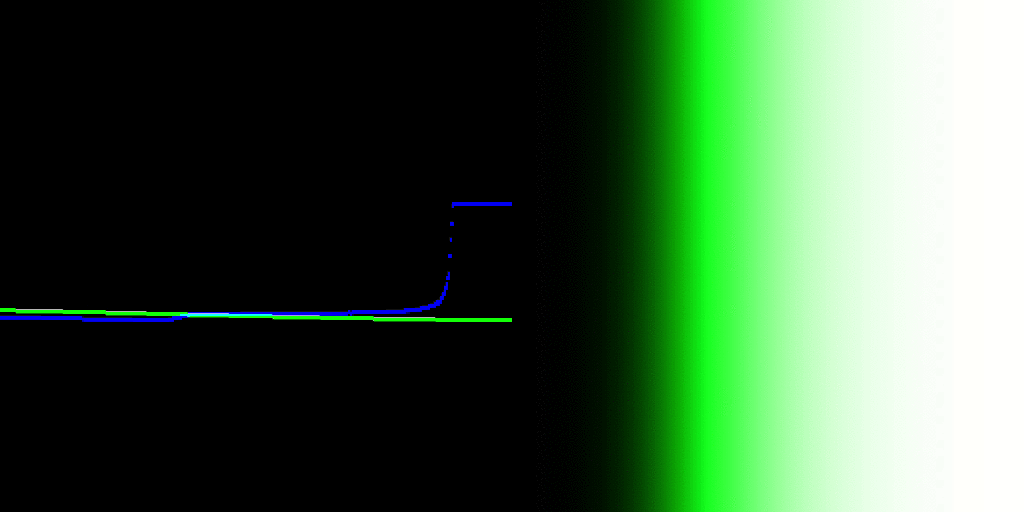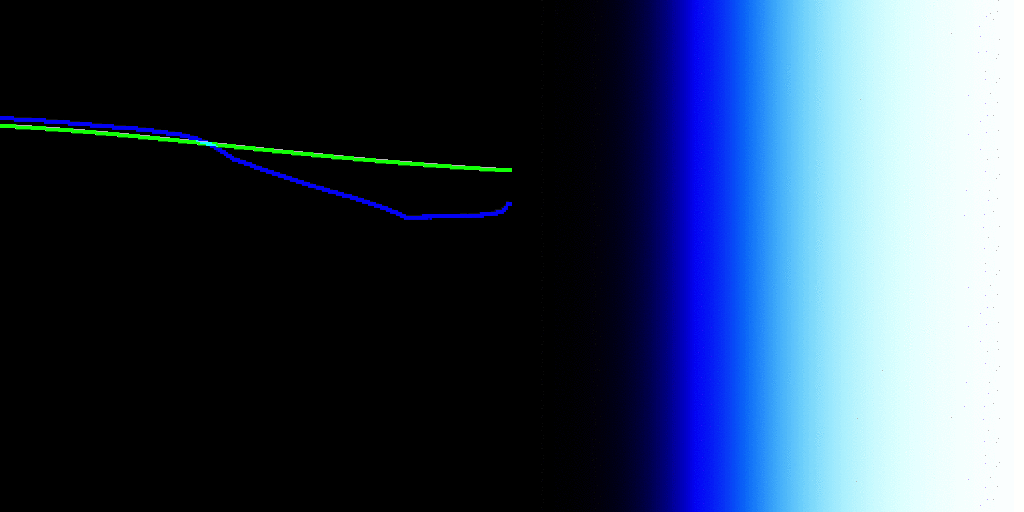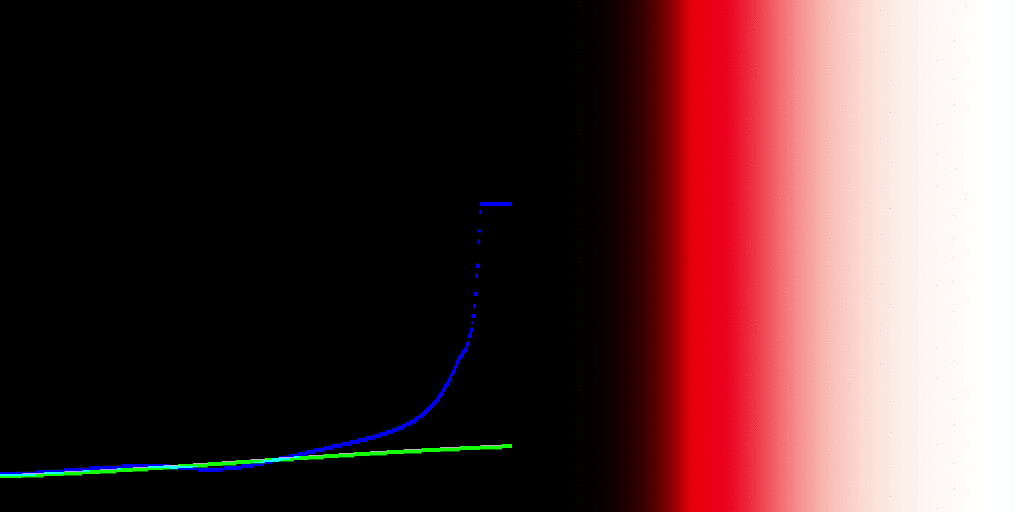
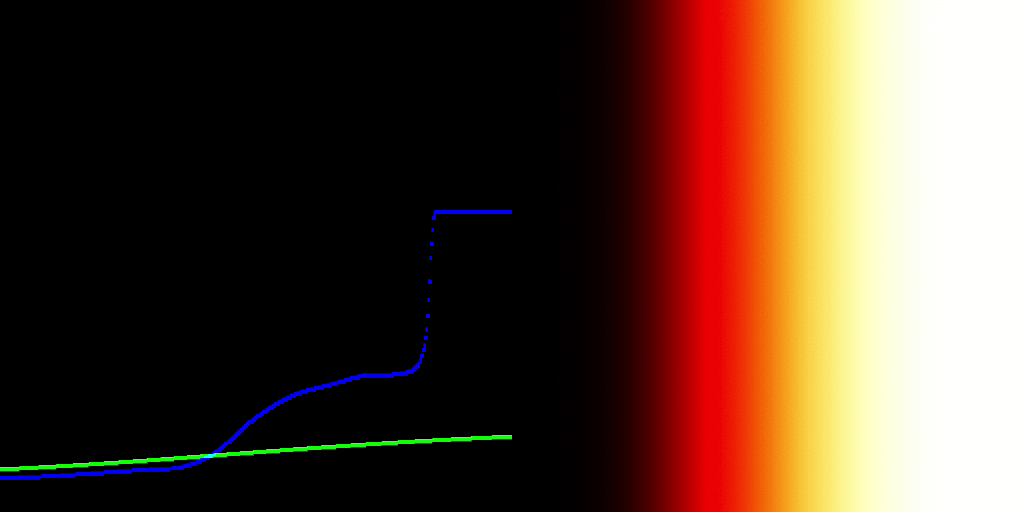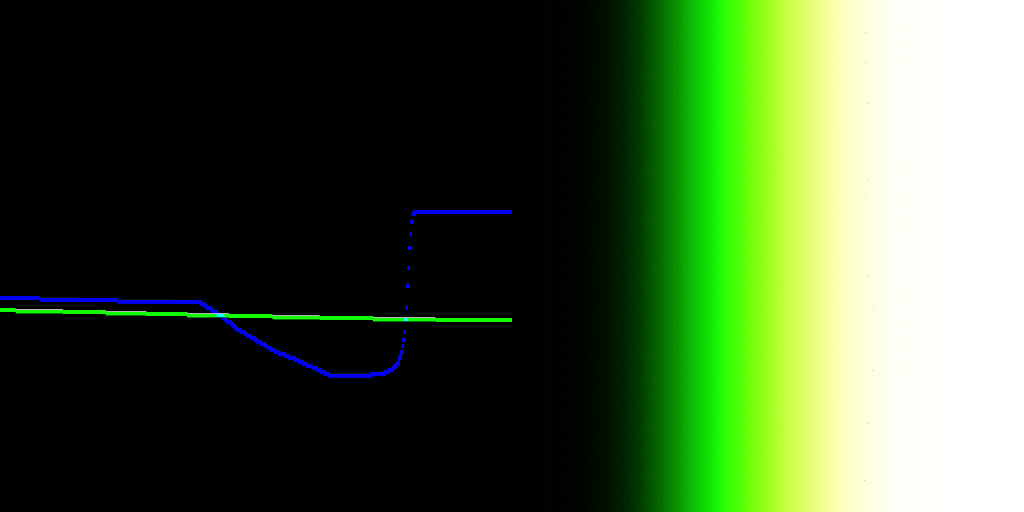