What follows is hopefully a useful explanation of how the chroma compression works and behaves (in CAM DRT v035 as it stands). The purpose is to spread knowledge of chroma compression implementation and by visualizing its behavior hopefully inspire new ideas how to simplify and improve it.
(In some cases I will interject with extra comments about older chroma compression implementations in italic, for extra information.)
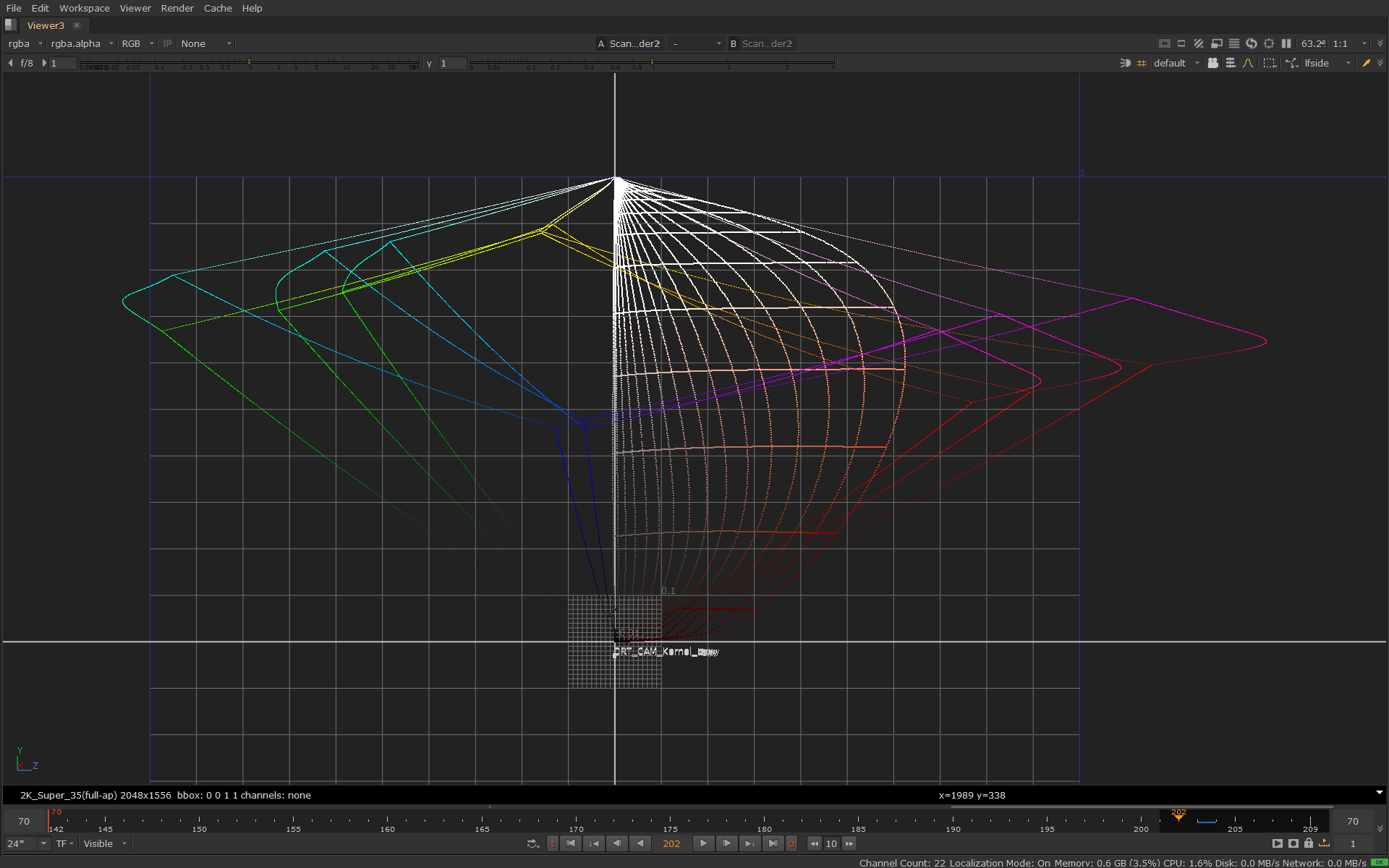
The primary input image used in the examples is an HSV sweep with 0.5 saturation:

Note that the saturation is set only to 0.5. In other words the input is not highly saturated. This is relevant because chroma compression mostly affects only the interior of the gamut.
