Really fascinating stuff! Would you mind posting a link to the EXR image from @ChrisBrejon so I can try it out in your Nuke scripts?
Interesting, what is the reasoning?
You would model flare in scene-referred domain differently. Also flare in scene-referred state is a “per shot” adjustment. A global display glare/flare is a fixed operation per viewing condition typically (also you could do better with more complex image dependent models). Also that particular form is quite display driven because it does not physically correctly models flare but maintains shadow information. So we rate detail over accuracy.
3 Likes
Given I brought up the point in the last meeting, and given several birdies have asked that I post the question here, I figured I’d bump up the recent revival of this thread.
First, a salient quote from Jed Smith:
Even in this valuable post of Jed’s there is an implicit assumption of what “tone” is. These sorts of a priori assumptions will doom any attempt at modelling. What is this particular version of “tone”?
Further down this ladder, I’d like to highlight a quote that @Alexander_Forsythe made in Slack, when I, being a buffoon, kept repeating the question “What is tone?”
I’ll have to look in the usual places to see if it’s already defined but I’ll take a shot off the top of my head. Take with a grain of salt.
Tone mapping: the intentional modification of the relationship between relative scene luminance values and display luminance values usually intended to compensate for limitations in minimum and maximum achievable luminance levels of a particular display, perceptual effects associated with viewing environment differences between the scene and the reproduction, and preferential image reproduction characteristics. Tone mapping may be achieved through a variety of means but is quantified by its net effect on relationship between relative scene luminance values and display luminance values.
That is, if this definition of “tone” is acceptable, does anything that uses the term “tone” (EG: “tone mapping”, “Simple Stage Tone Scale”) actually perform the implied mechanic? Does a “tone map” actually “map tones”?
None of the functional formula examples thus far map “tones” according to this definition. Either this should be considered a show stopper, or further interrogation is required.
Given the above, if we revisit this issue cited by Forsythe, we can ask some further questions…
A few questions:
- Is there a conflation between chroma and tone in some of these nuanced discussions?
- If there is, how are the two related?
- If there is a relationship, can anyone answer, in a clear statement, what “Film magic” did regarding tone, and this nuanced interaction?
- Given tone’s importance here, and specifically the “shape” of classical film negative to print to print through resultant density, is everyone confident in the evaluation of film density plots being 100% correlated to emission of light from a fixed chromaticity display?
- If not, is it feasible to consider how film density plots correlate to light transmission?
- Further along, is the correlation between film dye density and transmission related to discussions of chroma, as per Forsythe’s question?
TL;DR: Perhaps we should be avoiding discussions of “bleaching” or “desaturation” and interrogate precisely what film was doing, and more importantly, what underlying perceptual (?) mechanic was it facilitating that makes the rendition of imagery successful in the medium, and how is it related to “tonality”? With respect to gamut mapping “tones”, the underlying definitions and potential mechanics should be clearly identified to evaluate whether or not any mechanic is actually doing what it purports to achieve?
A while back @Alexander_Forsythe suggested it would be wise to include a discussion of a Jone’s Diagram such as the following. It seems related to this discussion, and why the “s” curve is even a part of the discussion around “tonality”.

Image from here.
Apologies to anyone who feels this is pedantry. From my dumbass vantage, I cannot see how we can solve any design problem without firmly locating what the problem is, in clear and precise terms. Even given the large amount of discussion on this subject thus far, I’m unconvinced we have definitions clear enough to write any algorithm for.
4 Likes
Ok, so we are talking about display-flare then, might be worth clarifying for people casually reading the thread. As you say it is also very much viewing conditions dependent, how do you quantify it?
Cheers,
Thomas
As I was re-reading that, I could not help but think about the DRT impact on Lookdev. You are effectively doing shading work and adjusting specular response here! ![]()
1 Like
Could we aim at something like the Filmic from Troy ? With several “Looks” for contrast ?
Five contrast base looks for use with the Filmic Log Encoding Base. All map middle grey 0.18 to 0.5 display referred. Each has a smooth roll off on the shoulder and toe. They include :
- Very High Contrast.
