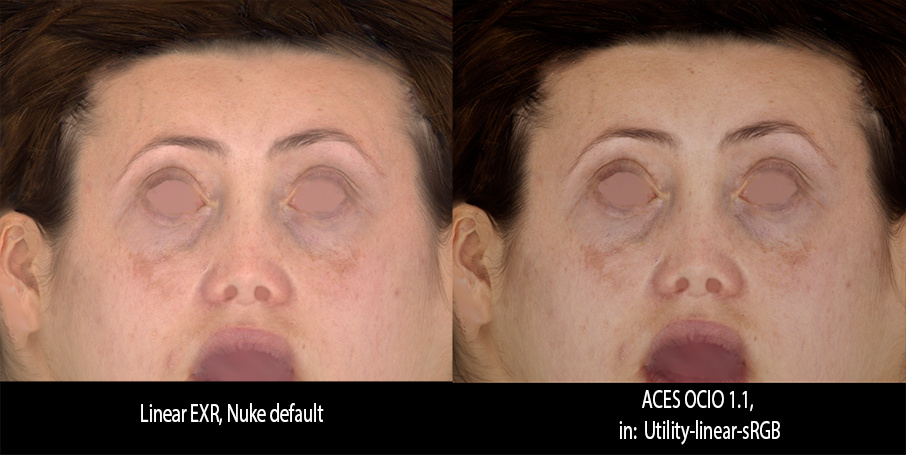
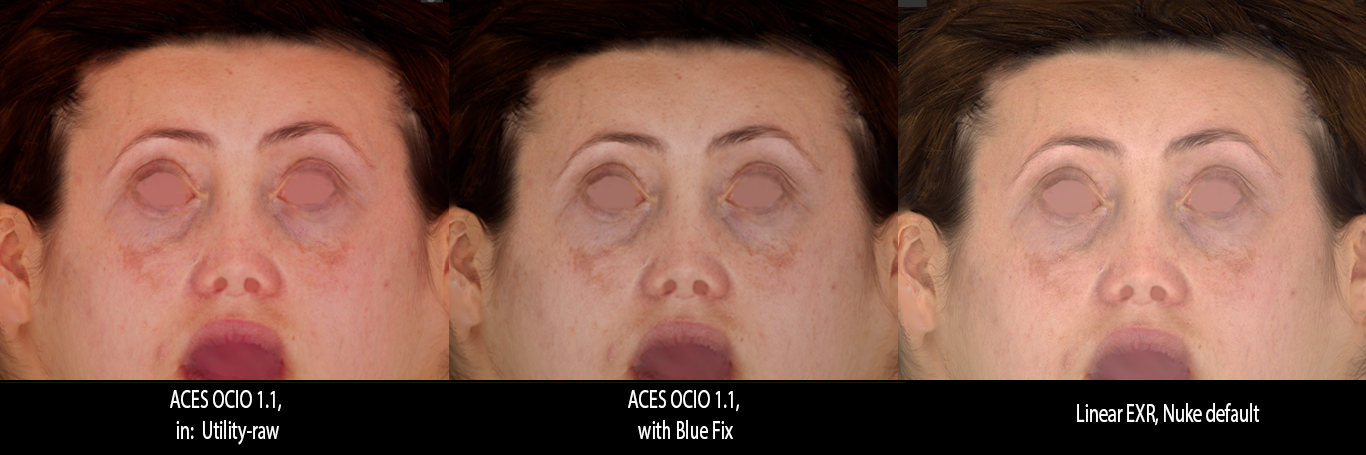
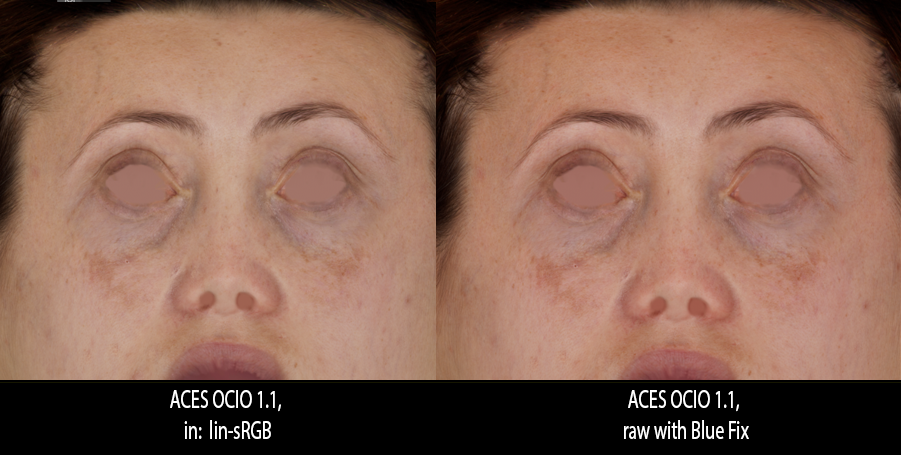
Well, hard to assume otherwise given the OP 
The issue is that any faithful translation obtained by applying some sort of Inverse View Transform stops as soon as shading more complex than a Emissive or Lambertian BRDF and lighting more complex than a white skylight are involved.