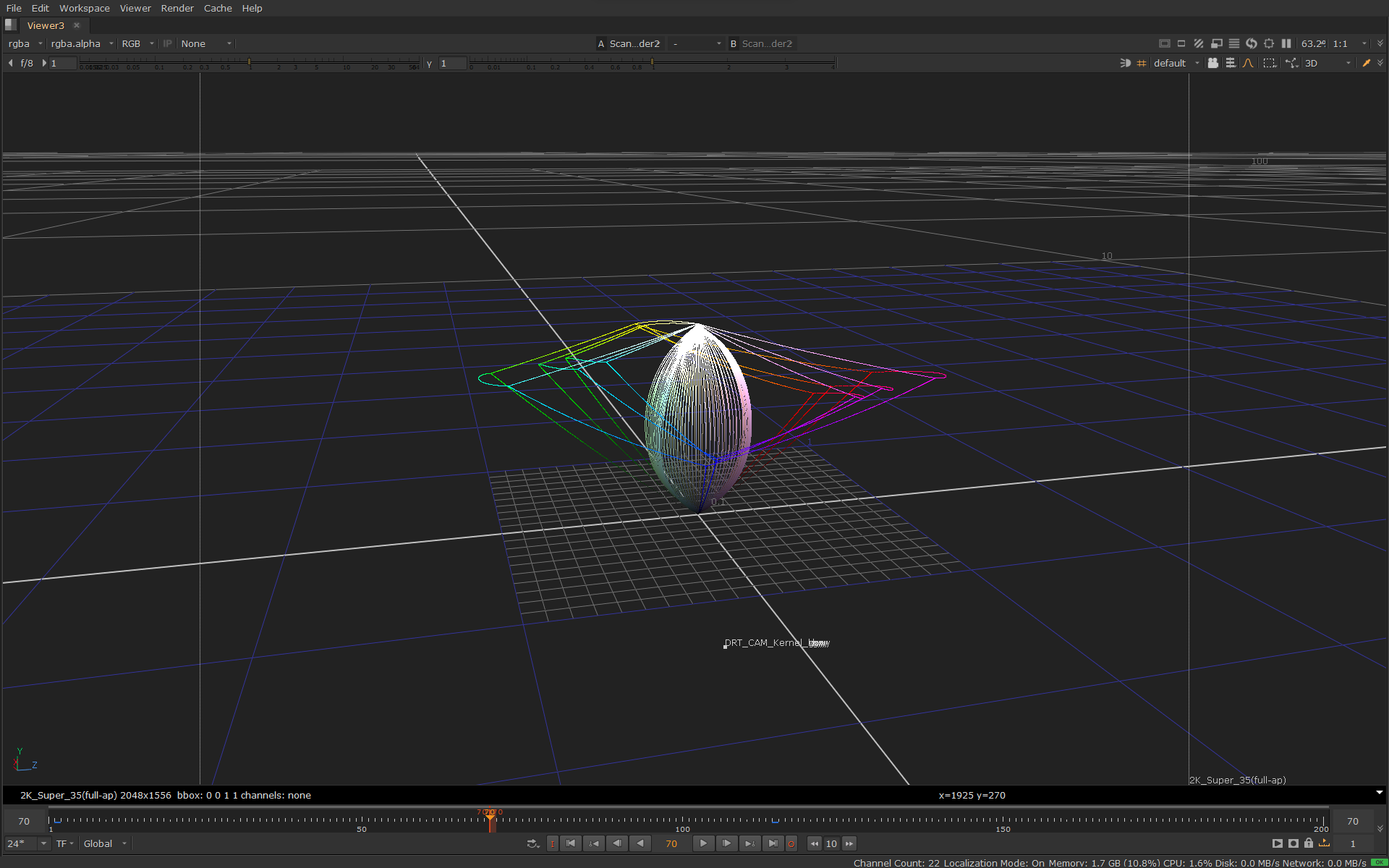
Here is the same image in 3D in JMh space going through the whole transform:
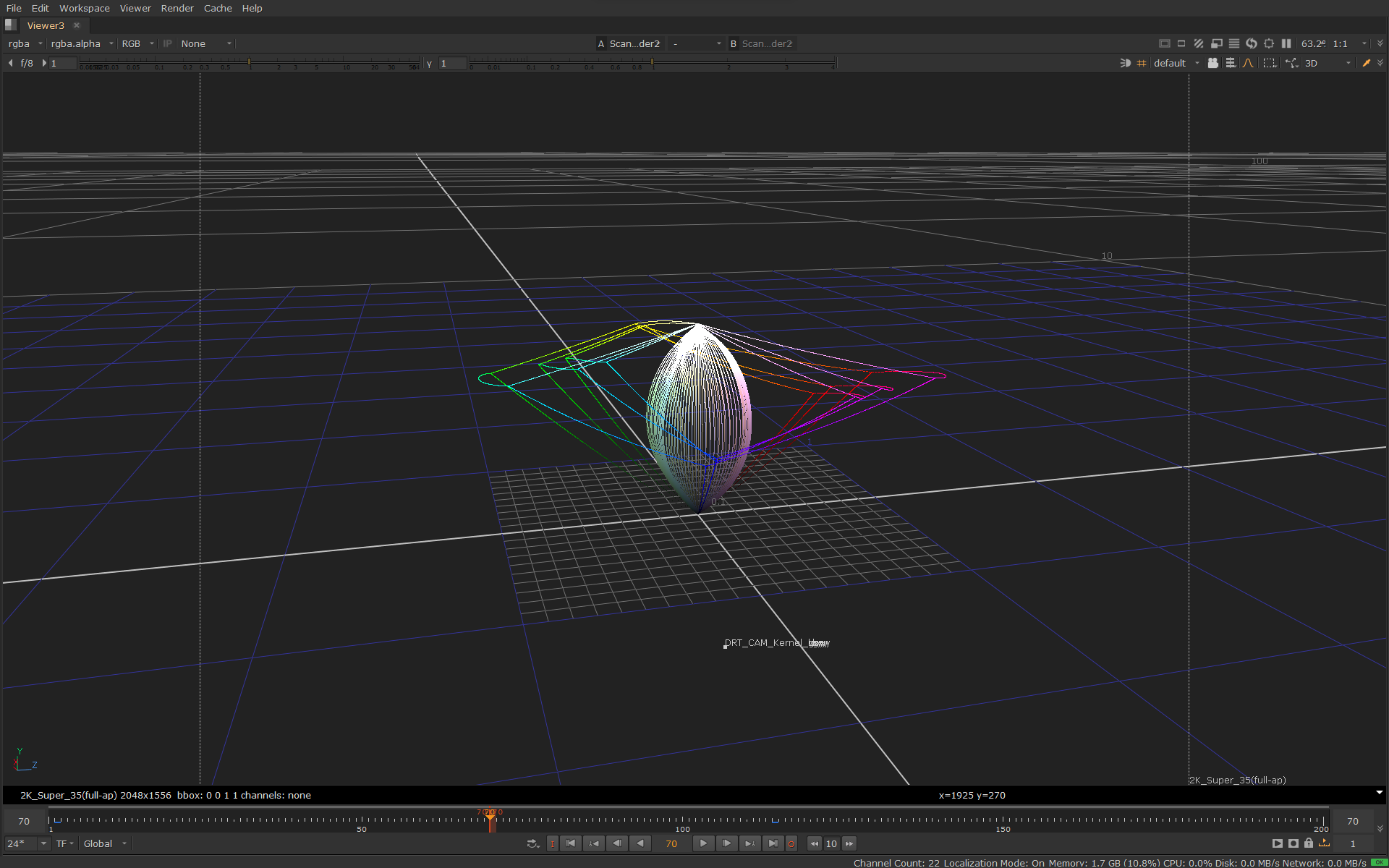
The lines in the image above also shows the JMh gamut boundaries for Rec.709, P3 and Rec.2020.
Chroma Compression
The chroma compression has three main steps:
- Scaling or normalization
- In-gamut compression or saturation roll-off or path-to-white
- Saturation boost
The purpose of these steps, with the tonescale, is to create the basic “photographic rendering”, aka. the “look” for the base transform. In practice it defines the rate-of-change for colorfulness over the brightness and colorfulness axes. I also strongly believe that better this step is and better it behaves, easier it is to color grade with the base transform.
For this post I made a modified version of CAM DRT v035 where I can toggle these three steps on and off:

The first checkbox will enable/disable the entire chroma compression. When it (“apply chroma compression”) alone is checked and others are unchecked, it applies only the scaling step. The other steps can then be added one by one.