- High Contrast.
- Medium High Contrast.
- Base Contrast. Similar to the sRGB contrast range, with a smoother toe.
- Medium Low Contrast.
- Low Contrast.
- Very Low Contrast.
Chris
Name a single processing that doesn’t? Default per channel tosses in a grade that varies per colour space, per display, but few seem to comment on that?
Perhaps this is indicative of an entire thought process that isn’t extending from first principles…
1 Like
Encode for display and adjust exposure… ![]()
That feels like the right track!
So why doesn’t any example provided anywhere on this site aim at that ground truth?
Happy to take stab at helping us speak a common language.
I think the term “Tone Mapping” and “Tone Mapping Operator” largely comes from the computer graphics side of the coin whereas in historical terminology the topic as a whole is referred to as “Tone Reproduction” and the “Tone Reproduction Curve”. Where the former is largely used in the context of Image to Image “mapping”: HDR EXR to SDR JPEG for example. Whereas the latter definition is largely used in reference to Scene to Image “reproduction”, where both the Scene and resulting Image have “Tone” or “Tone Scale”, but the objective quality metric is the “reproduction” of “Tone” from one domain to another.
I’m sure you could point out many examples of each term used in an alternative manner, but that’s generally how I would look at it.
The term “Tone” its self is not scientific. There is a reason this does not show up in any color appearance models, nor the CIE Vocabulary (e-ILV | CIE), it is exclusive to the media/imaging community.
I would place the origin of this concept in our community/domain first to Hurter and Driffield and their pioneering work on sensitometry, and later to L.A. Jones for his investigation of Tone Reproduction across the full imaging chain. I’ll leave it to the reader to explore the works of these individuals.
Specifically with respect to Jones and his 1920 “On the theory of tone reproduction, with a graphic method for the solution of problems” (Redirecting). He defines the problem space as “…the extent to which it is possible by the photographic process to produce a pictorial representation of an object which will, when viewed, excite in the mind of the observer the same subjective impression as that produced by the image formed on the the retina when the object its self is observed…”. He then goes on to say “The proper reproduction of brightness and brightness differences…is of preeminent importance…”. Brightness does have a definition in the color science community, to quote Fairchild “…visual sensation according to which an area appears to emit more or less light”. Jones utilises an explicit simplifying assumption, which I believe is largely implicit in most discussions of “Tone Curves” or “Tone Mapping Operators”. That is, that all objects in the scene are non-selective, and the imaging forming mechanism is also non-selective. Non-selective meaning it absorbs/reflects all incident electromagnetic energy equally. He uses this simplification because “under such conditions values of visual brightness are directly proportional to photographic brightness.”
There are of course deviations in perceived brightness of the scene and reproduction with respect to many factors, reflective selectivity being one of them, that breaks the simplifying assumption. However, the simplifying assumption is used both for convenience, and to focus analysis on the primary principal component of Image Reproduction, or more specifically Tone Reproduction. With the added assumption that the dominant illuminant in the scene and the image viewing environment is the adopted illuminant, you could call this problem space more specially “Neutral Scale Tone Reproduction”.
All that to say, “Tone Reproduction” is largely focused on the reproduction of Scene brightness (and relative brightness) of non-selective objects onto a non-selective Image medium.
I would argue that the implicit assumption (of neutrality/ non-selectivity) is generally held by most that discuss the topic, and that rather the reference to “Film” is significantly more vague and less defined than “Tone”. “Film” being an incredibly varied and complex quantum mechanical piece of technology with over a century’s worth of innumerable manifestations. “Film” has done many things, from image my teeth at the dentist, help prove Einstein’s general theory of relativity, to being scratched with a knife by an animator and projected.
We would do well to define “Film” in the same rigour as “Tone”, because I don’t believe the objective here is to emulate a single batch of a single brand of photo-chemical film processed on a certain day.
11 Likes
Sean, this whole post is fantastic. Thank you.
