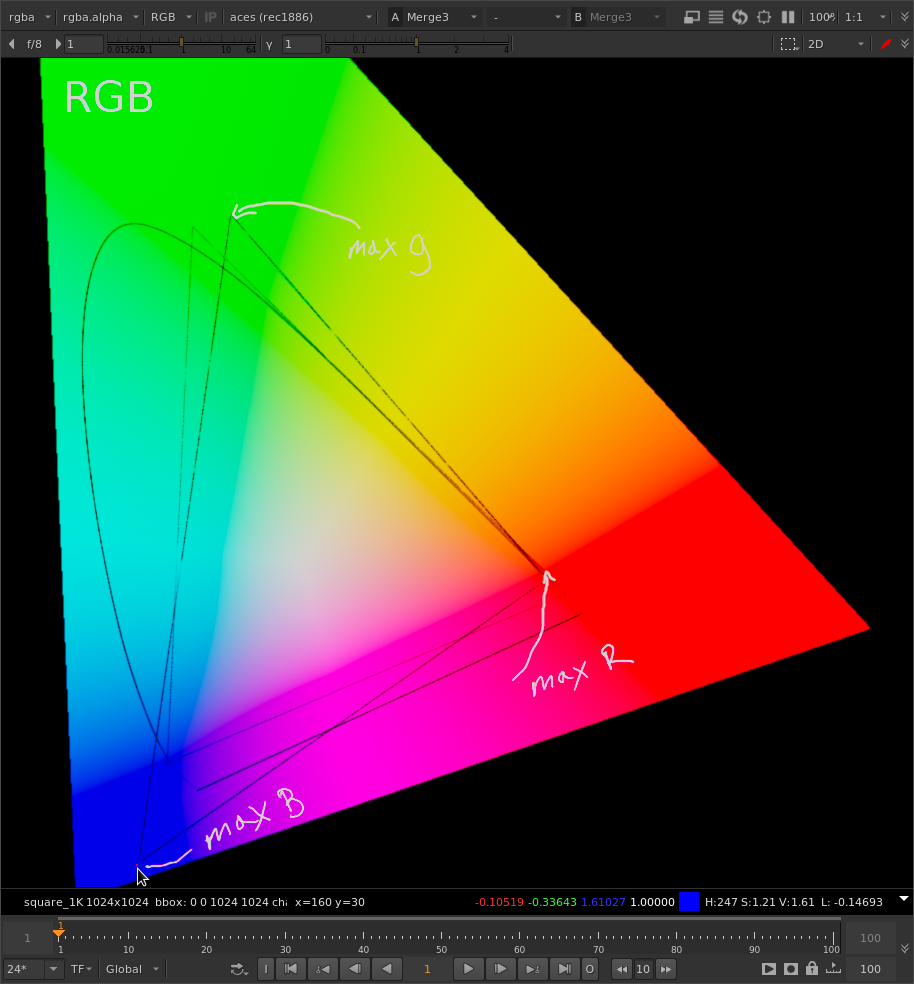
Your current code seems to adjust each component independently:
cd_r = d_r > thr ? thr+(-1/((d_r-thr)/(lim.x-thr)+1)+1)*(lim.x-thr) : d_r;
cd_g = d_g > thr ? thr+(-1/((d_g-thr)/(lim.y-thr)+1)+1)*(lim.y-thr) : d_g;
cd_b = d_b > thr ? thr+(-1/((d_b-thr)/(lim.z-thr)+1)+1)*(lim.z-thr) : d_b;
For example in rgb {1,2,3} 3 gets a stronger reduction than 1.
This causes significant hue shifts away from the RGB primaries. 10+ years ago I shared a chart on this with the ACES group but I can’t find it. Alex or Joseph might recall the chart or at least the red car that turned orange.
One way to avoid this is to have a single controller value.
In my code I now use straight alpha blending towards a gray color.
newrgb = alpha * rgb + (1 - alpha) * Max[rgb] * white;
You might want to give this a try.
This retains the RGB hue.
Do you consider alpha blending to be hue preserving?