Scaling
The purpose of this step is to bring the scene M (from JMh) values to similar range as J after tonescale has been applied to J. In simplified form, this is done by multiplying M by tonescaledJ / J:
M * (J_t/J)
In reality, though, there is an additional model on top of this for SDR/HDR appearance match. The problem of using just tonescaledJ for scaling is that the tonescales are different for each peak luminance. And, not just the peak is different (obviously), but the entire curve from shadows up, middle gray, etc. is different. This will create a visible saturation mismatch for the bulk of the image in SDR and HDR. The trick is to get the different tonescales closer to each other, except for the peak, so that the scaling ends up doing similar thing for the bulk of the image.
In v035 the full scaling algorithm to achieve this is as follows:
M*(J_t^p/J)*(1-K * c_t + 0.25)
Where the parameters are as follows:
p=0.935
K=4.4 - m_0 * 0.007
m_0 is a parameter from Daniele tonescale
c_t is a parameter from Daniele tonescale
Here’s Desmos graph to demonstrate this for different peak luminances. The parameters were derived simply by trial and error with the knowledge that for best SDR/HDR match the goal is to get the curves as close to each other as possible in shadows and at middle gray.
(if you want to see the difference between the simple scaling vs the full algorithm in SDR/HDR, CAM DRT v032 used the simplified scaling. The old chroma compression (last used in CAM DRT v031) had an engineered scaling curve and wasn’t based directly on the exact tonescale.)
In summary, the purpose of the scaling step is to scale the M to a more manageable scale, and to get the overall saturation level to match between different peak luminances, which otherwise would not.
Here’s the input image in JMh space before and after the scaling step:
before scaling (shows scene M values as is (with tonescale)):
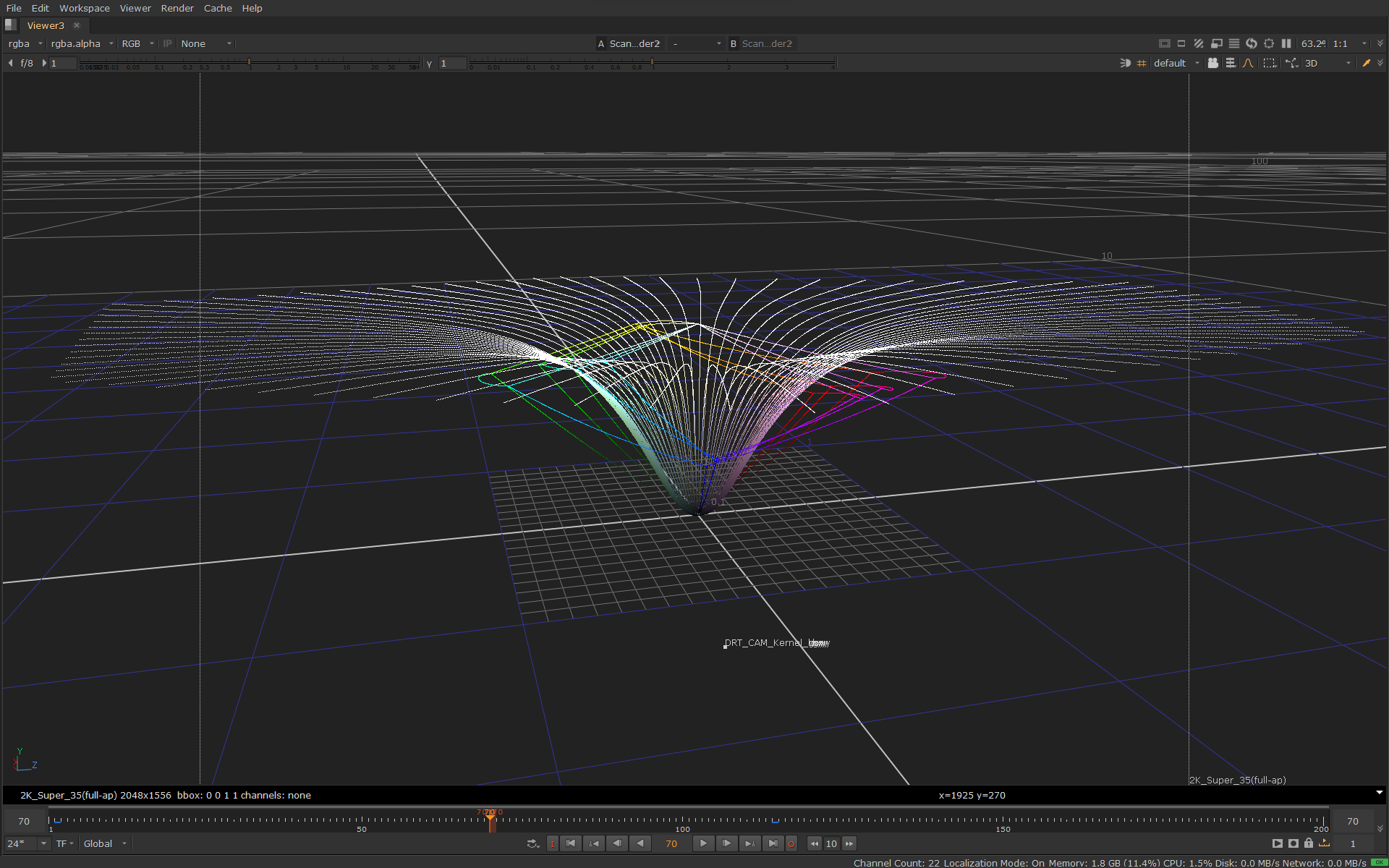
after scaling:

Note that while M has been pulled in, there is no roll-off for highlights, yet. The hue lines keep increasing colorfulness (as the model does as J goes higher) and would clip at the gamut boundary (image doesn’t show the clipping).