These two quotations from the post are extremely useful, and build on top of what @Alexander_Forsythe and a few others have been fleshing out, with respect to “tonality”:
It strikes me that perhaps Fairchild’s definition would need extending for usage with imagery output contexts? Specifically, it would seem that we would need to define “brightness” relative to the light transport data in the buffer in question?
Could not agree more. Perhaps chasing “Film” altogether, and instead interrogate the fundamentals that worked to deliver this “brightness” facet above, would be potentially more forward looking given the radically different nature of constant chromaticity emissive / reflective display devices?
Any such algorithm would need to be based on such a mechanic. If we examine the existing chosen mechanics historically:
Question #1: Is there a useful colour science metric here that we could use as an entry point to evaluate “brightness” relative to the light data present in the working space?
Further along, assuming we can identify a single entry point to trial, we can retroactively test the fitness of existing approaches to see if they pass this metric:
Question #2: Do per channel mechanics facilitate a “…visual sensation according to which an area appears to emit more or less light” according to this metric?
Question #3: Do the “hue preserving” power norms facilitate a “…visual sensation according to which an area appears to emit more or less light” according to this metric?
Question #4: Does any emission-centric mechanics facilitate a “…visual sensation according to which an area appears to emit more or less light” according to this metric?
Thanks again for the terrific quotations and thoughts. I am very curious if anyone has any suggestions on at least a starting point metric we could collectively use to address Question #1. There will likely be faults and problems, but we would at least need to start somewhere…
1 Like
Thanks for that great post @SeanCooper
I looked no longer than last week if it was formally defined by the CIE and indeed, I could not find it either. Doing so however I came across those that were of interest:
film rendering transform
mapping of image data representing measurements of a photographic negative to output-referred image data representing the colour space coordinates of the elements of a reproduction
film unrendering transform
mapping of image data representing measurements of a photographic negative to scene-referred image data representing estimates of the colour space coordinates of the elements of the original scene
colour re-rendering
mapping of picture-referred colour image data appropriate for one specified real or virtual imaging medium and viewing conditions to picture-referred colour image data appropriate for a different real or virtual imaging medium and/or viewing conditions
Note 1 to entry: Colour re-rendering generally consists of one or more of the following: compensating for differences in the viewing conditions, compensating for differences in the dynamic range and/or colour gamut of the imaging media, and applying preference adjustments.
colour rendering, <of a light source>
effect of an illuminant on the perceived colour of objects by conscious or subconscious comparison with their perceived colour under a reference illuminant
Pretty much all the CAMs have a correlate for it, shouldn’t we look there?
Brightness (Q) is an “attribute of a visual perception according to which an area appears to emit, or reflect, more or less light” [21]. It is an open–end scale with origin as pure black or complete darkness. It is an absolute scale according to the illumination condition i.e., an increase of brightness of an object when the illuminance of light is increased. This is a visual phenomenon known as Stevens effect [26].
Cheers,
Thomas
1 Like
Most CAMs I have seen have a fixed adaptation point which makes them not terribly well suited for moving imagery? Are there more fundamental mechanics we could start with?
Great discussions about theory @Troy_James_Sobotka and @SeanCooper, this is great and I hope it continues.
I will now interject with a bunch of boring math. Boring but useful, hopefully.
Musings
I spent a while investigating approaches. Handling intersection constraints for the display-referred “toe” flare model is tricky. After a couple of weeks working on the problem, and some help with the math from my physics major friend, I’m pretty confident that there is no closed-form solution for a grey and white intersection constraint including the toe function as Daniele proposed it. (Happy to be proven wrong here by someone smarter!).
I am also wondering if it is the correct thinking for the toe to have an intersection constraint at grey. Because when it does, contrast is changed when you boost the toe value. Might be an unwanted behavior. Maybe it should be treated more as a surround compensation power function, where the mid-grey point is allowed to shift?
Siragusano Variations
So far I’ve come up with 3 potentially useable variations of @daniele’s model.