(As the RGB space isn’t hue linear (there is no such space AFAIK) there is still a slight shift in perceptual hue)
There might be advantages to using alpha in addition to it preserving the hue.
- Calculating one controlling value instead of three!
- Maybe alpha and the gray background color can be smoothed or low res and applied in a separate step?
- Maybe we can leverage some alpha blending optimizations??
That brings up an interesting Q;
What if we calculate the gamut map (alpha and background) at a lower res than the full image?
(and of course apply it to the full res)
Would this be OK or better for image integrity?
Or would it create edge artifacts?
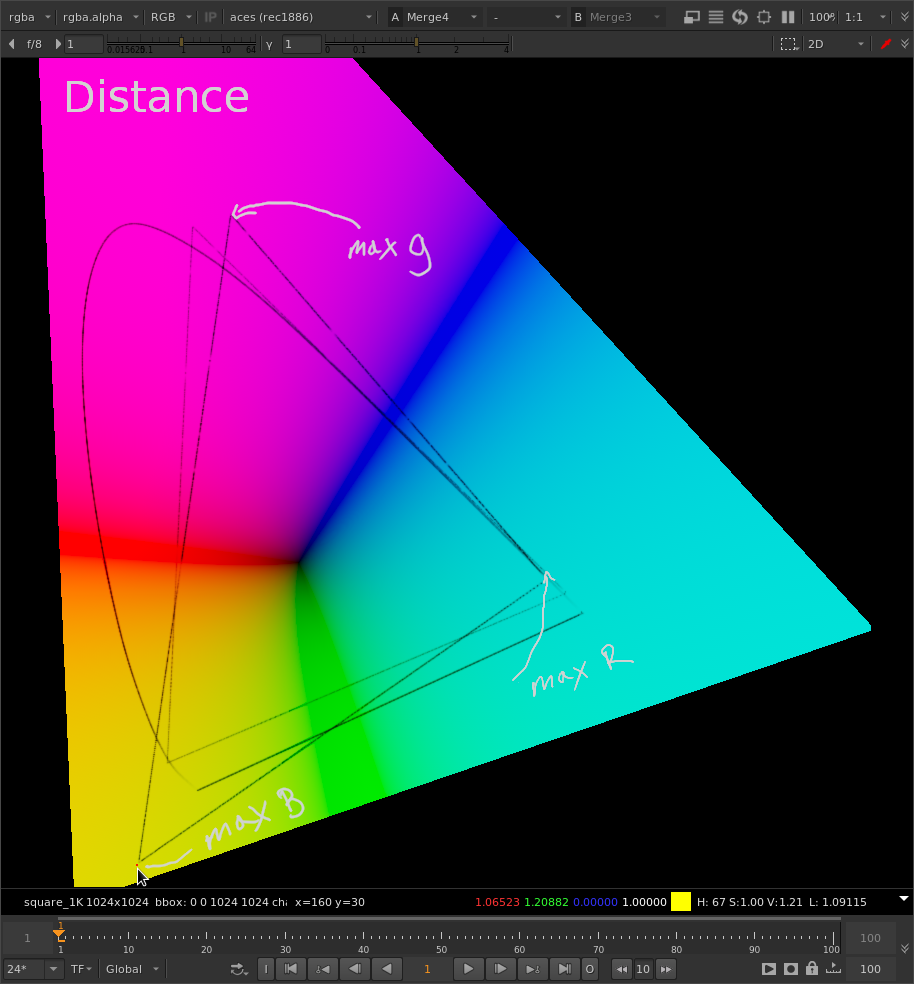
The Limit
The max input can be calculated but maybe it’s overkill.
I have a 2020 to 709 reducer that maps 2020 edge to 709 edge.
This needs to be calculated for each pixel or at least each hue.
For performance reasons I want to get rid of it.
This is an optimized version that finds the 709 value that is equivalent to a 2020 value with same hue as rgb and one channel in 2020 being 0 - On the 2020 edge! Mtx709To2020 is a color space matrix from 709 to 2020.
maxIn = RGBtoSaturation[rgb - Min[Mtx709To2020.rgb ]];
Next, how do you use the limit?
Trivial for Reinhart. Not sure about the others.