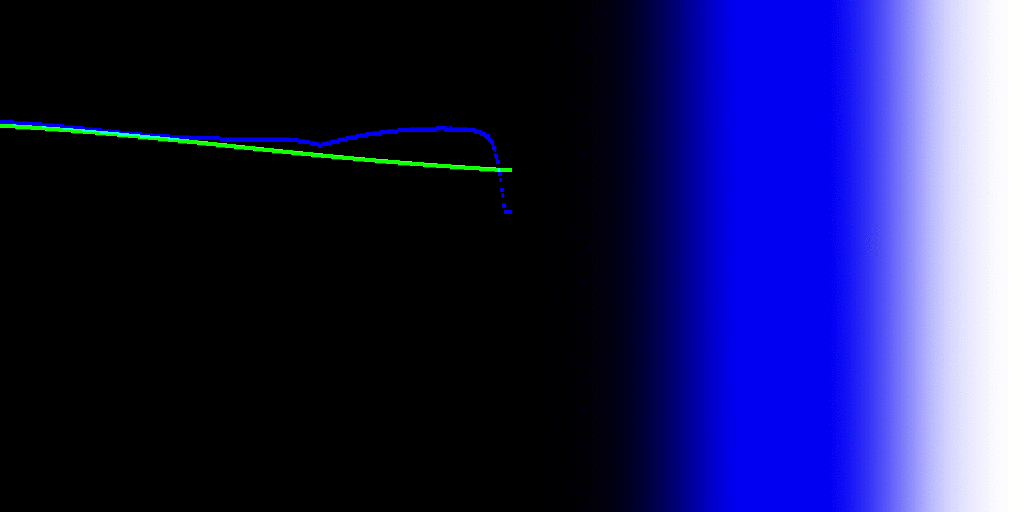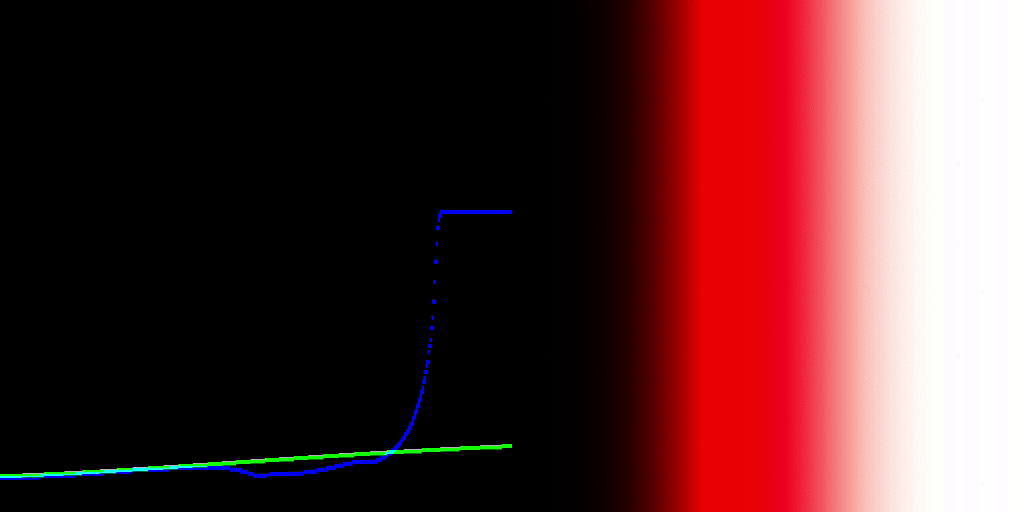
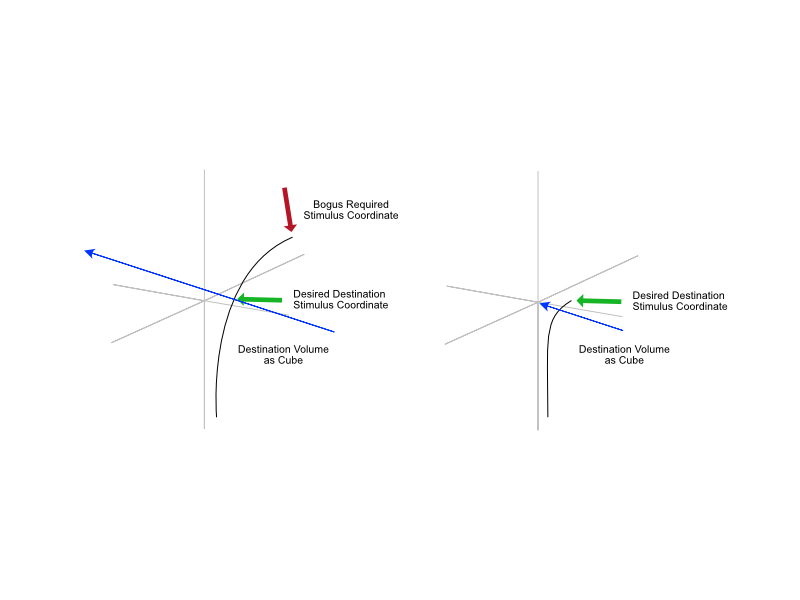
In medium A, the image formation yields code values that escape the medium A’s expression range, either below zero percent or above one hundred percent contribution. Those code values are emitted as as some stimulus, always.