-
The first is super simple. Just the compression with contrast, solved for grey and white. It could be used as a module if another model was desired for surround or flare compensation.
Tonemap_Siragusano01.nk (1.3 KB) -
The second is a lot more complex. I managed to solve the toe intersection constraint through grey by solving in terms of a second power function applied on the output of the toe function, which is also used for unconstrained surround compensation. The curve gets a bit weird at higher t_0 values, but seems to work okay at more common low values, and also seems to increase contrast a bit less than the alternative of solving in terms of s_0 (which also does not seem to be possible using analytical approaches).
I dislike the complexity required to get such a mediocre result.
Tonemap_Siragusano02.nk (2.0 KB) -
The third is basically the same as the first version I posted, which uses the intersection constraints from the first simple version above, and decouples the toe compression from the grey intersection constraint entirely, while pivoting at r_1, so that boosting toe compression does not lower the peak white luminance.
Tonemap_Siragusano03.nk (2.0 KB)
There is a summary and some more verbose info in this notebook.
Piecewise Hyperbolic
I got a bit fixated on the idea of having a linear section below the grey intersection point. In the testing I have done I like the way it looks in images, as I mentioned in my previous post. Unfortunately the hyperbolic compression curve formulation I knew from the gamut mapping vwg got super complex trying to solve for the intersection constraints.
So I decided to start from scratch and build my own Hyperbolic compression function. This endeavor being relevant to my ongoing fascination with conic sections..
So I started with f\left(x\right)=-\frac{a}{x} and ended up with a relatively simple formulation that works well. Here are a few variations:
-
The first is just a simple compression function with contrast, solved for grey and white intersection constraints.
Tonemap_PiecewiseHyperbolic01.nk (1.6 KB) -
The second is more complex but includes all bells and whistles. Toe solved in terms of s_0 and s_1 and unconstrained surround compensation power function.
Tonemap_PiecewiseHyperbolic02.nk (2.4 KB) -
The third uses the same “decoupled toe” approach as before, which is a lot simpler and maybe has more desireable behavior. Need to do more testing.
Tonemap_PiecewiseHyperbolic03.nk (2.3 KB)
There is a more verbose derivation of my custom hyperbolic compression function and some more details in this notebook.
2 Likes
After playing around a bit with all of these different variations, I decided that I did not like the behavior of Toe constrained by the grey intersection point. Changing contrast when adjusting toe doesn’t make sense.
I settled on using the piecewise hyperbolic with “decoupled toe and surround”. I played around a bit and roughed in a few presets for
- SDR dark surround
- SDR dim surround
- SDR average surround
- HDR PQ 600 nits
- HDR PQ 1000 nits
- HDR PQ 2000 nits
- HDR PQ 4000 nits
Tonemap_PiecewiseHyperbolic_Presets.nk (4.0 KB)
The behavior and appearance is nice but I don’t like how complex it still is.
I keep going back to @daniele’s original formula, and thought I would give the same exercise a try with his original “minimally constrained” formulation and see how it went. It was actually surprisingly easy to dial in the same behavior, even without being able to specify the precise intersection points. (I did make one modification in order to get the output domain scaled to the right level for PQ output).
Tonemap_PiecewiseHyperbolic_Presets.nk (4.0 KB)
Edit: Woops! I realized looking back at this that I uploaded the wrong nuke script here. Here’s the correct one which contains Daniele’s compression function, as described above.
Tonemap_Siragusano_Presets.nk (2.5 KB)
Which leads me to an observation that I probably should have had before spending a few weeks on the above math exercise: In a scenario where we are building something that has preset parameters for different displays and viewing conditions, is a high level of complexity in the model justified in order to achieve precision of intersection points? What level of precision is necessary here and why?
Edit:
I realized I may not have shared the super simple EOTF / InverseEOTF setup I’ve been using, which may be a necessary counterpart for testing the above tonescale setups, especially with HDR:
ElectroOpticalTransferFunction.nk (5.2 KB)
3 Likes
That’s a very good point, @jedsmith. I don’t believe we are trying to build a fully dynamic, user controllable display transform. So as long as we can find values that create the desired intersections for a set of common targets, and clearly document a methodology for calculating them for other targets, it is probably not necessary to restrict ourselves to an algorithm where the intersections can be solved “on the fly”.