Ultimately, what I would like to know is what your renders should be faithful to? To an sRGB image rendered without a S-Curve?
If that is the case, why are you using the RRT or even ACES? It is like trying to force a cube into a cylinder and you will always be fighting the system because you are using it in a way it is not designed for.
Let me quote TB-2014-004 for reference:
The Academy Color Encoding Specification (ACES) defines a digital color image encoding appropriate for both photographed and computer-generated images. […] In the flow of image data from scene capture to theatrical presentation, ACES data encode imagery in a form suitable for creative manipulation. […]
Based on the definition of the ACES virtual RGB primaries, and on the color matching functions of the CIE 1931 Standard Colorimetric Observer, ACES derives an ideal recording device against which actual recording devices’ behavior can be compared: the Reference Input Capture Device (RICD). As an ideal device, the RICD would be capable of distinguishing and recording all visible colors, and of capturing a luminance range exceeding that of any contemporary or anticipated physical camera. The RICD’s purpose is to provide a documented, unambiguous, fixed relationship between scene colors and encoded RGB values. When a real camera records a physical scene, or a virtual camera (i.e. a CGI rendering program) creates an image of a virtual scene, an Input Device Transform (IDT) converts the resulting image data into the ACES RGB relative exposure values the RICD would have recorded of that same subject matter.
From this introduction, we have gleaned that the system is designed to manipulate physical quantities, whether they are generated from the real world or via CG rendering. Quoting again:
ACES images are not directly viewable for final image evaluation, much as film negative or files containing images encoded as printing density are not directly viewable as final images. As an intermediate image representation, ACES images can be examined directly for identification of image orientation, cropping region or sequencing; or examination of the amount of shadow or highlight detail captured; or comparison with other directly viewed ACES images. Such direct viewing cannot be used for final color evaluation. Instead, a Reference Rendering Transform (RRT) and a selected Output Device Transform (ODT) are used to produce a viewable image when that image is presented on the selected output device.
Then we learn that a View Transform, i.e. the RRT is required to view ACES imagery. Quoting again:
Practical conversion of photographic or synthetic exposures to ACES RGB relative exposure values requires procedures for characterizing the color response of a real or virtual image capture system.
i.e processing as-per-the-book!  Which the Emily dataset you linked should be close to. Quoting again:
Which the Emily dataset you linked should be close to. Quoting again:
Encoding in ACES does not obsolete creative judgment; rather, it facilitates it.
In your case and from what you have been describing the past weeks, I don’t think it really does, you are really twisting the arm of the system.
That being said, the various workflows you are talking about are contextually fine. My worry, and because you mentioned you are teaching to students in other threads, is that they become standard practice. It would be counter-productive for your students.
The paragraphs quoted above are the most important aspects to understand what the system was designed to accomplish. This is what everybody should have in mind when using ACES, subsequently, if required to deviate for practical reason, then feel free to do it but always keep in mind the purpose of the system.
To reinstate it, the question to ask yourself is whether ACES is the good tool for your cartoon renders.
Cheers,
Thomas