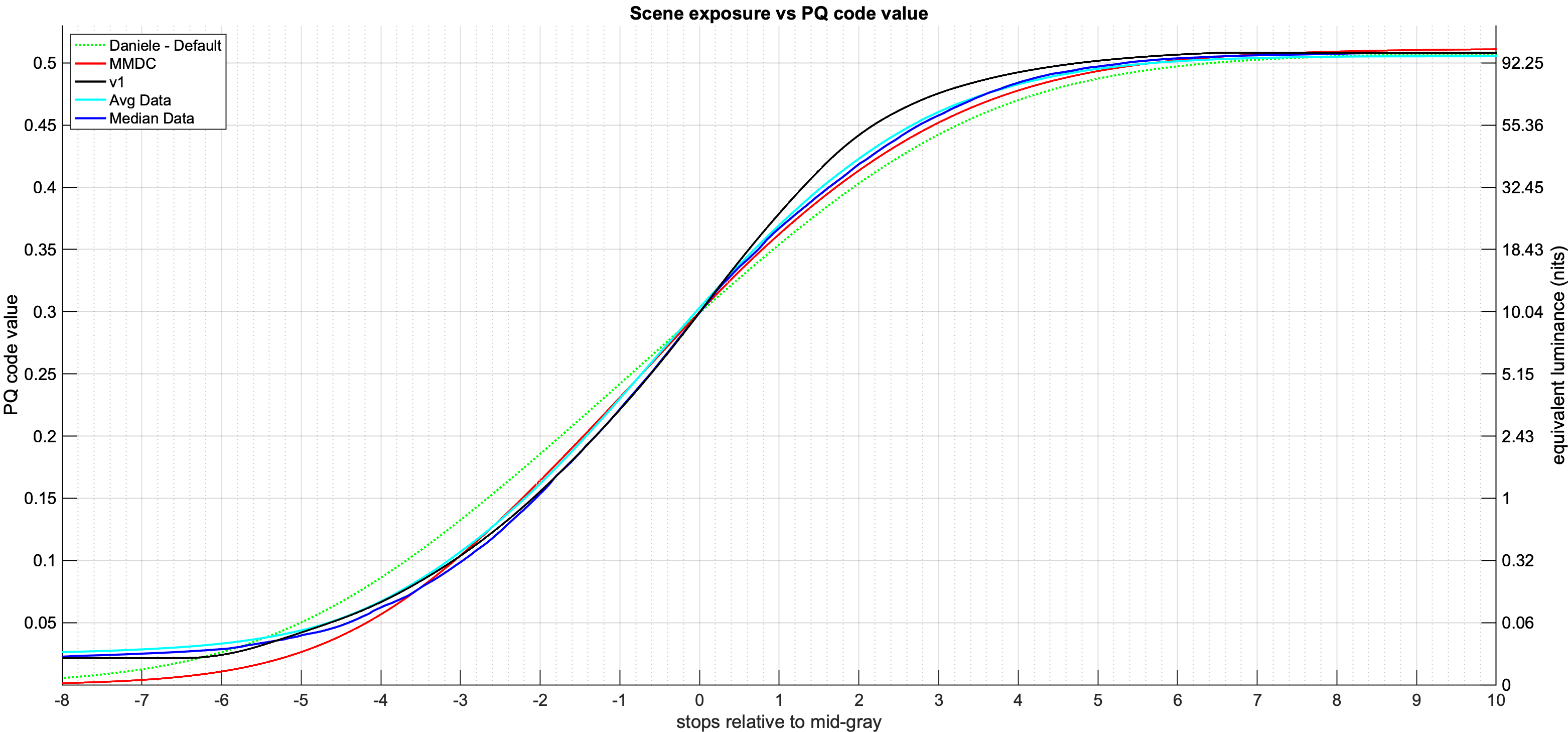
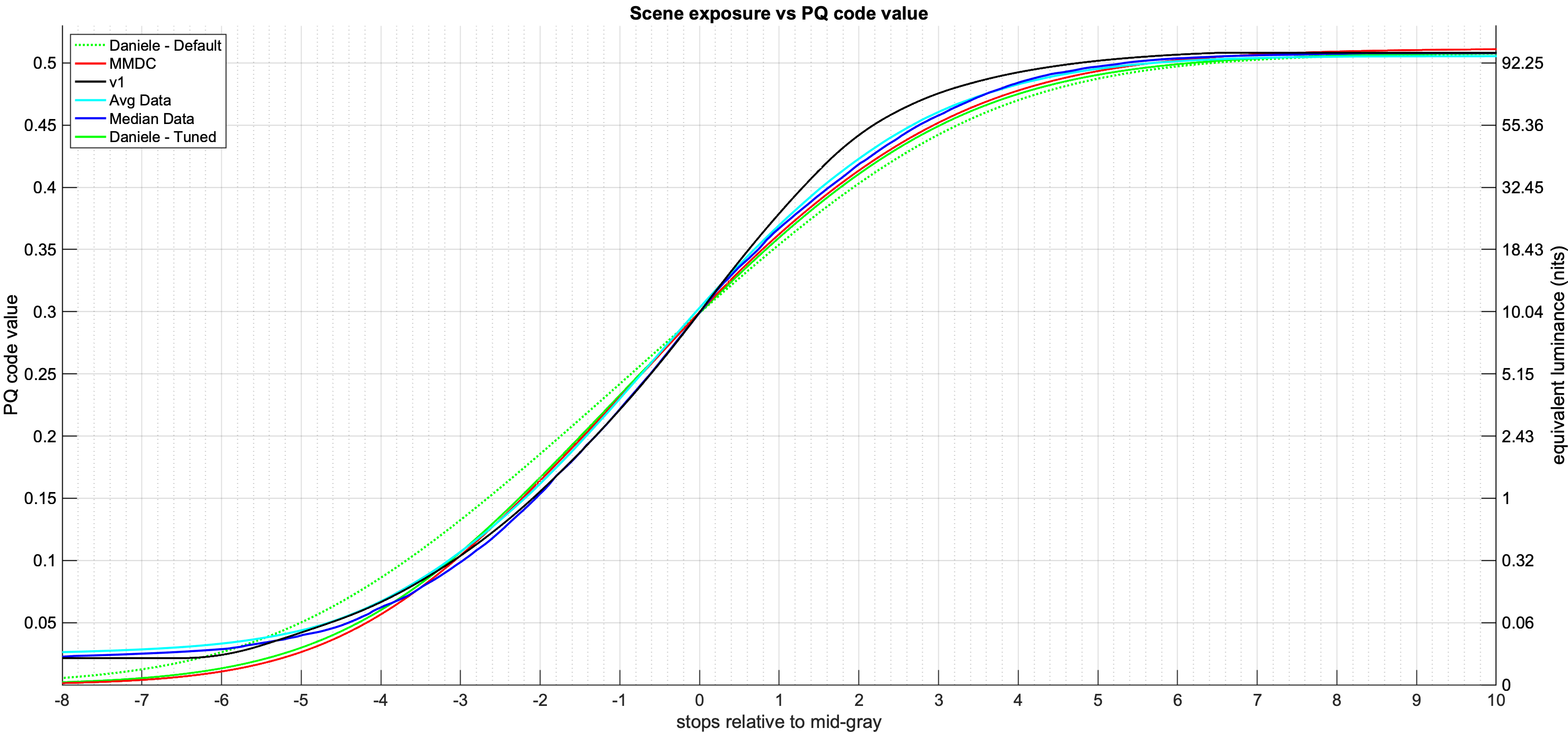
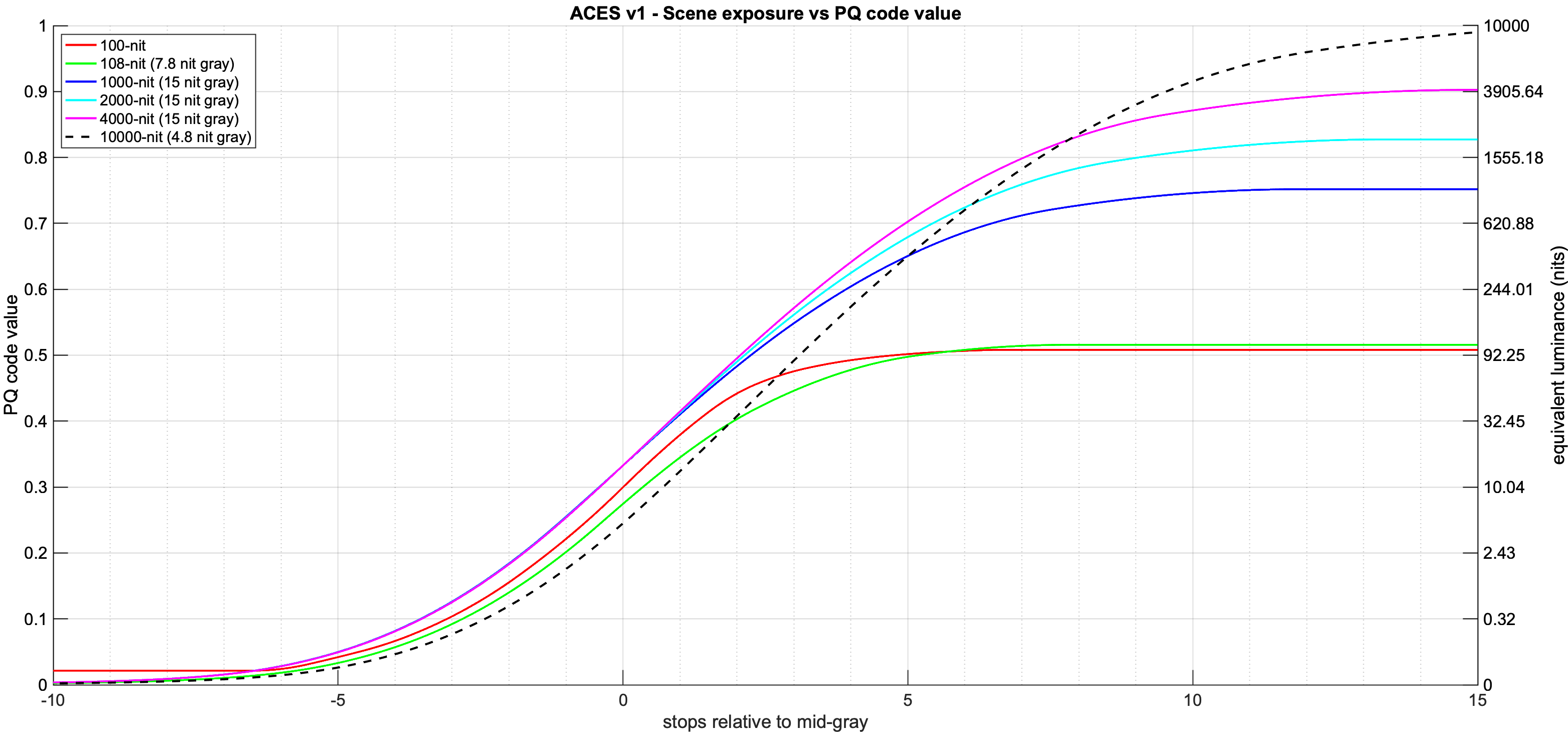
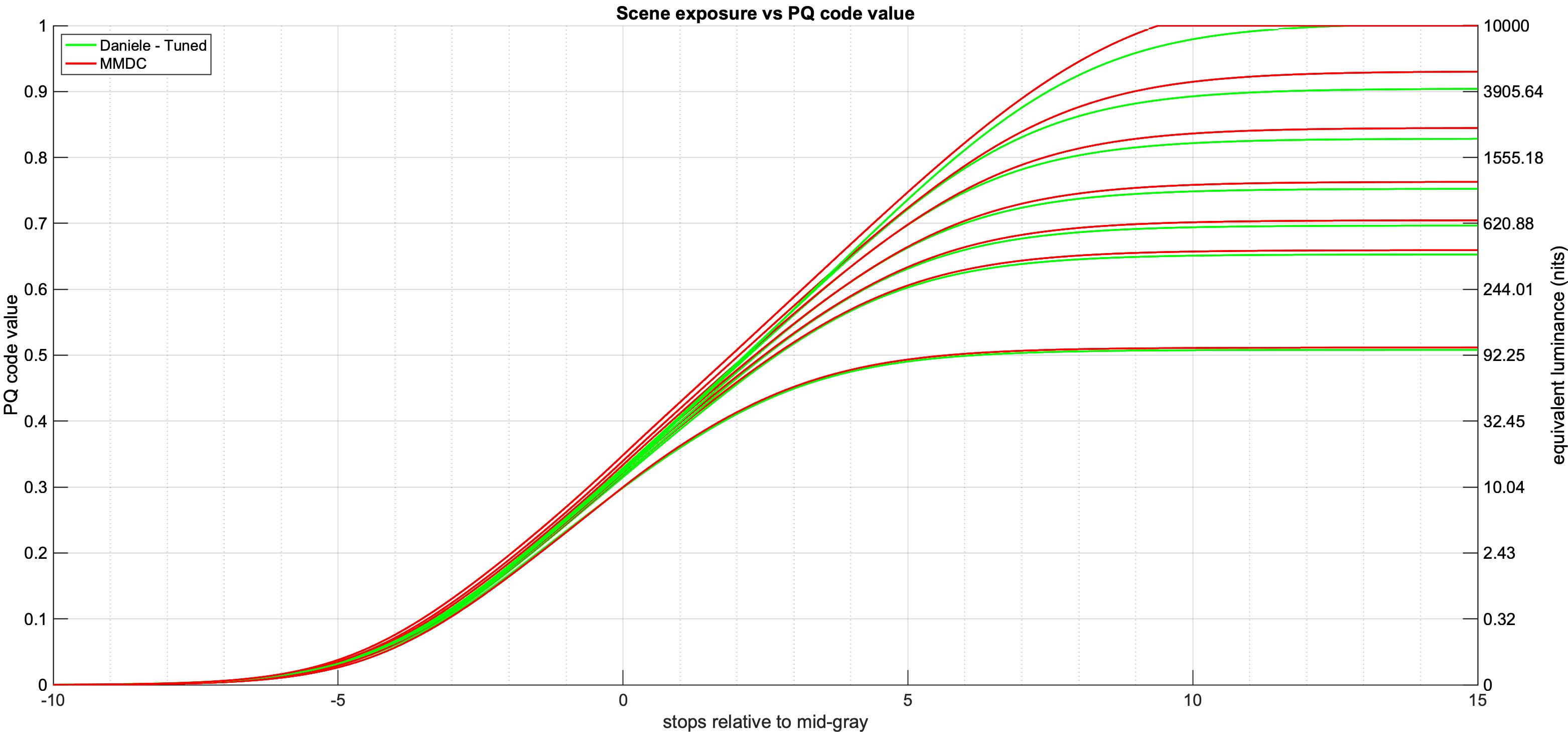
There seems to be a bit of confusion about the parameterization of the tone scale curve.
I made a pedagogical version with some helper lines, also I have changed the parameter space so it might become a bit clearer.
Also, it drove me mad that the Y-axis was not logarithmic while the x-axis was. So changed that as well. Now it should be log-log:
A short description:
N_r defines what nit level 1.0 in the linear light output axis means.
So if N_r is 100: The resulting output scale is:
1.0 = 100 nits
2.0 = 200 nits
10.0 = 1000 nits
100.0 = 10000 nits
If you want an output where the linear light output domain equals the nit scale set N_r = 1.0.
That would result in:
1.0 = 1 nits
2.0 = 2 nits
10.0 = 10 nits
100.0 = 100 nits
etc…
Ultimately, it does not matter if the EOTF encoding is scaled accordingly.
Be careful because the plumped Log Axis encoding in Desmos messes up all this.
N_r is not important for this discussion, so I moved it to the bottom
N
defines the display referred tone mapping target (relative to N_r), I added a list of a few values so we can see SDR and HDR at once.
r
defines which scene referred value should hit the display referred tone mapping target.
I added a little expression to make it be driven by n
I have replaced w with two parameters c for center and c_d for center display referred.
In addition, I added w_g to allow you to scale c_d when the Peak Luminance changes.
(Spoiler for the math nerds, the calculations of c_d are not exact. But the error is very small if r is very big, and the error plays into our direction ![]() ).
).