3 Likes
Hi @jedsmith ,
I’m testing your latest tonemaps on some images and wanted to make sure I had things set up correctly. I’m on a standard sRGB monitor, I have the image set to ACES-2065, the Nuke view transform set to Raw, and am using the Display EOTF node from one of your scripts, set to sRGB. Here’s a screenshot of Nuke:
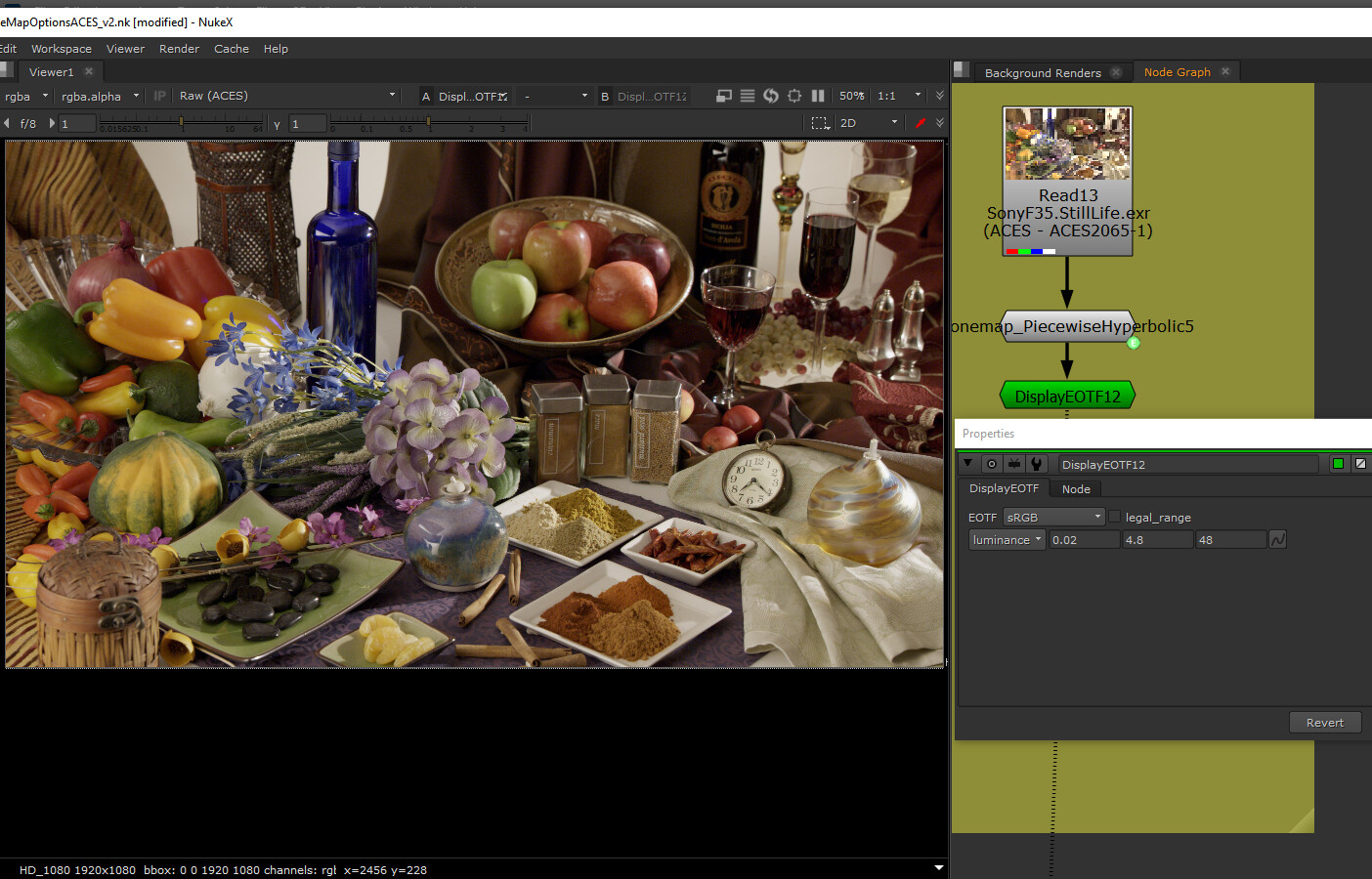
As you can see, this seems to appear somewhat desaturated. On a hunch I added in a ACEScg to sRGB color matrix from one of your earlier Nuke scripts (20190119_tonescales.nk). Here’s a screenshot of Nuke:

{kind=link}
Visually this makes it match the ref image. However, I suspect it’s not quite right, as the matrix is for ACEScg to sRGB and my image is ACES-2065. Here’s the matrix code:
ColorMatrix {
matrix {
{1.705079317 -0.6242337823 -0.08084625006}
{-0.1297003478 1.138468742 -0.008767957799}
{-0.0241663754 -0.1246140897 1.148780584}
}
name ColorMatrix10
label “ACEScg to Rec709”
note_font Helvetica
selected true
xpos 102
ypos -789
}
Apologies if I’m doing this completely wrong here. Happy to be pointed in the right direction.
Hey @Derek !
Thanks for getting your hands dirty. We need more people testing things out!
Modules
The stuff I’m posting in this thread is purely related to the “tonescale” component of the display transform. While important, it is only one component. A potentially incomplete list of different modules we might need:
- Input Conversion - Convert input gamut into the rendering colorspace, in which we will “render” the image from scene-referred to display-referred. The rendering colorspace might be an RGB space or an LMS space, or something else entirely.
- Gamut Mapping - We may want some handling of chromaticities which lie outside of our target output gamut.
- Whitepoint - We may want to creatively change the whitepoint of our output in order to create warmer or cooler colors in our output image regardless of what display device whitepoint we are outputting to.