After reading a BBC paper I tried using a log curve. Big problem, as in order to fit the curve, with C1 continuity, I had to calculate a scaling factor for each pixel and the math required solving product log, which was slow. I abandoned that curve model.
The conclusion is that for any chosen curve math you also have to have fast math for calculating its input to output range scale factors while maintaining C1 continuity. That’s why I’m pretty happy with Reinhart. But I’d like to see alternatives.
Regarding the curve shape.
Is there a significant visual difference if the various math curves are closely matching?
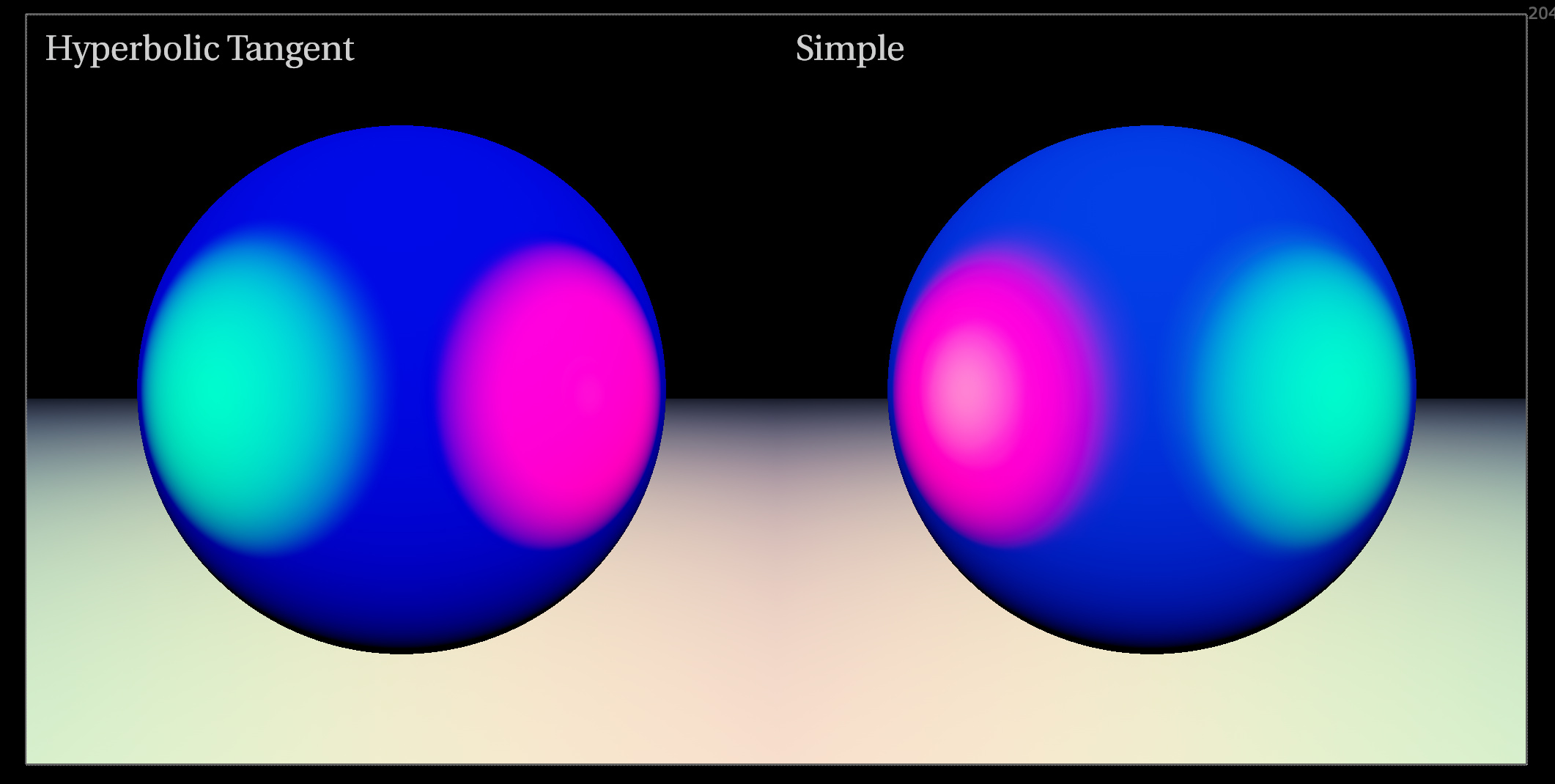
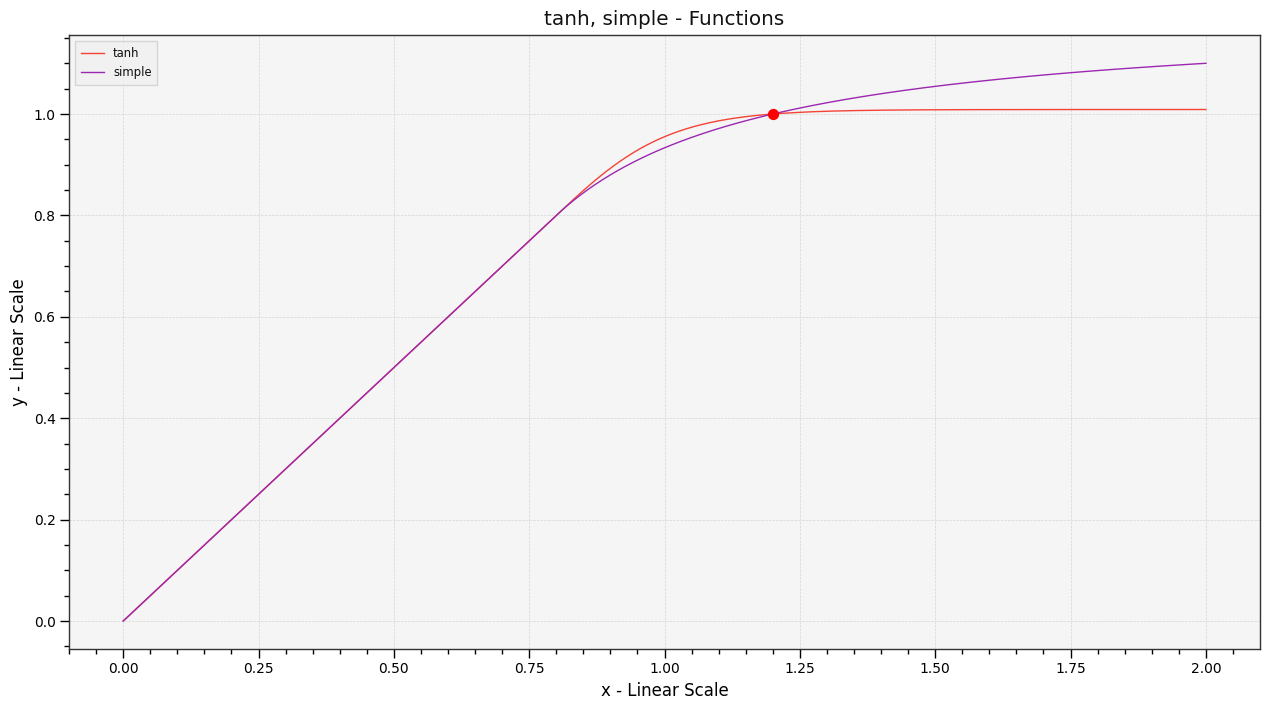
Maybe Reinhart’s simple math (1/1/x) is better for performance reasons? Can we do tanh in realtime on GPU?
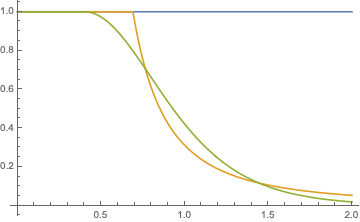
Here are two closely matching curves tanh (green) and reinhart (yellow).
They have different starting points (0.4 and 0.69) to make them match.
They have slightly different shapes. Does it actually make a visual difference?
And here are the derivatives.
tanh has C2 continuity? Does it actually make a visual difference?
Is there any other aspect than visual appearance that we need to consider?