Here’s a slightly different input with varying chroma, with a side view of one particular hue slice, before and after scaling:


In-gamut compression
This compression step mostly creates the saturation roll-off, but it crucially takes the level of colorfulness into account as well when it changes the colorfulness. In other words, colors that are closer to achromatic are compressed different amount than colors that are far out there in the distance. The purpose of this is to both protect purer colors from being overly compressed and to create room for the bulk of the colors inside the gamut. Furthemore, it compresses brighter colors more than darker colors, creating the saturation roll-off for highlights.
Now, this step maybe deserves a post of its own to get into the nitty-gritty details. Suffice to say that the compression happens in the following steps:
- Normalize M to a compression space cusp (M / cuspM). This makes the compression also hue dependent.
- Compress the brightness/colorfulness range using this algorithm. The compression (as touched on above) is driven by the tonescaled J and the parameters can be adjusted from the DRT GUI. The compression increases for higher J but reduces for higher M.
- Denormalize M (M * cuspM)
(This algorithm was introduced in CAM DRT v032. The compression in older versions worked mostly the same way, except there was no normalization to any particular compression space and instead there was a hue dependent curve. The algorithm was different, but essentially resulting into the same thing and being driven by the tonescaled J. Before chroma compression existed the (Z)CAM DRT had a “highlight desat” mode, which was doing a global desaturation of values above middle gray. Problem with that was it was desaturating also pure colors and wasn’t hue dependent.)
Here is the result of this compression step before and after:
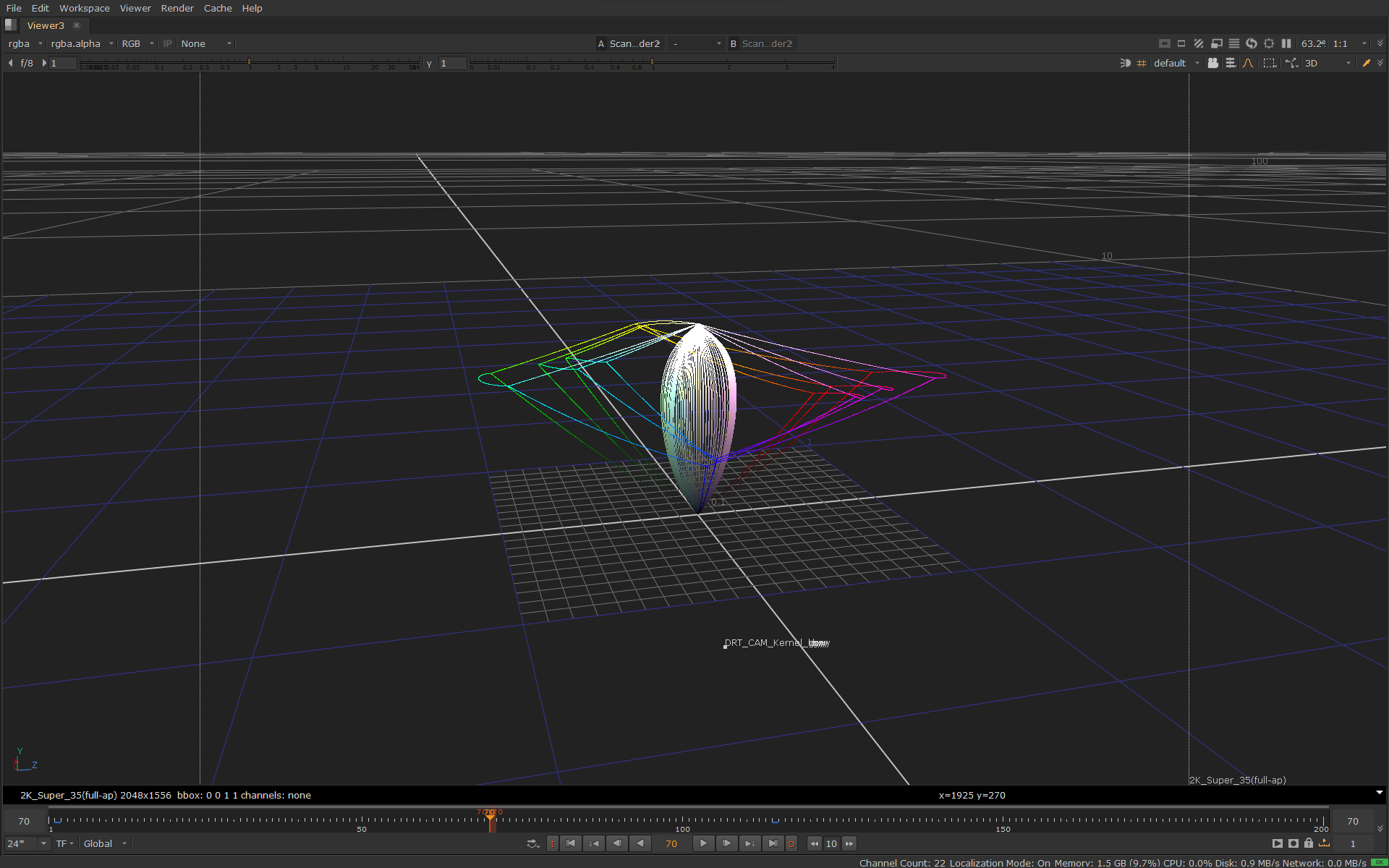
It’s now obvious looking at the image that highlights now have a saturation roll-off to white (or call it path-to-white). What is not so obvious from this image is how the compression affected different colorfulness levels. That’s more obvious when looking at one particular hue slice from the side with varying chroma, before and after:
Here is also a video of this compression in effect for varying chroma. Notice how the compression is significantly reduced as colorfulness increases, and vice versa:
This compression is also the reason why there is hardly any difference between full chroma compression and the simple scaling for highly saturated colors; this compression step mostly leaves those colors untouched.
Saturation boost
After the first two steps the colors in the image are looking quite dull. This is improved by boosting saturation mainly for darker colors and mid tones. The saturation boost is a simple global adjustment driven by the tonescaledJ.
M * (sat + 1.0 * (1.0 - normalizedJ_t))
An additional step to this is the desaturation of the noise floor, which is a smooth lerp to 0.01 M at 0 J. Its effect isn’t really visible unless you lift the shadows.
Here is the final result of chroma compression before and after applying the saturation boost (but before gamut mapping):
And here it is with also gamut mapping applied (ie. the full transform):
Pictures
I’m not sure how useful it is to look at the intermediate steps of the chroma compression as images, but I thought I would show a few, skin tones in particular, as the colorfulness rate-of-change has a very large impact on skin tone rendering.
Sorry for not labeling the images properly.
- Top left box is just the scaling step
- Top right box is with scaling + in-gamut compression step
- Bottom left box is with scaling + in-gamut compression + saturation boost
- Bottom right box is the full transform with chroma compression and gamut mapping






Known Problems
One known problem with the current implementation is the global saturation boost step which will push all colors outward, including already pure colors. The compression first went its way to protect the pure colors from over compression only then to push them even more saturated. The blue in the blue bar image, for example, will get more saturated as a result.
Following image is the Dominant Wavelength ramp image, and shows only those colors that were expanded beyond the original scene M values as a result of the saturation boost. Other colors not shown were under the original scene M values.

And here as an image with the yellow band being the overly boosted colors in this particular image:

This obviously needs fixing in some way. It’s ok to boost the saturation beyond the original scene M values inside the gamut but it’s not ok to do it for these highly saturated colors that would be out of gamut any way.
I guess another known problem is the overall complexity. I must believe there is a simpler way to achieve same level of control for the compression of M and still be invertible.