- Rendering Transform - There are many valid approaches for this. ACES uses a per-channel approach where the tonescale curve is applied directly to the RGB input channels, as you were doing in your above experiments. Since I’m working on a chromaticity-preserving display rendering transform, I’ll outline what might go into that.
- Separate color and grey using some norm.
- Apply some tonescale to grey to convert from scene-referred to display-referred.
- Apply some model for surround compensation and flare copmensation.
- Apply some chroma compression to highlights so that very bright saturated colors are nudged towards the achromatic axis as their luminance increases towards the top of the display gamut volume.
- Display Gamut Conversion - Convert from our rendering colorspace into our display gamut. If you’re looking for a tool do do arbitrary gamut and whitepoint conversions in Nuke you could check out GamutConvert.nk.
- InverseEOTF -We need to apply the inverse of the Electro-Optical Transfer Function that the display will apply to the image before emitting light from your display.
- Clamp - And lastly, maybe we want to clamp the output into a 0-1 range, to simulate what is going to happen when we write the image out into an integer data format.
EOTF
The “DisplayEOTF” gizmo is pretty old technology. It is basically just the Inverse EOTF guts of the Nuke ACES Output Transform implementation I did, ripped out and put in it’s own node. I would recommend that you use the InverseEOTF node in the ElectroOpticalTransferFunction.nk file I posted above instead. It’s a lot simpler.
Nuke Specifics
If you’re using a stock ACES config in Nuke, and your read node’s input colorspace is set to ACES - ACES2065-1 as I see in your screenshot, this is doing a gamut conversion from AP0 to AP1. This makes your “Rendering colorspaces” ACEScg. This is the same as the ACES Output Transforms. The ACEScg → Rec709 matrix is essentially your display gamut conversion. and your DisplayEOTF node is your Inverse EOTF curve.
Hope this big wall of text helps clarify things, or at least brings some new questions that will help in your journey of learning.
2 Likes