Where do we sample the code values for to render into medium B? The open domain stimulus encoding heading to Medium A? If so, those values that are escaping are rendering differently between Medium A to Medium B. All layers of appearance matching appear impossible at this point, as we have created a medium dependency in the encoding.
If we sample the closed domain stimulus code values at the Medium A, then we have an idea as to what stimulus is being expressed, but that’s another rabbit hole.
It feels like there is no control being expressed about what is being sent to a medium, which would appear to undermine everything attempted here?
@Alexander_Forsythe raised an incredibly relevant point here possibly?
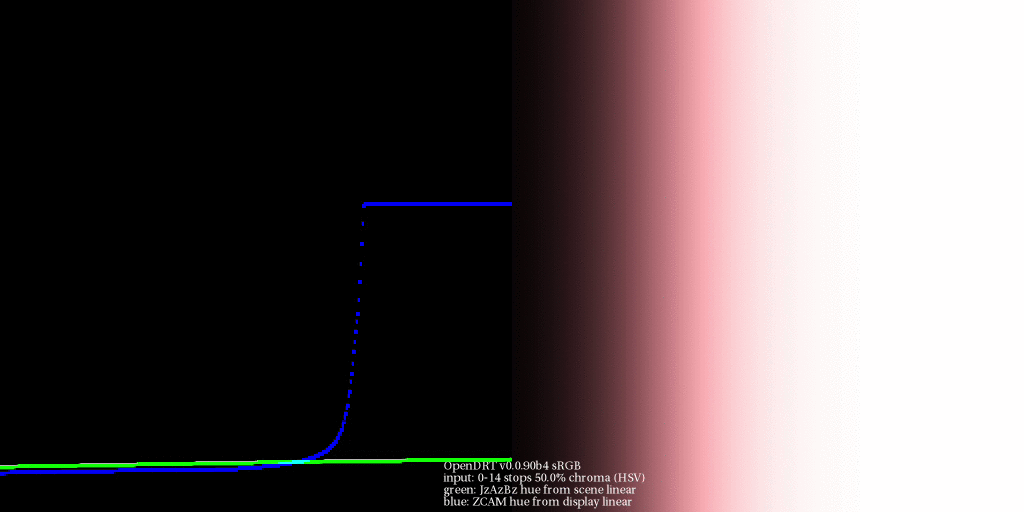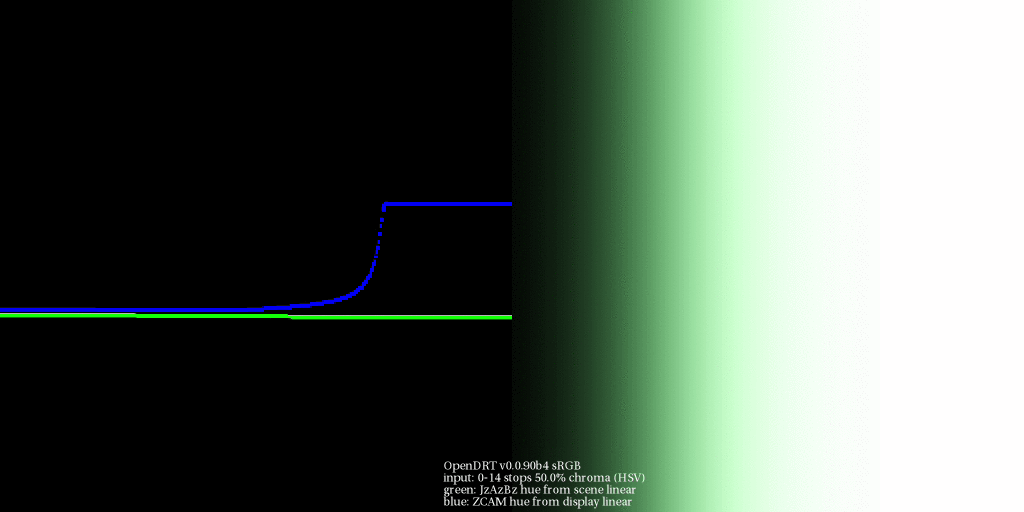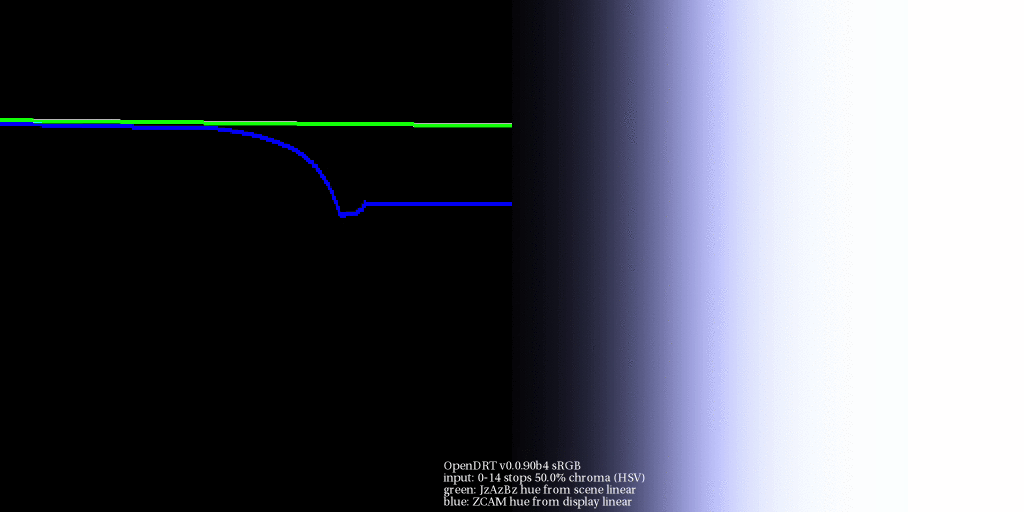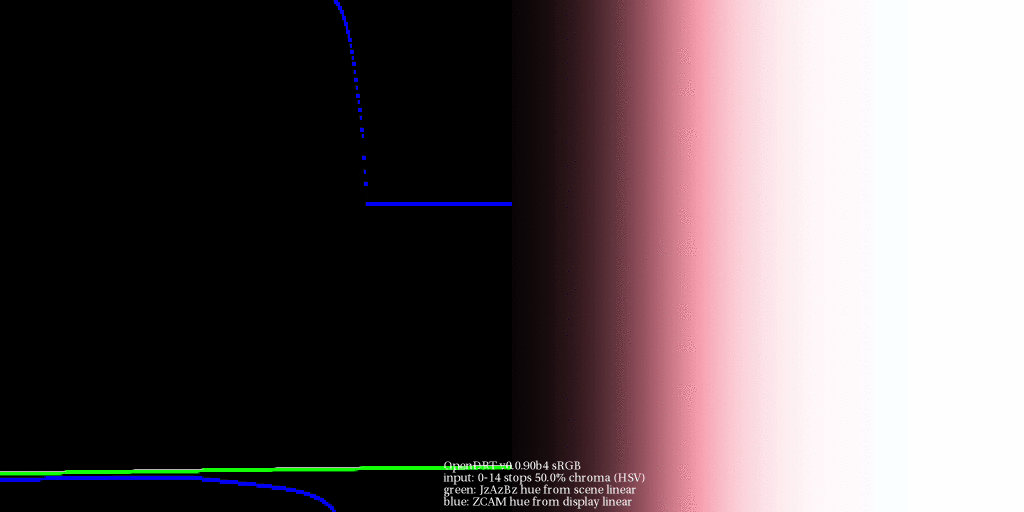
The one thing that I was particularly interested in is looking at the perceptual correlates before the transform [the] gamut mapping / compression step and then after the gamut mapping compression step to see […] how are things being effected by the gamut compression and moving […] to observe display code values.
I believe this ties in, with rather large implications on the resultant imagery formed, to the explorations Daniel has been doing regarding gradients via the gaussian overlaps. The nature of the footprint compression will impact the projection of gradations into the destination volume. This will be manifest rather noticeably as a disruptions of smooth brightness / chroma tonality in shallow depth of field / blurry regions that have high levels of excitation purity differences? Flowers, high chroma lit objects, etc.
I think oscillating radial sinusoidal patterns could help to form a reasonable test bed here, oscillating from one highly excitation pure region to another different radial angle? I know that similar patterns have been used to derive resampling tests to much effect?